 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Spatial-Frequency Visual Prompts and Probabilistic Clusters for Accurate Black-Box Transfer Learning
Paper and Code
Aug 15, 2024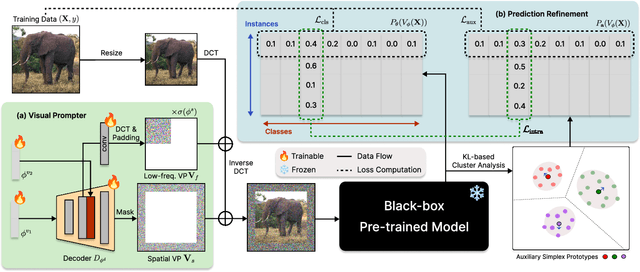
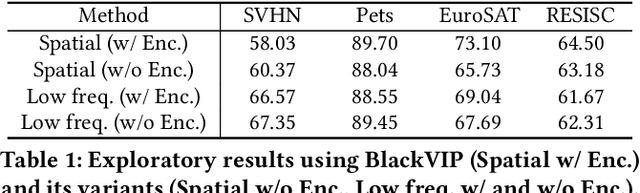


Despite the growing prevalence of black-box pre-trained models (PTMs) such as prediction API services, there remains a significant challenge in directly applying general models to real-world scenarios due to the data distribution gap. Considering a data deficiency and constrained computational resource scenario, this paper proposes a novel parameter-efficient transfer learning framework for vision recognition models in the black-box setting. Our framework incorporates two novel training techniques. First, we align the input space (i.e., image) of PTMs to the target data distribution by generating visual prompts of spatial and frequency domain. Along with the novel spatial-frequency hybrid visual prompter, we design a novel training technique based on probabilistic clusters, which can enhance class separation in the output space (i.e., prediction probabilities). In experiments, our model demonstrates superior performance in a few-shot transfer learning setting across extensive visual recognition datasets, surpassing state-of-the-art baselines. Additionally, we show that the proposed method efficiently reduces computational costs for training and inference phases.