 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Spatial-Frequency Visual Prompts and Probabilistic Clusters for Accurate Black-Box Transfer Learning
Aug 15, 2024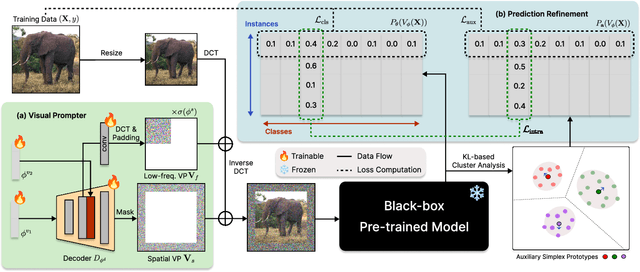
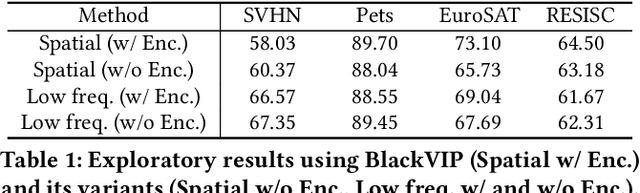


Despite the growing prevalence of black-box pre-trained models (PTMs) such as prediction API services, there remains a significant challenge in directly applying general models to real-world scenarios due to the data distribution gap. Considering a data deficiency and constrained computational resource scenario, this paper proposes a novel parameter-efficient transfer learning framework for vision recognition models in the black-box setting. Our framework incorporates two novel training techniques. First, we align the input space (i.e., image) of PTMs to the target data distribution by generating visual prompts of spatial and frequency domain. Along with the novel spatial-frequency hybrid visual prompter, we design a novel training technique based on probabilistic clusters, which can enhance class separation in the output space (i.e., prediction probabilities). In experiments, our model demonstrates superior performance in a few-shot transfer learning setting across extensive visual recognition datasets, surpassing state-of-the-art baselines. Additionally, we show that the proposed method efficiently reduces computational costs for training and inference phases.
Layout-and-Retouch: A Dual-stage Framework for Improving Diversity in Personalized Image Generation
Jul 13, 2024
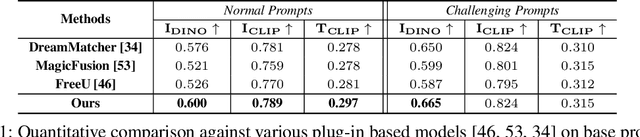
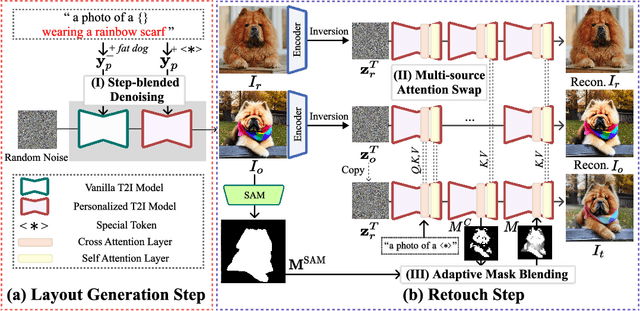
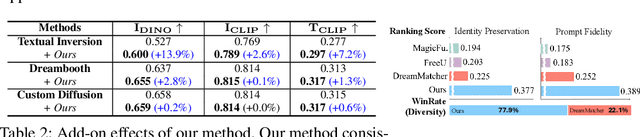
Personalized text-to-image (P-T2I) generation aims to create new, text-guided images featuring the personalized subject with a few reference images. However, balancing the trade-off relationship between prompt fidelity and identity preservation remains a critical challenge. To address the issue, we propose a novel P-T2I method called Layout-and-Retouch, consisting of two stages: 1) layout generation and 2) retouch. In the first stage, our step-blended inference utilizes the inherent sample diversity of vanilla T2I models to produce diversified layout images, while also enhancing prompt fidelity. In the second stage, multi-source attention swapping integrates the context image from the first stage with the reference image, leveraging the structure from the context image and extracting visual features from the reference image. This achieves high prompt fidelity while preserving identity characteristics. Through our extensive experiments, we demonstrate that our method generates a wide variety of images with diverse layouts while maintaining the unique identity features of the personalized objects, even with challenging text prompts. This versatility highlights the potential of our framework to handle complex conditions, significantly enhancing the diversity and applicability of personalized image synthesis.
iDet3D: Towards Efficient Interactive Object Detection for LiDAR Point Clouds
Dec 24, 2023



Accurately annotating multiple 3D objects in LiDAR scenes is laborious and challenging. While a few previous studies have attempted to leverage semi-automatic methods for cost-effective bounding box annotation, such methods have limitations in efficiently handling numerous multi-class objects. To effectively accelerate 3D annotation pipelines, we propose iDet3D, an efficient interactive 3D object detector. Supporting a user-friendly 2D interface, which can ease the cognitive burden of exploring 3D space to provide click interactions, iDet3D enables users to annotate the entire objects in each scene with minimal interactions. Taking the sparse nature of 3D point clouds into account, we design a negative click simulation (NCS) to improve accuracy by reducing false-positive predictions. In addition, iDet3D incorporates two click propagation techniques to take full advantage of user interactions: (1) dense click guidance (DCG) for keeping user-provided information throughout the network and (2) spatial click propagation (SCP) for detecting other instances of the same class based on the user-specified objects. Through our extensive experiments, we present that our method can construct precise annotations in a few clicks, which shows the practicality as an efficient annotation tool for 3D object detection.
Towards Accurate Open-Set Recognition via Background-Class Regularization
Jul 21, 2022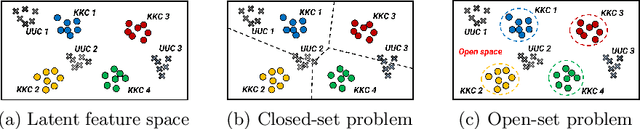
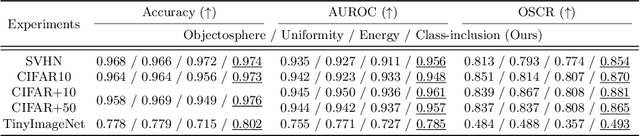
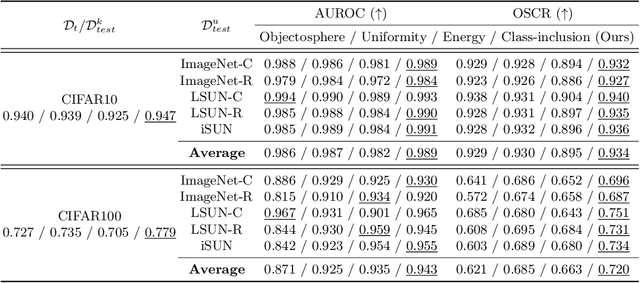
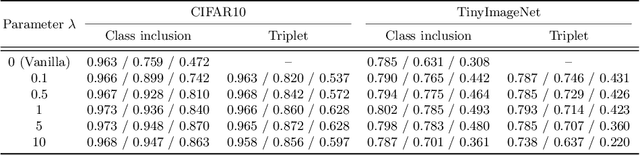
In open-set recognition (OSR), classifiers should be able to reject unknown-class samples while maintaining high closed-set classification accuracy. To effectively solve the OSR problem, previous studies attempted to limit latent feature space and reject data located outside the limited space via offline analyses, e.g., distance-based feature analyses, or complicated network architectures. To conduct OSR via a simple inference process (without offline analyses) in standard classifier architectures, we use distance-based classifiers instead of conventional Softmax classifiers. Afterwards, we design a background-class regularization strategy, which uses background-class data as surrogates of unknown-class ones during training phase. Specifically, we formulate a novel regularization loss suitable for distance-based classifiers, which reserves sufficiently large class-wise latent feature spaces for known classes and forces background-class samples to be located far away from the limited spaces. Through our extensive experiments, we show that the proposed method provides robust OSR results, while maintaining high closed-set classification accuracy.