 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout-and-Retouch: A Dual-stage Framework for Improving Diversity in Personalized Image Generation
Paper and Code
Jul 13, 2024
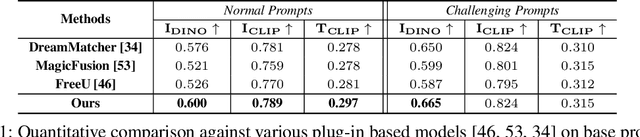
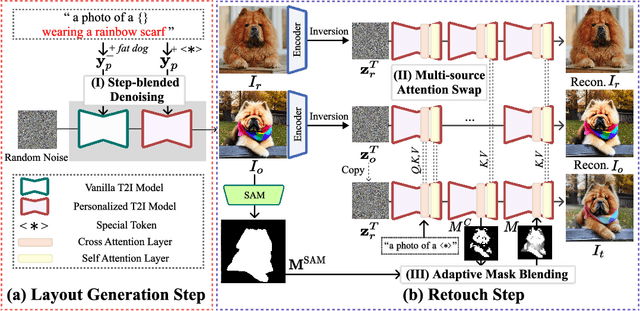
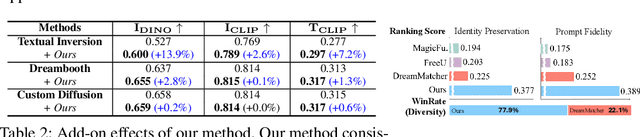
Personalized text-to-image (P-T2I) generation aims to create new, text-guided images featuring the personalized subject with a few reference images. However, balancing the trade-off relationship between prompt fidelity and identity preservation remains a critical challenge. To address the issue, we propose a novel P-T2I method called Layout-and-Retouch, consisting of two stages: 1) layout generation and 2) retouch. In the first stage, our step-blended inference utilizes the inherent sample diversity of vanilla T2I models to produce diversified layout images, while also enhancing prompt fidelity. In the second stage, multi-source attention swapping integrates the context image from the first stage with the reference image, leveraging the structure from the context image and extracting visual features from the reference image. This achieves high prompt fidelity while preserving identity characteristics. Through our extensive experiments, we demonstrate that our method generates a wide variety of images with diverse layouts while maintaining the unique identity features of the personalized objects, even with challenging text prompts. This versatility highlights the potential of our framework to handle complex conditions, significantly enhancing the diversity and applicability of personalized image synthesis.