 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLM-Scope: Mechanistic Interpretability of Diffusion Language Models via Sparse Autoencoders
Feb 05, 2026Sparse autoencoders (SAEs) have become a standard tool for mechanistic interpretability in autoregressive large language models (LLMs), enabling researchers to extract sparse, human-interpretable features and intervene on model behavior. Recently, as diffusion language models (DLMs) have become an increasingly promising alternative to the autoregressive LLMs, it is essential to develop tailored mechanistic interpretability tools for this emerging class of models. In this work, we present DLM-Scope, the first SAE-based interpretability framework for DLMs, and demonstrate that trained Top-K SAEs can faithfully extract interpretable features. Notably, we find that inserting SAEs affects DLMs differently than autoregressive LLMs: while SAE insertion in LLMs typically incurs a loss penalty, in DLMs it can reduce cross-entropy loss when applied to early layers, a phenomenon absent or markedly weaker in LLMs. Additionally, SAE features in DLMs enable more effective diffusion-time interventions, often outperforming LLM steering. Moreover, we pioneer certain new SAE-based research directions for DLMs: we show that SAEs can provide useful signals for DLM decoding order; and the SAE features are stable during the post-training phase of DLMs. Our work establishes a foundation for mechanistic interpretability in DLMs and shows a great potential of applying SAEs to DLM-related tasks and algorithms.
Qwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
Qwen3-TTS Technical Report
Jan 22, 2026In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis, coupled with two speech tokenizers: 1) Qwen-TTS-Tokenizer-25Hz is a single-codebook codec emphasizing semantic content, which offers seamlessly integration with Qwen-Audio and enables streaming waveform reconstruction via a block-wise DiT. 2) Qwen-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission ($97\,\mathrm{ms}$) through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Direct Simultaneous Translation Activation for Large Audio-Language Models
Sep 19, 2025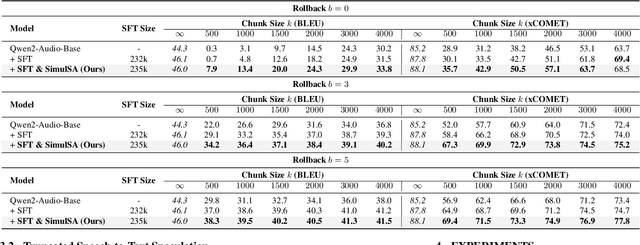
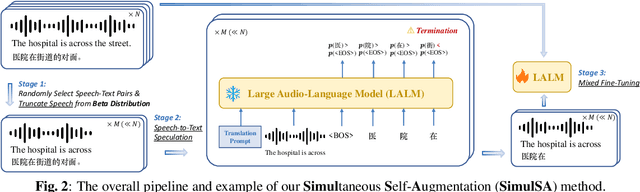

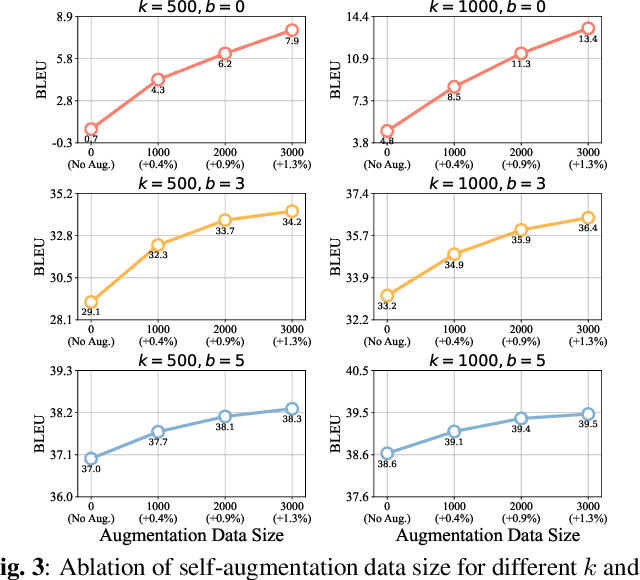
Simultaneous speech-to-text translation (Simul-S2TT) aims to translate speech into target text in real time, outputting translations while receiving source speech input, rather than waiting for the entire utterance to be spoken. Simul-S2TT research often modifies model architectures to implement read-write strategies. However, with the rise of large audio-language models (LALMs), a key challenge is how to directly activate Simul-S2TT capabilities in base models without additional architectural changes. In this paper, we introduce {\bf Simul}taneous {\bf S}elf-{\bf A}ugmentation ({\bf SimulSA}), a strategy that utilizes LALMs' inherent capabilities to obtain simultaneous data by randomly truncating speech and constructing partially aligned translation. By incorporating them into offline SFT data, SimulSA effectively bridges the distribution gap between offline translation during pretraining and simultaneous translation during inference. Experimental results demonstrate that augmenting only about {\bf 1\%} of the simultaneous data, compared to the full offline SFT data, can significantly activate LALMs' Simul-S2TT capabilities without modifications to model architecture or decoding strategy.
Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Jul 16, 2025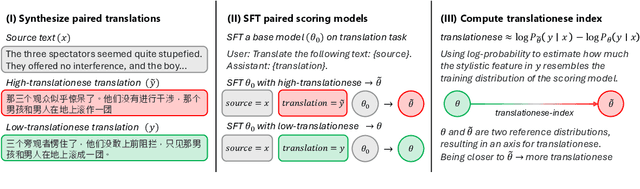
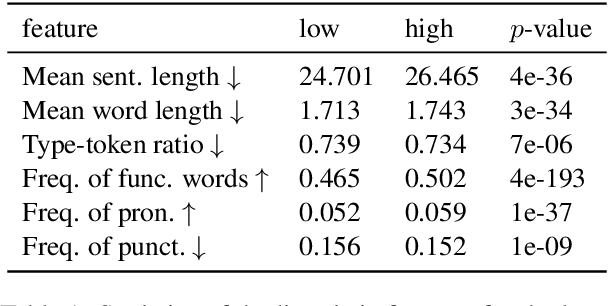
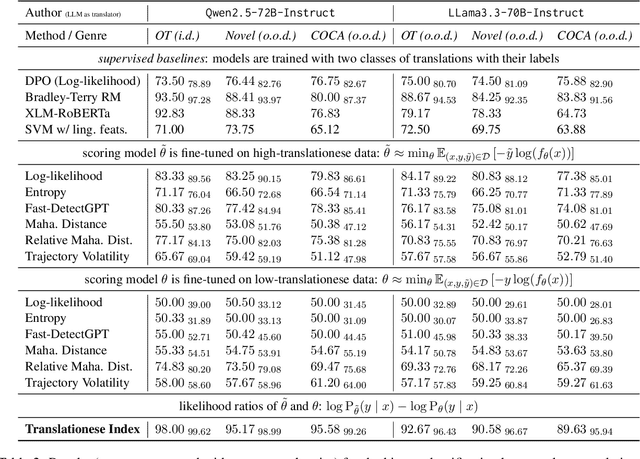
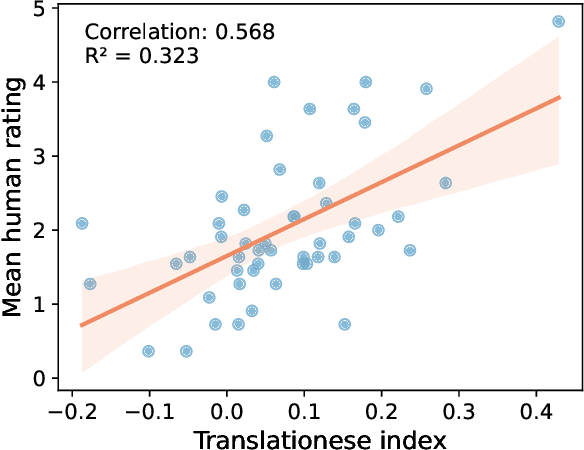
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Jun 05, 2025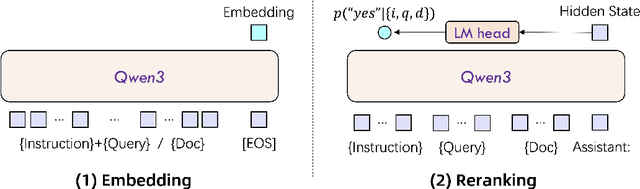
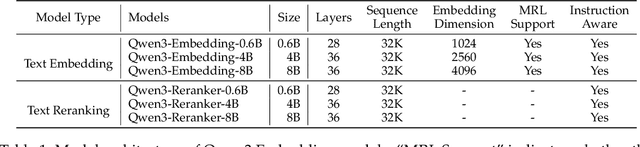

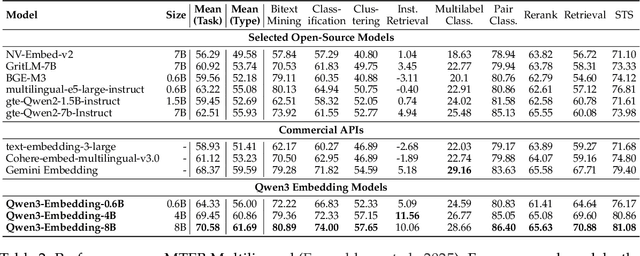
In this work, we introduce the Qwen3 Embedding series, a significant advancement over its predecessor, the GTE-Qwen series, in text embedding and reranking capabilities, built upon the Qwen3 foundation models. Leveraging the Qwen3 LLMs' robust capabilities in multilingual text understanding and generation, our innovative multi-stage training pipeline combines large-scale unsupervised pre-training with supervised fine-tuning on high-quality datasets. Effective model merging strategies further ensure the robustness and adaptability of the Qwen3 Embedding series. During the training process, the Qwen3 LLMs serve not only as backbone models but also play a crucial role in synthesizing high-quality, rich, and diverse training data across multiple domains and languages, thus enhancing the training pipeline. The Qwen3 Embedding series offers a spectrum of model sizes (0.6B, 4B, 8B) for both embedding and reranking tasks, addressing diverse deployment scenarios where users can optimize for either efficiency or effectiveness. Empirical evaluations demonstrate that the Qwen3 Embedding series achieves state-of-the-art results across diverse benchmarks. Notably, it excels on the multilingual evaluation benchmark MTEB for text embedding, as well as in various retrieval tasks, including code retrieval, cross-lingual retrieval and multilingual retrieval. To facilitate reproducibility and promote community-driven research and development, the Qwen3 Embedding models are publicly available under the Apache 2.0 license.
ConText: Driving In-context Learning for Text Removal and Segmentation
Jun 04, 2025This paper presents the first study on adapting the visual in-context learning (V-ICL) paradigm to optical character recognition tasks, specifically focusing on text removal and segmentation. Most existing V-ICL generalists employ a reasoning-as-reconstruction approach: they turn to using a straightforward image-label compositor as the prompt and query input, and then masking the query label to generate the desired output. This direct prompt confines the model to a challenging single-step reasoning process. To address this, we propose a task-chaining compositor in the form of image-removal-segmentation, providing an enhanced prompt that elicits reasoning with enriched intermediates. Additionally, we introduce context-aware aggregation, integrating the chained prompt pattern into the latent query representation, thereby strengthening the model's in-context reasoning. We also consider the issue of visual heterogeneity, which complicates the selection of homogeneous demonstrations in text recognition. Accordingly, this is effectively addressed through a simple self-prompting strategy, preventing the model's in-context learnability from devolving into specialist-like, context-free inference. Collectively, these insights culminate in our ConText model, which achieves new state-of-the-art across both in- and out-of-domain benchmarks. The code is available at https://github.com/Ferenas/ConText.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
May 08, 2025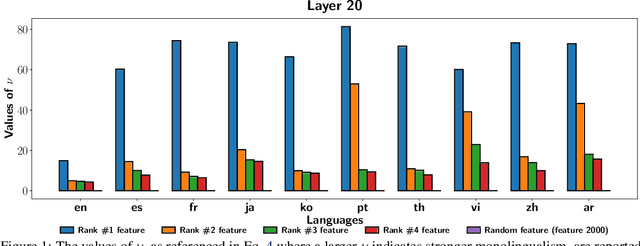
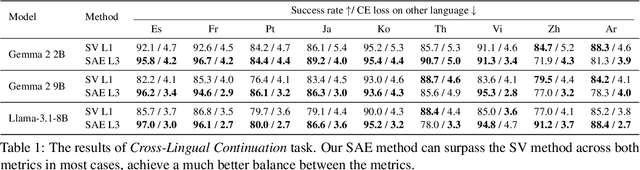
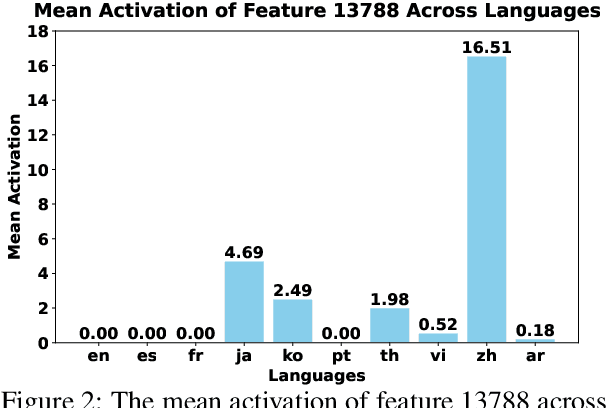
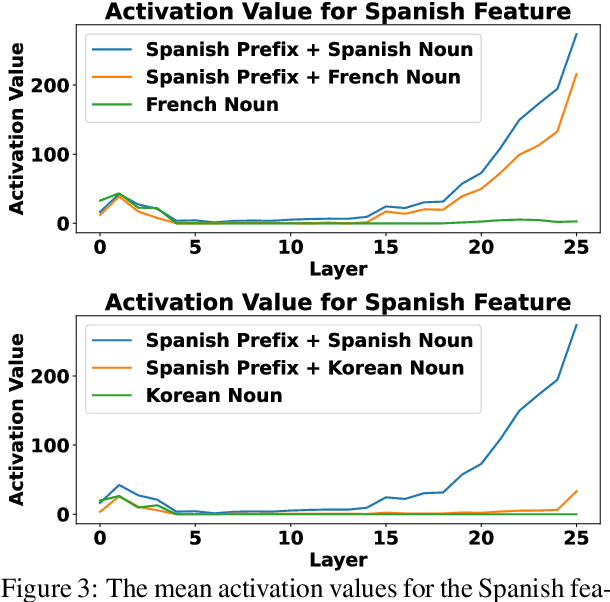
The mechanisms behind multilingual capabilities in Large Language Models (LLMs) have been examined using neuron-based or internal-activation-based methods. However, these methods often face challenges such as superposition and layer-wise activation variance, which limit their reliability. Sparse Autoencoders (SAEs) offer a more nuanced analysis by decomposing the activations of LLMs into sparse linear combination of SAE features. We introduce a novel metric to assess the monolinguality of features obtained from SAEs, discovering that some features are strongly related to specific languages. Additionally, we show that ablating these SAE features only significantly reduces abilities in one language of LLMs, leaving others almost unaffected. Interestingly, we find some languages have multiple synergistic SAE features, and ablating them together yields greater improvement than ablating individually. Moreover, we leverage these SAE-derived language-specific features to enhance steering vectors, achieving control over the language generated by LLMs.