 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseSyn: Synthesizing Diverse 3D Pose Data from In-the-Wild 2D Data
Mar 17, 2025



Despite considerable efforts to enhance the generalization of 3D pose estimators without costly 3D annotations, existing data augmentation methods struggle in real world scenarios with diverse human appearances and complex poses. We propose PoseSyn, a novel data synthesis framework that transforms abundant in the wild 2D pose dataset into diverse 3D pose image pairs. PoseSyn comprises two key components: Error Extraction Module (EEM), which identifies challenging poses from the 2D pose datasets, and Motion Synthesis Module (MSM), which synthesizes motion sequences around the challenging poses. Then, by generating realistic 3D training data via a human animation model aligned with challenging poses and appearances PoseSyn boosts the accuracy of various 3D pose estimators by up to 14% across real world benchmarks including various backgrounds and occlusions, challenging poses, and multi view scenarios. Extensive experiments further confirm that PoseSyn is a scalable and effective approach for improving generalization without relying on expensive 3D annotations, regardless of the pose estimator's model size or design.
Click-Gaussian: Interactive Segmentation to Any 3D Gaussians
Jul 16, 2024Interactive segmentation of 3D Gaussians opens a great opportunity for real-time manipulation of 3D scenes thanks to the real-time rendering capability of 3D Gaussian Splatting. However, the current methods suffer from time-consuming post-processing to deal with noisy segmentation output. Also, they struggle to provide detailed segmentation, which is important for fine-grained manipulation of 3D scenes. In this study, we propose Click-Gaussian, which learns distinguishable feature fields of two-level granularity, facilitating segmentation without time-consuming post-processing. We delve into challenges stemming from inconsistently learned feature fields resulting from 2D segmentation obtained independently from a 3D scene. 3D segmentation accuracy deteriorates when 2D segmentation results across the views, primary cues for 3D segmentation, are in conflict. To overcome these issues, we propose Global Feature-guided Learning (GFL). GFL constructs the clusters of global feature candidates from noisy 2D segments across the views, which smooths out noises when training the features of 3D Gaussians. Our method runs in 10 ms per click, 15 to 130 times as fast as the previous methods, while also significantly improving segmentation accuracy. Our project page is available at https://seokhunchoi.github.io/Click-Gaussian
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
May 07, 2024
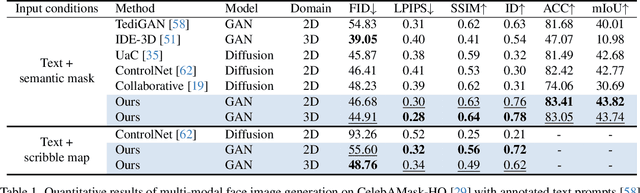
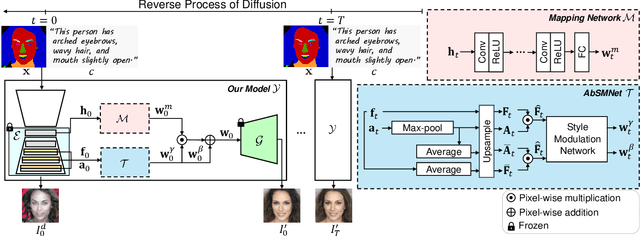
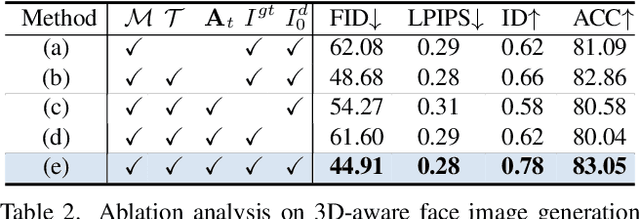
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Blending-NeRF: Text-Driven Localized Editing in Neural Radiance Fields
Sep 11, 2023Text-driven localized editing of 3D objects is particularly difficult as locally mixing the original 3D object with the intended new object and style effects without distorting the object's form is not a straightforward process. To address this issue, we propose a novel NeRF-based model, Blending-NeRF, which consists of two NeRF networks: pretrained NeRF and editable NeRF. Additionally, we introduce new blending operations that allow Blending-NeRF to properly edit target regions which are localized by text. By using a pretrained vision-language aligned model, CLIP, we guide Blending-NeRF to add new objects with varying colors and densities, modify textures, and remove parts of the original object. Our extensive experiments demonstrate that Blending-NeRF produces naturally and locally edited 3D objects from various text prompts. Our project page is available at https://seokhunchoi.github.io/Blending-NeRF/