 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE-LD: Towards Scalable and Generalizable End-to-End Language Diarization via Simulated Data Augmentation
Oct 01, 2025In this paper, we present a neural spoken language diarization model that supports an unconstrained span of languages within a single framework. Our approach integrates a learnable query-based architecture grounded in multilingual awareness, with large-scale pretraining on simulated code-switching data. By jointly leveraging these two components, our method overcomes the limitations of conventional approaches in data scarcity and architecture optimization, and generalizes effectively to real-world multilingual settings across diverse environments. Experimental results demonstrate that our approach achieves state-of-the-art performance on several language diarization benchmarks, with a relative performance improvement of 23% to 52% over previous methods. We believe that this work not only advances research in language diarization but also establishes a foundational framework for code-switching speech technologies.
MedErr-CT: A Visual Question Answering Benchmark for Identifying and Correcting Errors in CT Reports
Jun 24, 2025Computed Tomography (CT) plays a crucial role in clinical diagnosis, but the growing demand for CT examinations has raised concerns about diagnostic errors. While Multimodal Large Language Models (MLLMs) demonstrate promising comprehension of medical knowledge, their tendency to produce inaccurate information highlights the need for rigorous validation. However, existing medical visual question answering (VQA) benchmarks primarily focus on simple visual recognition tasks, lacking clinical relevance and failing to assess expert-level knowledge. We introduce MedErr-CT, a novel benchmark for evaluating medical MLLMs' ability to identify and correct errors in CT reports through a VQA framework. The benchmark includes six error categories - four vision-centric errors (Omission, Insertion, Direction, Size) and two lexical error types (Unit, Typo) - and is organized into three task levels: classification, detection, and correction. Using this benchmark, we quantitatively assess the performance of state-of-the-art 3D medical MLLMs, revealing substantial variation in their capabilities across different error types. Our benchmark contributes to the development of more reliable and clinically applicable MLLMs, ultimately helping reduce diagnostic errors and improve accuracy in clinical practice. The code and datasets are available at https://github.com/babbu3682/MedErr-CT.
An Adversarial Learning Approach to Irregular Time-Series Forecasting
Nov 28, 2024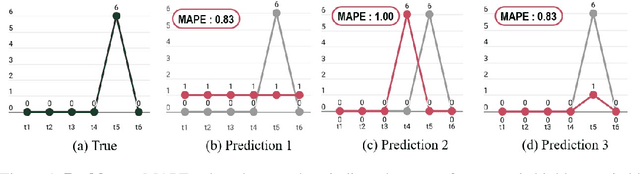
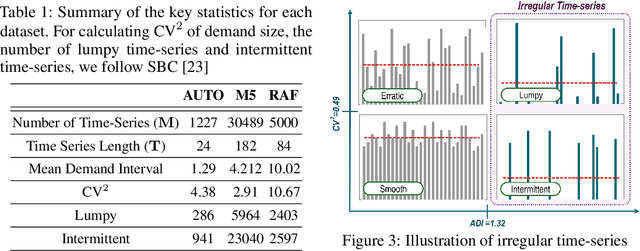
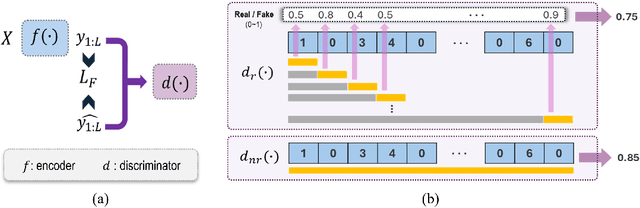
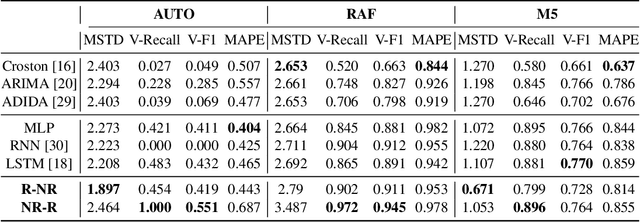
Forecasting irregular time series presents significant challenges due to two key issues: the vulnerability of models to mean regression, driven by the noisy and complex nature of the data, and the limitations of traditional error-based evaluation metrics, which fail to capture meaningful patterns and penalize unrealistic forecasts. These problems result in forecasts that often misalign with human intuition. To tackle these challenges, we propose an adversarial learning framework with a deep analysis of adversarial components. Specifically, we emphasize the importance of balancing the modeling of global distribution (overall patterns) and transition dynamics (localized temporal changes) to better capture the nuances of irregular time series. Overall, this research provides practical insights for improving models and evaluation metrics, and pioneers the application of adversarial learning in the domian of irregular time-series forecasting.
Enhanced Deep Speech Separation in Clustered Ad Hoc Distributed Microphone Environments
Jun 14, 2024Ad-hoc distributed microphone environments, where microphone locations and numbers are unpredictable, present a challenge to traditional deep learning models, which typically require fixed architectures. To tailor deep learning models to accommodate arbitrary array configurations, the Transform-Average-Concatenate (TAC) layer was previously introduced. In this work, we integrate TAC layers with dual-path transformers for speech separation from two simultaneous talkers in realistic settings. However, the distributed nature makes it hard to fuse information across microphones efficiently. Therefore, we explore the efficacy of blindly clustering microphones around sources of interest prior to enhancement. Experimental results show that this deep cluster-informed approach significantly improves the system's capacity to cope with the inherent variability observed in ad-hoc distributed microphone environments.
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
May 07, 2024
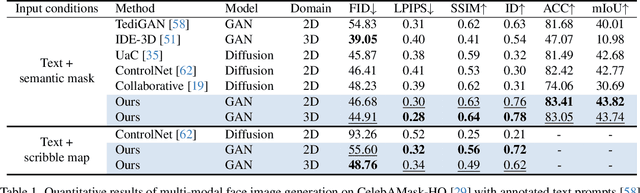
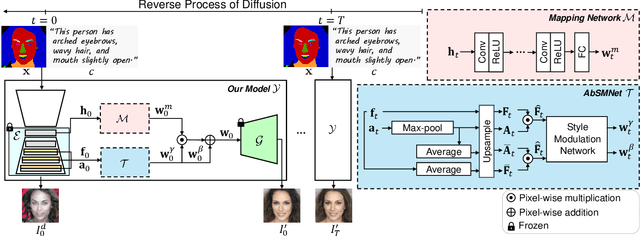
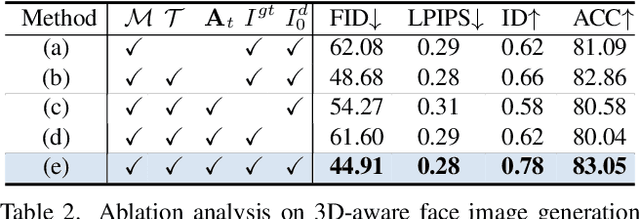
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Jul 26, 2021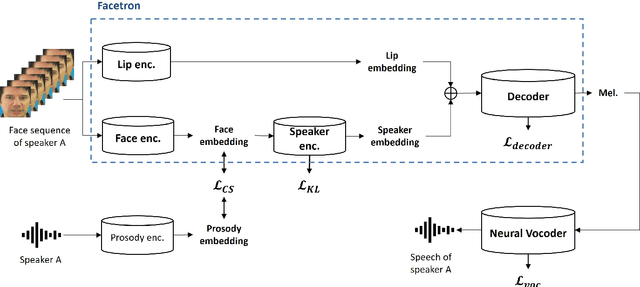
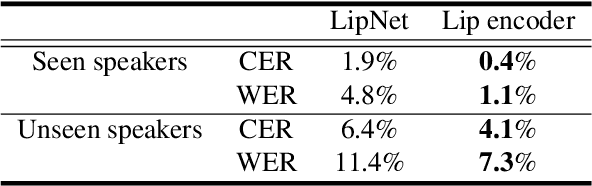
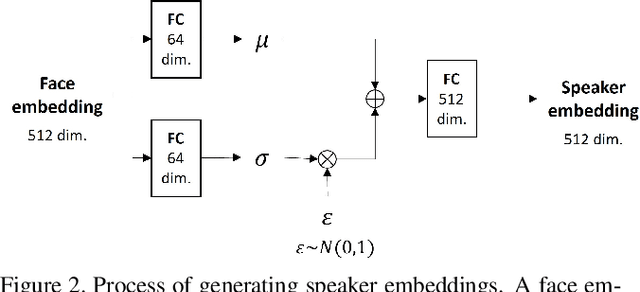

In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.