 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocraticKG: Knowledge Graph Construction via QA-Driven Fact Extraction
Jan 15, 2026Constructing Knowledge Graphs (KGs) from unstructured text provides a structured framework for knowledge representation and reasoning, yet current LLM-based approaches struggle with a fundamental trade-off: factual coverage often leads to relational fragmentation, while premature consolidation causes information loss. To address this, we propose SocraticKG, an automated KG construction method that introduces question-answer pairs as a structured intermediate representation to systematically unfold document-level semantics prior to triple extraction. By employing 5W1H-guided QA expansion, SocraticKG captures contextual dependencies and implicit relational links typically lost in direct KG extraction pipelines, providing explicit grounding in the source document that helps mitigate implicit reasoning errors. Evaluation on the MINE benchmark demonstrates that our approach effectively addresses the coverage-connectivity trade-off, achieving superior factual retention while maintaining high structural cohesion even as extracted knowledge volume substantially expands. These results highlight that QA-mediated semantic scaffolding plays a critical role in structuring semantics prior to KG extraction, enabling more coherent and reliable graph construction in subsequent stages.
Mi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Explain with Visual Keypoints Like a Real Mentor! A Benchmark for Multimodal Solution Explanation
Apr 07, 2025



With the rapid advancement of mathematical reasoning capabilities in Large Language Models (LLMs), AI systems are increasingly being adopted in educational settings to support students' comprehension of problem-solving processes. However, a critical component remains underexplored in current LLM-generated explanations: visual explanation. In real-world instructional contexts, human tutors routinely employ visual aids - such as diagrams, markings, and highlights - to enhance conceptual clarity. To bridge this gap, we introduce a novel task of visual solution explanation, which requires generating explanations that incorporate newly introduced visual elements essential for understanding (e.g., auxiliary lines, annotations, or geometric constructions). To evaluate model performance on this task, we propose MathExplain, a multimodal benchmark consisting of 997 math problems annotated with visual keypoints and corresponding explanatory text that references those elements. Our empirical results show that while some closed-source models demonstrate promising capabilities on visual solution-explaining, current open-source general-purpose models perform inconsistently, particularly in identifying relevant visual components and producing coherent keypoint-based explanations. We expect that visual solution-explaining and the MathExplain dataset will catalyze further research on multimodal LLMs in education and advance their deployment as effective, explanation-oriented AI tutors. Code and data will be released publicly.
Knowledge Synthesis of Photosynthesis Research Using a Large Language Model
Feb 03, 2025The development of biological data analysis tools and large language models (LLMs) has opened up new possibilities for utilizing AI in plant science research, with the potential to contribute significantly to knowledge integration and research gap identification. Nonetheless, current LLMs struggle to handle complex biological data and theoretical models in photosynthesis research and often fail to provide accurate scientific contexts. Therefore, this study proposed a photosynthesis research assistant (PRAG) based on OpenAI's GPT-4o with retrieval-augmented generation (RAG) techniques and prompt optimization. Vector databases and an automated feedback loop were used in the prompt optimization process to enhance the accuracy and relevance of the responses to photosynthesis-related queries. PRAG showed an average improvement of 8.7% across five metrics related to scientific writing, with a 25.4% increase in source transparency. Additionally, its scientific depth and domain coverage were comparable to those of photosynthesis research papers. A knowledge graph was used to structure PRAG's responses with papers within and outside the database, which allowed PRAG to match key entities with 63% and 39.5% of the database and test papers, respectively. PRAG can be applied for photosynthesis research and broader plant science domains, paving the way for more in-depth data analysis and predictive capabilities.
Improved identification of breakpoints in piecewise regression and its applications
Aug 27, 2024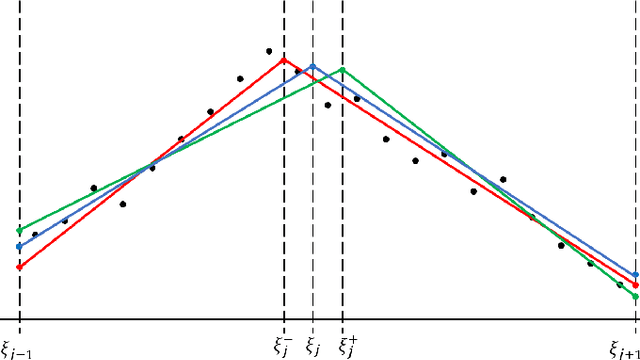
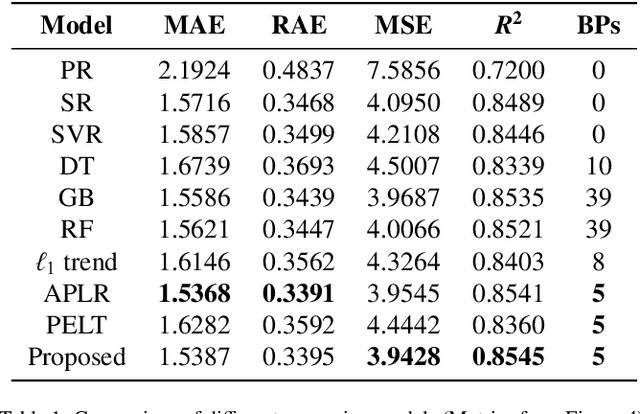
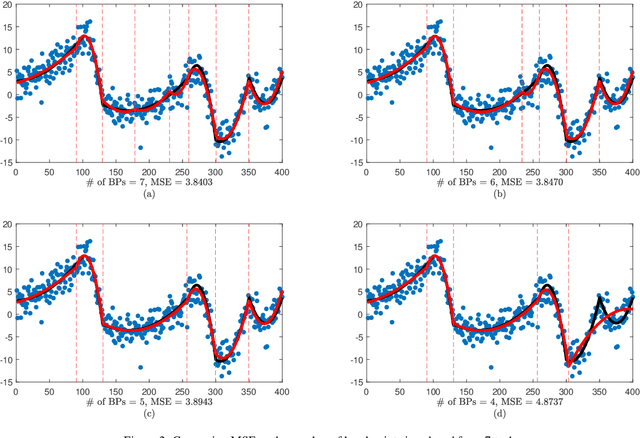
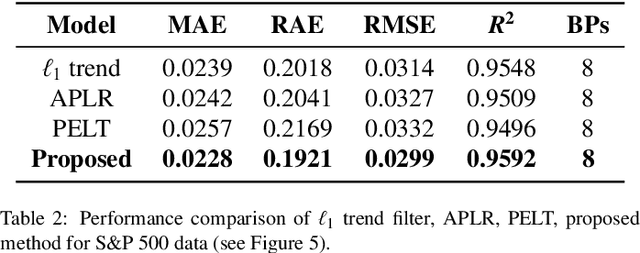
Identifying breakpoints in piecewise regression is critical in enhancing the reliability and interpretability of data fitting. In this paper, we propose novel algorithms based on the greedy algorithm to accurately and efficiently identify breakpoints in piecewise polynomial regression. The algorithm updates the breakpoints to minimize the error by exploring the neighborhood of each breakpoint. It has a fast convergence rate and stability to find optimal breakpoints. Moreover, it can determine the optimal number of breakpoints. The computational results for real and synthetic data show that its accuracy is better than any existing methods. The real-world datasets demonstrate that breakpoints through the proposed algorithm provide valuable data information.
Click-Gaussian: Interactive Segmentation to Any 3D Gaussians
Jul 16, 2024Interactive segmentation of 3D Gaussians opens a great opportunity for real-time manipulation of 3D scenes thanks to the real-time rendering capability of 3D Gaussian Splatting. However, the current methods suffer from time-consuming post-processing to deal with noisy segmentation output. Also, they struggle to provide detailed segmentation, which is important for fine-grained manipulation of 3D scenes. In this study, we propose Click-Gaussian, which learns distinguishable feature fields of two-level granularity, facilitating segmentation without time-consuming post-processing. We delve into challenges stemming from inconsistently learned feature fields resulting from 2D segmentation obtained independently from a 3D scene. 3D segmentation accuracy deteriorates when 2D segmentation results across the views, primary cues for 3D segmentation, are in conflict. To overcome these issues, we propose Global Feature-guided Learning (GFL). GFL constructs the clusters of global feature candidates from noisy 2D segments across the views, which smooths out noises when training the features of 3D Gaussians. Our method runs in 10 ms per click, 15 to 130 times as fast as the previous methods, while also significantly improving segmentation accuracy. Our project page is available at https://seokhunchoi.github.io/Click-Gaussian
Blending-NeRF: Text-Driven Localized Editing in Neural Radiance Fields
Sep 11, 2023Text-driven localized editing of 3D objects is particularly difficult as locally mixing the original 3D object with the intended new object and style effects without distorting the object's form is not a straightforward process. To address this issue, we propose a novel NeRF-based model, Blending-NeRF, which consists of two NeRF networks: pretrained NeRF and editable NeRF. Additionally, we introduce new blending operations that allow Blending-NeRF to properly edit target regions which are localized by text. By using a pretrained vision-language aligned model, CLIP, we guide Blending-NeRF to add new objects with varying colors and densities, modify textures, and remove parts of the original object. Our extensive experiments demonstrate that Blending-NeRF produces naturally and locally edited 3D objects from various text prompts. Our project page is available at https://seokhunchoi.github.io/Blending-NeRF/
Cross-Modal Alignment Learning of Vision-Language Conceptual Systems
Jul 31, 2022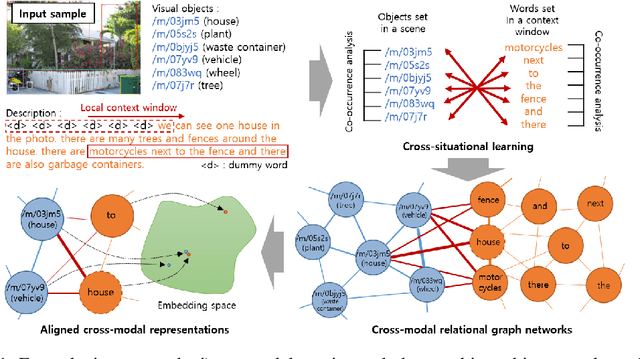

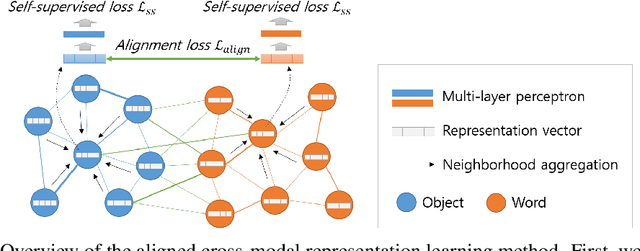

Human infants learn the names of objects and develop their own conceptual systems without explicit supervision. In this study, we propose methods for learning aligned vision-language conceptual systems inspired by infants' word learning mechanisms. The proposed model learns the associations of visual objects and words online and gradually constructs cross-modal relational graph networks. Additionally, we also propose an aligned cross-modal representation learning method that learns semantic representations of visual objects and words in a self-supervised manner based on the cross-modal relational graph networks. It allows entities of different modalities with conceptually the same meaning to have similar semantic representation vectors. We quantitatively and qualitatively evaluate our method, including object-to-word mapping and zero-shot learning tasks, showing that the proposed model significantly outperforms the baselines and that each conceptual system is topologically aligned.
Message Passing Adaptive Resonance Theory for Online Active Semi-supervised Learning
Dec 02, 2020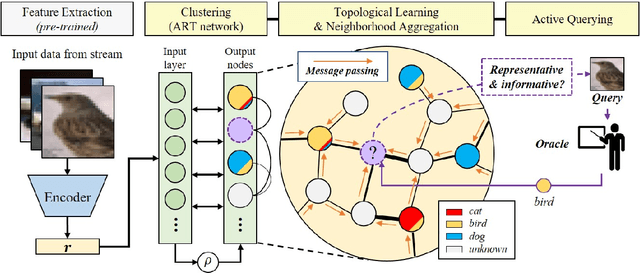
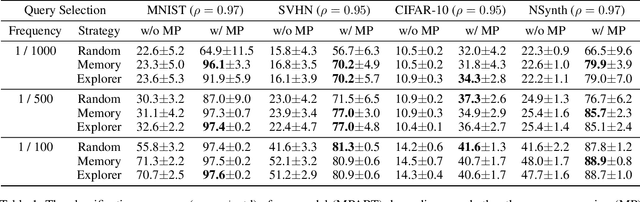

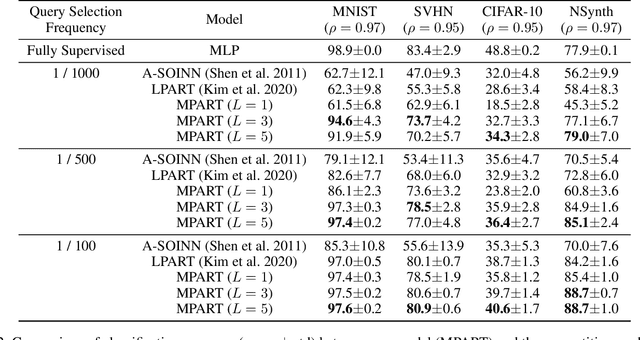
Active learning is widely used to reduce labeling effort and training time by repeatedly querying only the most beneficial samples from unlabeled data. In real-world problems where data cannot be stored indefinitely due to limited storage or privacy issues, the query selection and the model update should be performed as soon as a new data sample is observed. Various online active learning methods have been studied to deal with these challenges; however, there are difficulties in selecting representative query samples and updating the model efficiently. In this study, we propose Message Passing Adaptive Resonance Theory (MPART) for online active semi-supervised learning. The proposed model learns the distribution and topology of the input data online. It then infers the class of unlabeled data and selects informative and representative samples through message passing between nodes on the topological graph. MPART queries the beneficial samples on-the-fly in stream-based selective sampling scenarios, and continuously improve the classification model using both labeled and unlabeled data. We evaluate our model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets with comparable query selection strategies and frequencies, showing that MPART significantly outperforms the competitive models in online active learning environments.
Label Propagation Adaptive Resonance Theory for Semi-supervised Continuous Learning
Apr 16, 2020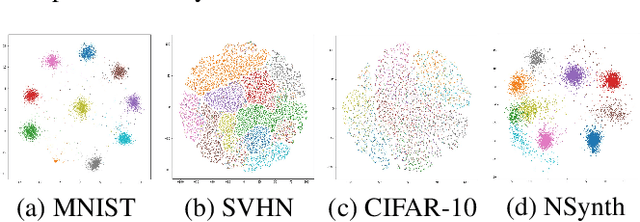
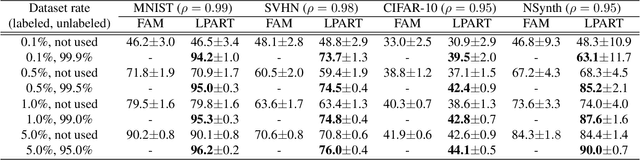
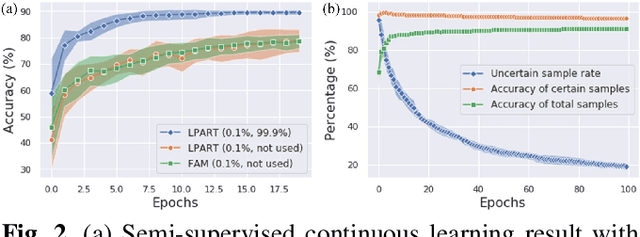
Semi-supervised learning and continuous learning are fundamental paradigms for human-level intelligence. To deal with real-world problems where labels are rarely given and the opportunity to access the same data is limited, it is necessary to apply these two paradigms in a joined fashion. In this paper, we propose Label Propagation Adaptive Resonance Theory (LPART) for semi-supervised continuous learning. LPART uses an online label propagation mechanism to perform classification and gradually improves its accuracy as the observed data accumulates. We evaluated the proposed model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets by adjusting the ratio of the labeled and unlabeled data. The accuracies are much higher when both labeled and unlabeled data are used, demonstrating the significant advantage of LPART in environments where the data labels are scarce.