 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Deep Speech Separation in Clustered Ad Hoc Distributed Microphone Environments
Jun 14, 2024Ad-hoc distributed microphone environments, where microphone locations and numbers are unpredictable, present a challenge to traditional deep learning models, which typically require fixed architectures. To tailor deep learning models to accommodate arbitrary array configurations, the Transform-Average-Concatenate (TAC) layer was previously introduced. In this work, we integrate TAC layers with dual-path transformers for speech separation from two simultaneous talkers in realistic settings. However, the distributed nature makes it hard to fuse information across microphones efficiently. Therefore, we explore the efficacy of blindly clustering microphones around sources of interest prior to enhancement. Experimental results show that this deep cluster-informed approach significantly improves the system's capacity to cope with the inherent variability observed in ad-hoc distributed microphone environments.
Influence of Lossy Speech Codecs on Hearing-aid, Binaural Sound Source Localisation using DNNs
Jun 04, 2023

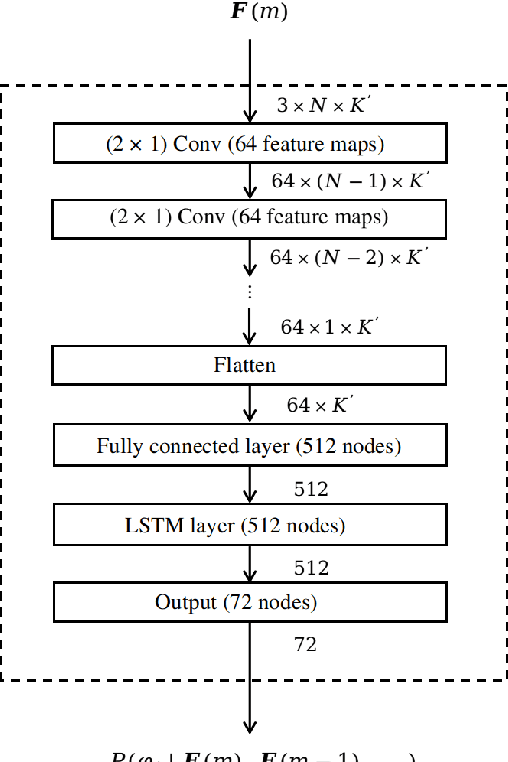
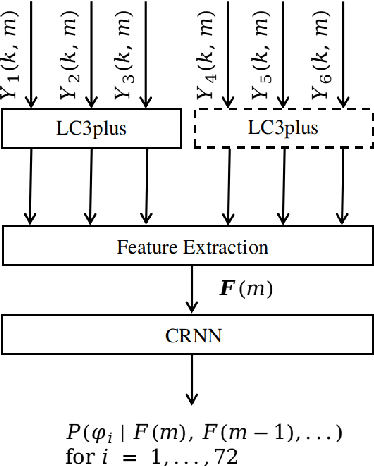
Hearing aids are typically equipped with multiple microphones to exploit spatial information for source localisation and speech enhancement. Especially for hearing aids, a good source localisation is important: it not only guides source separation methods but can also be used to enhance spatial cues, increasing user-awareness of important events in their surroundings. We use a state-of-the-art deep neural network (DNN) to perform binaural direction-of-arrival (DoA) estimation, where the DNN uses information from all microphones at both ears. However, hearing aids have limited bandwidth to exchange this data. Bluetooth low-energy (BLE) is emerging as an attractive option to facilitate such data exchange, with the LC3plus codec offering several bitrate and latency trade-off possibilities. In this paper, we investigate the effect of such lossy codecs on localisation accuracy. Specifically, we consider two conditions: processing at one ear vs processing at a central point, which influences the number of channels that need to be encoded. Performance is benchmarked against a baseline that allows full audio-exchange - yielding valuable insights into the usage of DNNs under lossy encoding. We also extend the Pyroomacoustics library to include hearing-device and head-related transfer functions (HD-HRTFs) to suitably train the networks. This can also benefit other researchers in the field.