 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight at My Level: A Unified Multilingual Framework for Proficiency-Aware Text Simplification
Apr 07, 2026Text simplification supports second language (L2) learning by providing comprehensible input, consistent with the Input Hypothesis. However, constructing personalized parallel corpora is costly, while existing large language model (LLM)-based readability control methods rely on pre-labeled sentence corpora and primarily target English. We propose Re-RIGHT, a unified reinforcement learning framework for adaptive multilingual text simplification without parallel corpus supervision. We first show that prompting-based lexical simplification at target proficiency levels (CEFR, JLPT, TOPIK, and HSK) performs poorly at easier levels and for non-English languages, even with state-of-the-art LLMs such as GPT-5.2 and Gemini 2.5. To address this, we collect 43K vocabulary-level data across four languages (English, Japanese, Korean, and Chinese) and train a compact 4B policy model using Re-RIGHT, which integrates three reward modules: vocabulary coverage, semantic preservation, and coherence. Compared to the stronger LLM baselines, Re-RIGHT achieves higher lexical coverage at target proficiency levels while maintaining original meaning and fluency.
Random Is Hard to Beat: Active Selection in online DPO with Modern LLMs
Apr 03, 2026Modern LLMs inherit strong priors from web-scale pretraining, which can limit the headroom of post-training data-selection strategies. While Active Preference Learning (APL) seeks to optimize query efficiency in online Direct Preference Optimization (DPO), the inherent richness of on-policy candidate pools often renders simple Random sampling a surprisingly formidable baseline. We evaluate uncertainty-based APL against Random across harmlessness, helpfulness, and instruction-following settings, utilizing both reward models and LLM-as-a-judge proxies. We find that APL yields negligible improvements in proxy win-rates compared to Random. Crucially, we observe a dissociation where win-rate improves even as general capability -- measured by standard benchmarks -- degrades. APL fails to mitigate this capability collapse or reduce variance significantly better than random sampling. Our findings suggest that in the regime of strong pre-trained priors, the computational overhead of active selection is difficult to justify against the ``cheap diversity'' provided by simple random samples. Our code is available at https://github.com/BootsofLagrangian/random-vs-apl.
vla-eval: A Unified Evaluation Harness for Vision-Language-Action Models
Mar 14, 2026Vision Language Action VLA models are typically evaluated using per benchmark scripts maintained independently by each model repository, leading to duplicated code, dependency conflicts, and underspecified protocols. We present vla eval, an open source evaluation harness that decouples model inference from benchmark execution through a WebSocket msgpack protocol with Docker based environment isolation. Models integrate once by implementing a single predict() method; benchmarks integrate once via a four method interface; the full cross evaluation matrix works automatically. A complete evaluation requires only two commands: vla eval serve and vla eval run. The framework supports 13 simulation benchmarks and six model servers. Parallel evaluation via episode sharding and batch inference achieves a 47x throughput improvement, completing 2000 LIBERO episodes in about 18 minutes. Using this infrastructure, we conduct a reproducibility audit of a published VLA model across three benchmarks, finding that all three closely reproduce published values while uncovering undocumented requirements ambiguous termination semantics and hidden normalization statistics that can silently distort results. We additionally release a VLA leaderboard aggregating 657 published results across 17 benchmarks. Framework, evaluation configs, and all reproduction results are publicly available.
Judging What We Cannot Solve: A Consequence-Based Approach for Oracle-Free Evaluation of Research-Level Math
Feb 06, 2026Recent progress in reasoning models suggests that generating plausible attempts for research-level mathematics may be within reach, but verification remains a bottleneck, consuming scarce expert time. We hypothesize that a meaningful solution should contain enough method-level information that, when applied to a neighborhood of related questions, it should yield better downstream performance than incorrect solutions. Building on this idea, we propose \textbf{Consequence-Based Utility}, an oracle-free evaluator that scores each candidate by testing its value as an in-context exemplar in solving related yet verifiable questions. Our approach is evaluated on an original set of research-level math problems, each paired with one expert-written solution and nine LLM-generated solutions. Notably, Consequence-Based Utility consistently outperforms reward models, generative reward models, and LLM judges on ranking quality. Specifically, for GPT-OSS-120B, it improves Acc@1 from 67.2 to 76.3 and AUC from 71.4 to 79.6, with similarly large AUC gains on GPT-OSS-20B (69.0 to 79.2). Furthermore, compared to LLM-Judges, it also exhibits a larger solver-evaluator gap, maintaining a stronger correct-wrong separation even on instances where the underlying solver often fails to solve.
Do Language Models Associate Sound with Meaning? A Multimodal Study of Sound Symbolism
Nov 16, 2025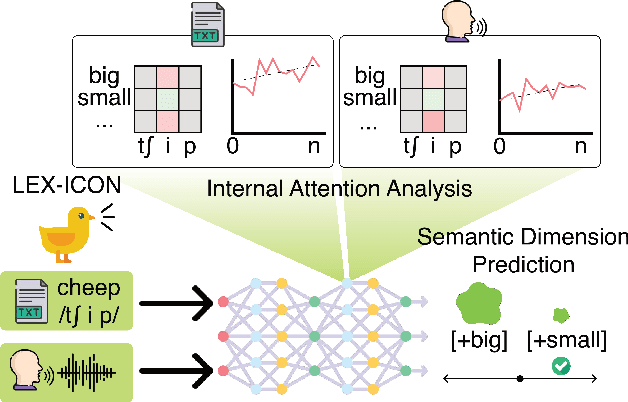

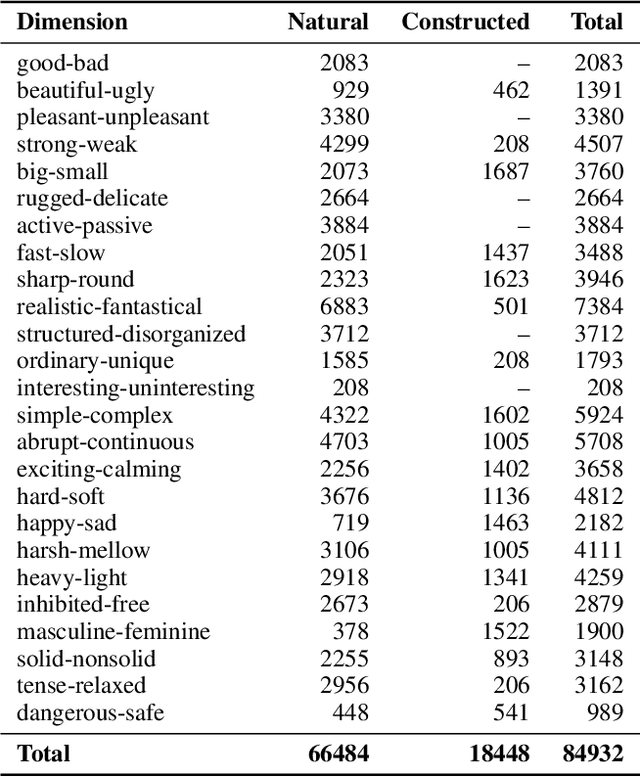
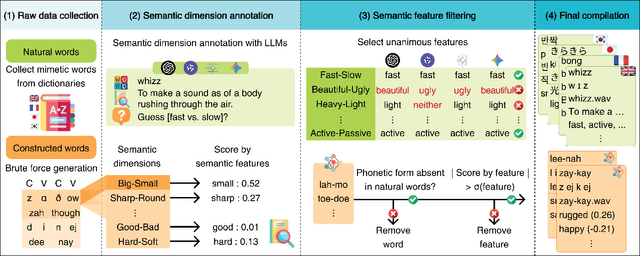
Sound symbolism is a linguistic concept that refers to non-arbitrary associations between phonetic forms and their meanings. We suggest that this can be a compelling probe into how Multimodal Large Language Models (MLLMs) interpret auditory information in human languages. We investigate MLLMs' performance on phonetic iconicity across textual (orthographic and IPA) and auditory forms of inputs with up to 25 semantic dimensions (e.g., sharp vs. round), observing models' layer-wise information processing by measuring phoneme-level attention fraction scores. To this end, we present LEX-ICON, an extensive mimetic word dataset consisting of 8,052 words from four natural languages (English, French, Japanese, and Korean) and 2,930 systematically constructed pseudo-words, annotated with semantic features applied across both text and audio modalities. Our key findings demonstrate (1) MLLMs' phonetic intuitions that align with existing linguistic research across multiple semantic dimensions and (2) phonosemantic attention patterns that highlight models' focus on iconic phonemes. These results bridge domains of artificial intelligence and cognitive linguistics, providing the first large-scale, quantitative analyses of phonetic iconicity in terms of MLLMs' interpretability.
What MLLMs Learn about When they Learn about Multimodal Reasoning: Perception, Reasoning, or their Integration?
Oct 02, 2025Multimodal reasoning models have recently shown promise on challenging domains such as olympiad-level geometry, yet their evaluation remains dominated by aggregate accuracy, a single score that obscures where and how models are improving. We introduce MathLens, a benchmark designed to disentangle the subskills of multimodal reasoning while preserving the complexity of textbook-style geometry problems. The benchmark separates performance into three components: Perception: extracting information from raw inputs, Reasoning: operating on available information, and Integration: selecting relevant perceptual evidence and applying it within reasoning. To support each test, we provide annotations: visual diagrams, textual descriptions to evaluate reasoning in isolation, controlled questions that require both modalities, and probes for fine-grained perceptual skills, all derived from symbolic specifications of the problems to ensure consistency and robustness. Our analysis reveals that different training approaches have uneven effects: First, reinforcement learning chiefly strengthens perception, especially when supported by textual supervision, while textual SFT indirectly improves perception through reflective reasoning. Second, reasoning improves only in tandem with perception. Third, integration remains the weakest capacity, with residual errors concentrated there once other skills advance. Finally, robustness diverges: RL improves consistency under diagram variation, whereas multimodal SFT reduces it through overfitting. We will release all data and experimental logs.
Zero-shot Multimodal Document Retrieval via Cross-modal Question Generation
Aug 23, 2025Rapid advances in Multimodal Large Language Models (MLLMs) have expanded information retrieval beyond purely textual inputs, enabling retrieval from complex real world documents that combine text and visuals. However, most documents are private either owned by individuals or confined within corporate silos and current retrievers struggle when faced with unseen domains or languages. To address this gap, we introduce PREMIR, a simple yet effective framework that leverages the broad knowledge of an MLLM to generate cross modal pre questions (preQs) before retrieval. Unlike earlier multimodal retrievers that compare embeddings in a single vector space, PREMIR leverages preQs from multiple complementary modalities to expand the scope of matching to the token level. Experiments show that PREMIR achieves state of the art performance on out of distribution benchmarks, including closed domain and multilingual settings, outperforming strong baselines across all retrieval metrics. We confirm the contribution of each component through in depth ablation studies, and qualitative analyses of the generated preQs further highlight the model's robustness in real world settings.
InfoCausalQA:Can Models Perform Non-explicit Causal Reasoning Based on Infographic?
Aug 08, 2025Recent advances in Vision-Language Models (VLMs) have demonstrated impressive capabilities in perception and reasoning. However, the ability to perform causal inference -- a core aspect of human cognition -- remains underexplored, particularly in multimodal settings. In this study, we introduce InfoCausalQA, a novel benchmark designed to evaluate causal reasoning grounded in infographics that combine structured visual data with textual context. The benchmark comprises two tasks: Task 1 focuses on quantitative causal reasoning based on inferred numerical trends, while Task 2 targets semantic causal reasoning involving five types of causal relations: cause, effect, intervention, counterfactual, and temporal. We manually collected 494 infographic-text pairs from four public sources and used GPT-4o to generate 1,482 high-quality multiple-choice QA pairs. These questions were then carefully revised by humans to ensure they cannot be answered based on surface-level cues alone but instead require genuine visual grounding. Our experimental results reveal that current VLMs exhibit limited capability in computational reasoning and even more pronounced limitations in semantic causal reasoning. Their significantly lower performance compared to humans indicates a substantial gap in leveraging infographic-based information for causal inference. Through InfoCausalQA, we highlight the need for advancing the causal reasoning abilities of multimodal AI systems.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025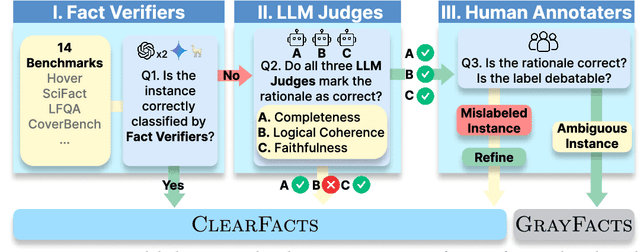

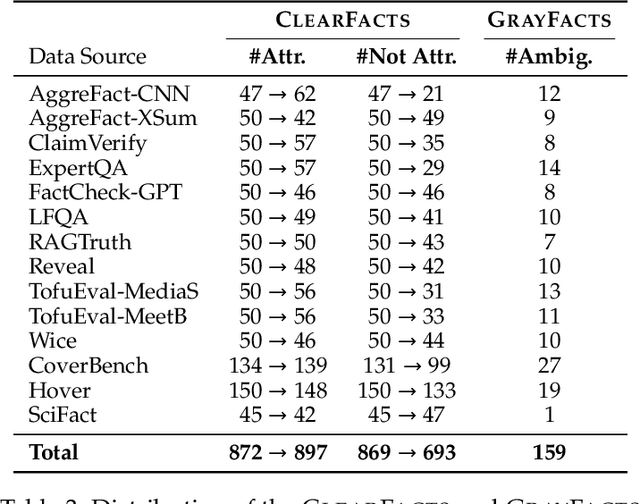
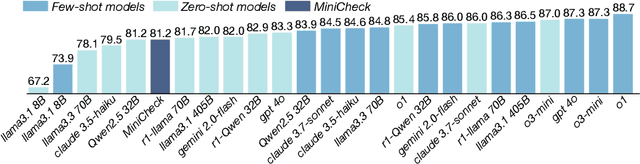
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers
Are Any-to-Any Models More Consistent Across Modality Transfers Than Specialists?
May 30, 2025Any-to-any generative models aim to enable seamless interpretation and generation across multiple modalities within a unified framework, yet their ability to preserve relationships across modalities remains uncertain. Do unified models truly achieve cross-modal coherence, or is this coherence merely perceived? To explore this, we introduce ACON, a dataset of 1,000 images (500 newly contributed) paired with captions, editing instructions, and Q&A pairs to evaluate cross-modal transfers rigorously. Using three consistency criteria-cyclic consistency, forward equivariance, and conjugated equivariance-our experiments reveal that any-to-any models do not consistently demonstrate greater cross-modal consistency than specialized models in pointwise evaluations such as cyclic consistency. However, equivariance evaluations uncover weak but observable consistency through structured analyses of the intermediate latent space enabled by multiple editing operations. We release our code and data at https://github.com/JiwanChung/ACON.