 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure and Progress Aware Diffusion for Medical Image Segmentation
Mar 09, 2026Medical image segmentation is crucial for computer-aided diagnosis, which necessitates understanding both coarse morphological and semantic structures, as well as carving fine boundaries. The morphological and semantic structures in medical images are beneficial and stable clues for target understanding. While the fine boundaries of medical targets (like tumors and lesions) are usually ambiguous and noisy since lesion overlap, annotation uncertainty, and so on, making it not reliable to serve as early supervision. However, existing methods simultaneously learn coarse structures and fine boundaries throughout the training process. In this paper, we propose a structure and progress-aware diffusion (SPAD) for medical image segmentation, which consists of a semantic-concentrated diffusion (ScD) and a boundary-centralized diffusion (BcD) modulated by a progress-aware scheduler (PaS). Specifically, the semantic-concentrated diffusion introduces anchor-preserved target perturbation, which perturbs pixels within a medical target but preserves unaltered areas as semantic anchors, encouraging the model to infer noisy target areas from the surrounding semantic context. The boundary-centralized diffusion introduces progress-aware boundary noise, which blurs unreliable and ambiguous boundaries, thus compelling the model to focus on coarse but stable anatomical morphology and global semantics. Furthermore, the progress-aware scheduler gradually modulates noise intensity of the ScD and BcD forming a coarse-to-fine diffusion paradigm, which encourage focusing on coarse morphological and semantic structures during early target understanding stages and gradually shifting to fine target boundaries during later contour adjusting stages.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Bears, all bears, and some bears. Language Constraints on Language Models' Inductive Inferences
Jan 14, 2026Language places subtle constraints on how we make inductive inferences. Developmental evidence by Gelman et al. (2002) has shown children (4 years and older) to differentiate among generic statements ("Bears are daxable"), universally quantified NPs ("all bears are daxable") and indefinite plural NPs ("some bears are daxable") in extending novel properties to a specific member (all > generics > some), suggesting that they represent these types of propositions differently. We test if these subtle differences arise in general purpose statistical learners like Vision Language Models, by replicating the original experiment. On tasking them through a series of precondition tests (robust identification of categories in images and sensitivities to all and some), followed by the original experiment, we find behavioral alignment between models and humans. Post-hoc analyses on their representations revealed that these differences are organized based on inductive constraints and not surface-form differences.
Privileged Self-Access Matters for Introspection in AI
Aug 20, 2025Whether AI models can introspect is an increasingly important practical question. But there is no consensus on how introspection is to be defined. Beginning from a recently proposed ''lightweight'' definition, we argue instead for a thicker one. According to our proposal, introspection in AI is any process which yields information about internal states through a process more reliable than one with equal or lower computational cost available to a third party. Using experiments where LLMs reason about their internal temperature parameters, we show they can appear to have lightweight introspection while failing to meaningfully introspect per our proposed definition.
Federated Client-tailored Adapter for Medical Image Segmentation
Apr 25, 2025Medical image segmentation in X-ray images is beneficial for computer-aided diagnosis and lesion localization. Existing methods mainly fall into a centralized learning paradigm, which is inapplicable in the practical medical scenario that only has access to distributed data islands. Federated Learning has the potential to offer a distributed solution but struggles with heavy training instability due to client-wise domain heterogeneity (including distribution diversity and class imbalance). In this paper, we propose a novel Federated Client-tailored Adapter (FCA) framework for medical image segmentation, which achieves stable and client-tailored adaptive segmentation without sharing sensitive local data. Specifically, the federated adapter stirs universal knowledge in off-the-shelf medical foundation models to stabilize the federated training process. In addition, we develop two client-tailored federated updating strategies that adaptively decompose the adapter into common and individual components, then globally and independently update the parameter groups associated with common client-invariant and individual client-specific units, respectively. They further stabilize the heterogeneous federated learning process and realize optimal client-tailored instead of sub-optimal global-compromised segmentation models. Extensive experiments on three large-scale datasets demonstrate the effectiveness and superiority of the proposed FCA framework for federated medical segmentation.
Language Models Fail to Introspect About Their Knowledge of Language
Mar 10, 2025There has been recent interest in whether large language models (LLMs) can introspect about their own internal states. Such abilities would make LLMs more interpretable, and also validate the use of standard introspective methods in linguistics to evaluate grammatical knowledge in models (e.g., asking "Is this sentence grammatical?"). We systematically investigate emergent introspection across 21 open-source LLMs, in two domains where introspection is of theoretical interest: grammatical knowledge and word prediction. Crucially, in both domains, a model's internal linguistic knowledge can be theoretically grounded in direct measurements of string probability. We then evaluate whether models' responses to metalinguistic prompts faithfully reflect their internal knowledge. We propose a new measure of introspection: the degree to which a model's prompted responses predict its own string probabilities, beyond what would be predicted by another model with nearly identical internal knowledge. While both metalinguistic prompting and probability comparisons lead to high task accuracy, we do not find evidence that LLMs have privileged "self-access". Our findings complicate recent results suggesting that models can introspect, and add new evidence to the argument that prompted responses should not be conflated with models' linguistic generalizations.
ZhoBLiMP: a Systematic Assessment of Language Models with Linguistic Minimal Pairs in Chinese
Nov 09, 2024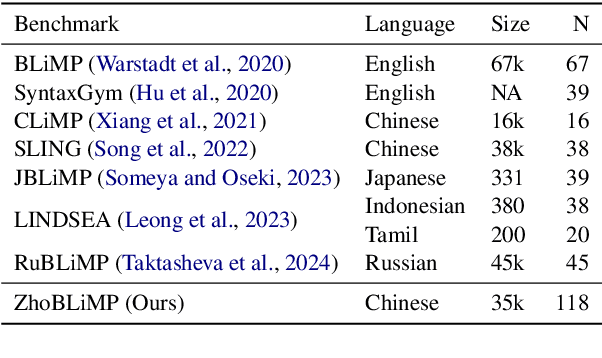

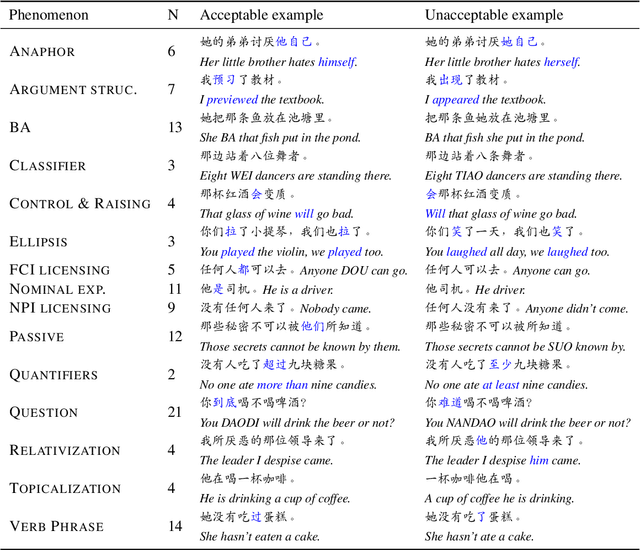
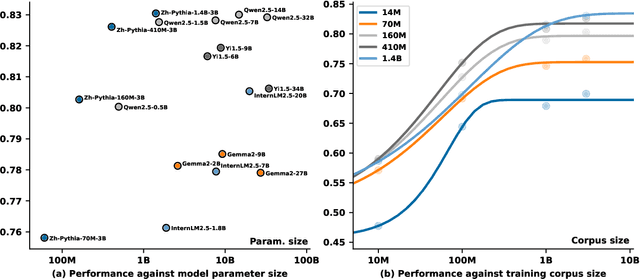
Whether and how language models (LMs) acquire the syntax of natural languages has been widely evaluated under the minimal pair paradigm. However, a lack of wide-coverage benchmarks in languages other than English has constrained systematic investigations into the issue. Addressing it, we first introduce ZhoBLiMP, the most comprehensive benchmark of linguistic minimal pairs for Chinese to date, with 118 paradigms, covering 15 linguistic phenomena. We then train 20 LMs of different sizes (14M to 1.4B) on Chinese corpora of various volumes (100M to 3B tokens) and evaluate them along with 14 off-the-shelf LLMs on ZhoBLiMP. The overall results indicate that Chinese grammar can be mostly learned by models with around 500M parameters, trained on 1B tokens with one epoch, showing limited benefits for further scaling. Most (N=95) linguistic paradigms are of easy or medium difficulty for LMs, while there are still 13 paradigms that remain challenging even for models with up to 32B parameters. In regard to how LMs acquire Chinese grammar, we observe a U-shaped learning pattern in several phenomena, similar to those observed in child language acquisition.
Do Large Language Models Understand Conversational Implicature -- A case study with a chinese sitcom
Apr 30, 2024Understanding the non-literal meaning of an utterance is critical for large language models (LLMs) to become human-like social communicators. In this work, we introduce SwordsmanImp, the first Chinese multi-turn-dialogue-based dataset aimed at conversational implicature, sourced from dialogues in the Chinese sitcom $\textit{My Own Swordsman}$. It includes 200 carefully handcrafted questions, all annotated on which Gricean maxims have been violated. We test eight close-source and open-source LLMs under two tasks: a multiple-choice question task and an implicature explanation task. Our results show that GPT-4 attains human-level accuracy (94%) on multiple-choice questions. CausalLM demonstrates a 78.5% accuracy following GPT-4. Other models, including GPT-3.5 and several open-source models, demonstrate a lower accuracy ranging from 20% to 60% on multiple-choice questions. Human raters were asked to rate the explanation of the implicatures generated by LLMs on their reasonability, logic and fluency. While all models generate largely fluent and self-consistent text, their explanations score low on reasonability except for GPT-4, suggesting that most LLMs cannot produce satisfactory explanations of the implicatures in the conversation. Moreover, we find LLMs' performance does not vary significantly by Gricean maxims, suggesting that LLMs do not seem to process implicatures derived from different maxims differently. Our data and code are available at https://github.com/sjtu-compling/llm-pragmatics.
Identifying Constitutive Parameters for Complex Hyperelastic Solids using Physics-Informed Neural Networks
Aug 29, 2023



Identifying constitutive parameters in engineering and biological materials, particularly those with intricate geometries and mechanical behaviors, remains a longstanding challenge. The recent advent of Physics-Informed Neural Networks (PINNs) offers promising solutions, but current frameworks are often limited to basic constitutive laws and encounter practical constraints when combined with experimental data. In this paper, we introduce a new PINN-based framework designed to identify material parameters for soft materials, specifically those exhibiting complex constitutive behaviors, under large deformation in plane stress conditions. Distinctively, our model emphasizes training PINNs with multi-modal time-dependent experimental datasets consisting of full-field deformation and loading history, ensuring algorithm robustness even amidst noisy data. Our results reveal that our framework can accurately identify constitutive parameters of the incompressible Arruda-Boyce model for samples with intricate geometries, maintaining an error below 5%, even with an experimental noise level of 5%. We believe our framework sets the stage for a transformative approach in modulus identification for complex solids, especially for those with geometrical and constitutive intricate.
Influence of Lossy Speech Codecs on Hearing-aid, Binaural Sound Source Localisation using DNNs
Jun 04, 2023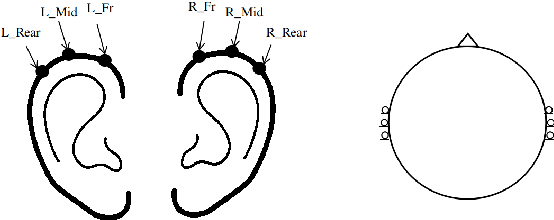

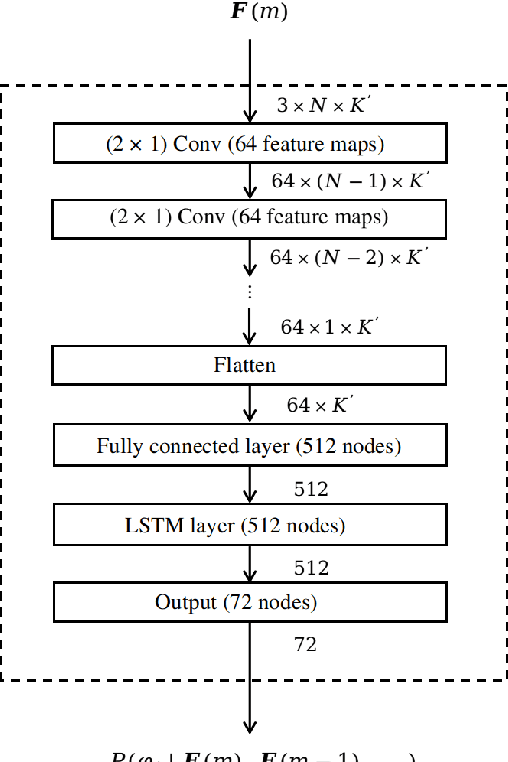
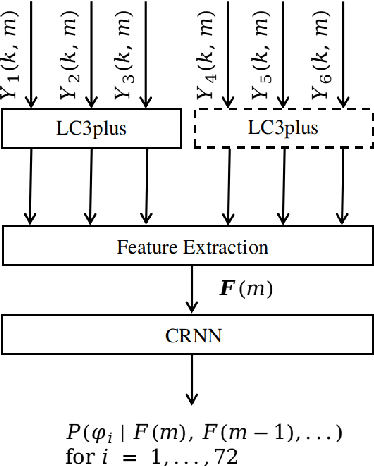
Hearing aids are typically equipped with multiple microphones to exploit spatial information for source localisation and speech enhancement. Especially for hearing aids, a good source localisation is important: it not only guides source separation methods but can also be used to enhance spatial cues, increasing user-awareness of important events in their surroundings. We use a state-of-the-art deep neural network (DNN) to perform binaural direction-of-arrival (DoA) estimation, where the DNN uses information from all microphones at both ears. However, hearing aids have limited bandwidth to exchange this data. Bluetooth low-energy (BLE) is emerging as an attractive option to facilitate such data exchange, with the LC3plus codec offering several bitrate and latency trade-off possibilities. In this paper, we investigate the effect of such lossy codecs on localisation accuracy. Specifically, we consider two conditions: processing at one ear vs processing at a central point, which influences the number of channels that need to be encoded. Performance is benchmarked against a baseline that allows full audio-exchange - yielding valuable insights into the usage of DNNs under lossy encoding. We also extend the Pyroomacoustics library to include hearing-device and head-related transfer functions (HD-HRTFs) to suitably train the networks. This can also benefit other researchers in the field.