 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE-LD: Towards Scalable and Generalizable End-to-End Language Diarization via Simulated Data Augmentation
Oct 01, 2025In this paper, we present a neural spoken language diarization model that supports an unconstrained span of languages within a single framework. Our approach integrates a learnable query-based architecture grounded in multilingual awareness, with large-scale pretraining on simulated code-switching data. By jointly leveraging these two components, our method overcomes the limitations of conventional approaches in data scarcity and architecture optimization, and generalizes effectively to real-world multilingual settings across diverse environments. Experimental results demonstrate that our approach achieves state-of-the-art performance on several language diarization benchmarks, with a relative performance improvement of 23% to 52% over previous methods. We believe that this work not only advances research in language diarization but also establishes a foundational framework for code-switching speech technologies.
UniverSR: Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching
Oct 01, 2025In this paper, we present a vocoder-free framework for audio super-resolution that employs a flow matching generative model to capture the conditional distribution of complex-valued spectral coefficients. Unlike conventional two-stage diffusion-based approaches that predict a mel-spectrogram and then rely on a pre-trained neural vocoder to synthesize waveforms, our method directly reconstructs waveforms via the inverse Short-Time Fourier Transform (iSTFT), thereby eliminating the dependence on a separate vocoder. This design not only simplifies end-to-end optimization but also overcomes a critical bottleneck of two-stage pipelines, where the final audio quality is fundamentally constrained by vocoder performance. Experiments show that our model consistently produces high-fidelity 48 kHz audio across diverse upsampling factors, achieving state-of-the-art performance on both speech and general audio datasets.
UniCoM: A Universal Code-Switching Speech Generator
Aug 21, 2025


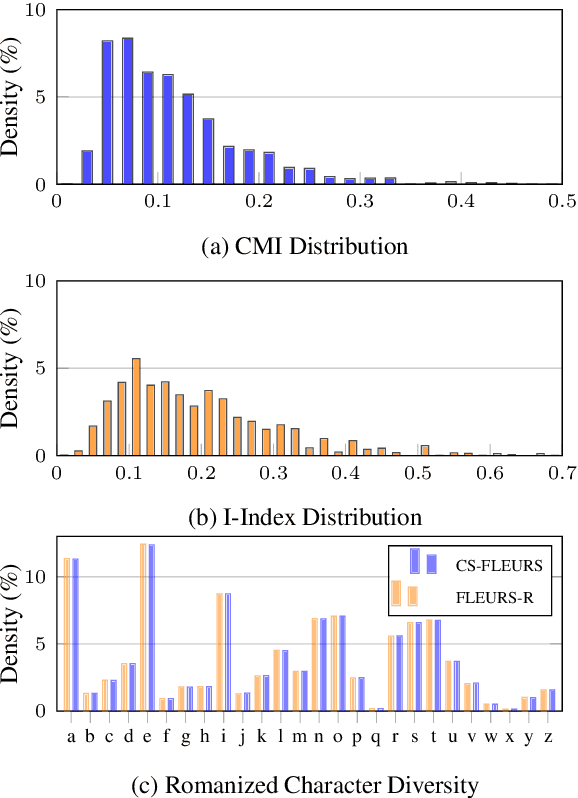
Code-switching (CS), the alternation between two or more languages within a single speaker's utterances, is common in real-world conversations and poses significant challenges for multilingual speech technology. However, systems capable of handling this phenomenon remain underexplored, primarily due to the scarcity of suitable datasets. To resolve this issue, we propose Universal Code-Mixer (UniCoM), a novel pipeline for generating high-quality, natural CS samples without altering sentence semantics. Our approach utilizes an algorithm we call Substituting WORDs with Synonyms (SWORDS), which generates CS speech by replacing selected words with their translations while considering their parts of speech. Using UniCoM, we construct Code-Switching FLEURS (CS-FLEURS), a multilingual CS corpus designed for automatic speech recognition (ASR) and speech-to-text translation (S2TT). Experimental results show that CS-FLEURS achieves high intelligibility and naturalness, performing comparably to existing datasets on both objective and subjective metrics. We expect our approach to advance CS speech technology and enable more inclusive multilingual systems.
Neural Spectral Band Generation for Audio Coding
Jun 07, 2025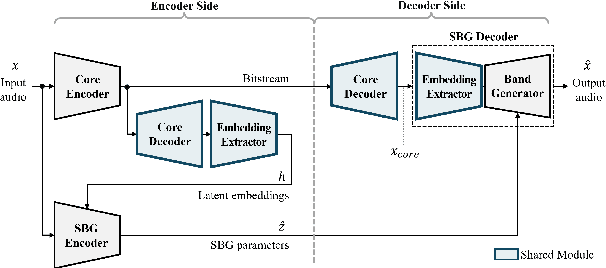
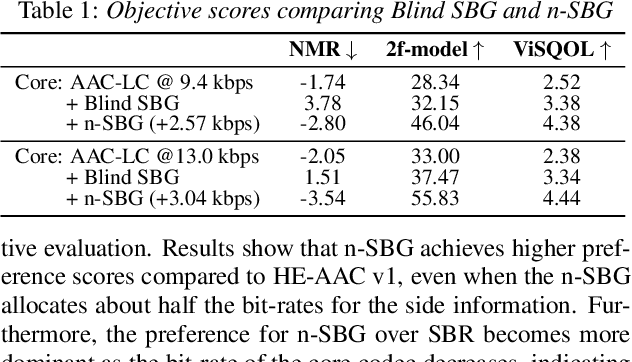
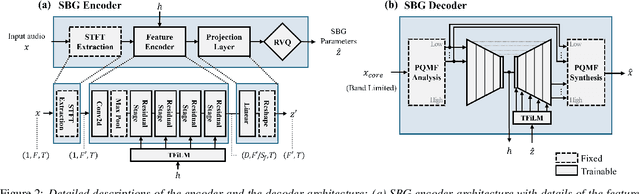
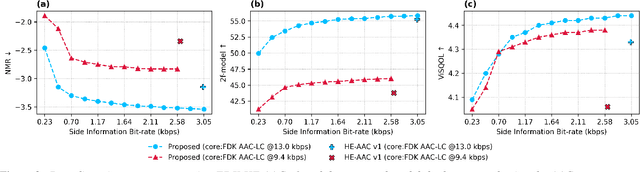
Audio bandwidth extension is the task of reconstructing missing high frequency components of bandwidth-limited audio signals, where bandwidth limitation is a common issue for audio signals due to several reasons, including channel capacity and data constraints. While conventional spectral band replication is a well-established parametric approach to audio bandwidth extension, the SBR usually entails coarse feature extraction and reconstruction techniques, which leads to limitations when processing various types of audio signals. In parallel, numerous deep neural network-based audio bandwidth extension methods have been proposed. These DNN-based methods are usually referred to as blind BWE, as these methods do not rely on prior information extracted from original signals, and only utilize given low frequency band signals to estimate missing high frequency components. In order to replace conventional SBR with DNNs, simply adopting existing DNN-based methodologies results in suboptimal performance due to the blindness of these methods. My proposed research suggests a new approach to parametric non-blind bandwidth extension, as DNN-based side information extraction and DNN-based bandwidth extension are performed only at the front and end of the audio coding pipeline.
StableQuant: Layer Adaptive Post-Training Quantization for Speech Foundation Models
Apr 21, 2025In this paper, we propose StableQuant, a novel adaptive post-training quantization (PTQ) algorithm for widely used speech foundation models (SFMs). While PTQ has been successfully employed for compressing large language models (LLMs) due to its ability to bypass additional fine-tuning, directly applying these techniques to SFMs may not yield optimal results, as SFMs utilize distinct network architecture for feature extraction. StableQuant demonstrates optimal quantization performance regardless of the network architecture type, as it adaptively determines the quantization range for each layer by analyzing both the scale distributions and overall performance. We evaluate our algorithm on two SFMs, HuBERT and wav2vec2.0, for an automatic speech recognition (ASR) task, and achieve superior performance compared to traditional PTQ methods. StableQuant successfully reduces the sizes of SFM models to a quarter and doubles the inference speed while limiting the word error rate (WER) performance drop to less than 0.3% with 8-bit quantization.
LAMA-UT: Language Agnostic Multilingual ASR through Orthography Unification and Language-Specific Transliteration
Dec 23, 2024Building a universal multilingual automatic speech recognition (ASR) model that performs equitably across languages has long been a challenge due to its inherent difficulties. To address this task we introduce a Language-Agnostic Multilingual ASR pipeline through orthography Unification and language-specific Transliteration (LAMA-UT). LAMA-UT operates without any language-specific modules while matching the performance of state-of-the-art models trained on a minimal amount of data. Our pipeline consists of two key steps. First, we utilize a universal transcription generator to unify orthographic features into Romanized form and capture common phonetic characteristics across diverse languages. Second, we utilize a universal converter to transform these universal transcriptions into language-specific ones. In experiments, we demonstrate the effectiveness of our proposed method leveraging universal transcriptions for massively multilingual ASR. Our pipeline achieves a relative error reduction rate of 45% when compared to Whisper and performs comparably to MMS, despite being trained on only 0.1% of Whisper's training data. Furthermore, our pipeline does not rely on any language-specific modules. However, it performs on par with zero-shot ASR approaches which utilize additional language-specific lexicons and language models. We expect this framework to serve as a cornerstone for flexible multilingual ASR systems that are generalizable even to unseen languages.
Optimization of DNN-based speaker verification model through efficient quantization technique
Jul 12, 2024As Deep Neural Networks (DNNs) rapidly advance in various fields, including speech verification, they typically involve high computational costs and substantial memory consumption, which can be challenging to manage on mobile systems. Quantization of deep models offers a means to reduce both computational and memory expenses. Our research proposes an optimization framework for the quantization of the speaker verification model. By analyzing performance changes and model size reductions in each layer of a pre-trained speaker verification model, we have effectively minimized performance degradation while significantly reducing the model size. Our quantization algorithm is the first attempt to maintain the performance of the state-of-the-art pre-trained speaker verification model, ECAPATDNN, while significantly compressing its model size. Overall, our quantization approach resulted in reducing the model size by half, with an increase in EER limited to 0.07%.
Speak in the Scene: Diffusion-based Acoustic Scene Transfer toward Immersive Speech Generation
Jun 18, 2024This paper introduces a novel task in generative speech processing, Acoustic Scene Transfer (AST), which aims to transfer acoustic scenes of speech signals to diverse environments. AST promises an immersive experience in speech perception by adapting the acoustic scene behind speech signals to desired environments. We propose AST-LDM for the AST task, which generates speech signals accompanied by the target acoustic scene of the reference prompt. Specifically, AST-LDM is a latent diffusion model conditioned by CLAP embeddings that describe target acoustic scenes in either audio or text modalities. The contributions of this paper include introducing the AST task and implementing its baseline model. For AST-LDM, we emphasize its core framework, which is to preserve the input speech and generate audio consistently with both the given speech and the target acoustic environment. Experiments, including objective and subjective tests, validate the feasibility and efficacy of our approach.
Enhanced Deep Speech Separation in Clustered Ad Hoc Distributed Microphone Environments
Jun 14, 2024Ad-hoc distributed microphone environments, where microphone locations and numbers are unpredictable, present a challenge to traditional deep learning models, which typically require fixed architectures. To tailor deep learning models to accommodate arbitrary array configurations, the Transform-Average-Concatenate (TAC) layer was previously introduced. In this work, we integrate TAC layers with dual-path transformers for speech separation from two simultaneous talkers in realistic settings. However, the distributed nature makes it hard to fuse information across microphones efficiently. Therefore, we explore the efficacy of blindly clustering microphones around sources of interest prior to enhancement. Experimental results show that this deep cluster-informed approach significantly improves the system's capacity to cope with the inherent variability observed in ad-hoc distributed microphone environments.
Style Modeling for Multi-Speaker Articulation-to-Speech
Dec 21, 2023In this paper, we propose a neural articulation-to-speech (ATS) framework that synthesizes high-quality speech from articulatory signal in a multi-speaker situation. Most conventional ATS approaches only focus on modeling contextual information of speech from a single speaker's articulatory features. To explicitly represent each speaker's speaking style as well as the contextual information, our proposed model estimates style embeddings, guided from the essential speech style attributes such as pitch and energy. We adopt convolutional layers and transformer-based attention layers for our model to fully utilize both local and global information of articulatory signals, measured by electromagnetic articulography (EMA). Our model significantly improves the quality of synthesized speech compared to the baseline in terms of objective and subjective measurements in the Haskins dataset.