 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Cross-lingual Values Assessment: A Consensus-Pluralism Perspective
Feb 19, 2026While large language models (LLMs) have become pivotal to content safety, current evaluation paradigms primarily focus on detecting explicit harms (e.g., violence or hate speech), neglecting the subtler value dimensions conveyed in digital content. To bridge this gap, we introduce X-Value, a novel Cross-lingual Values Assessment Benchmark designed to evaluate LLMs' ability to assess deep-level values of content from a global perspective. X-Value consists of more than 5,000 QA pairs across 18 languages, systematically organized into 7 core domains grounded in Schwartz's Theory of Basic Human Values and categorized into easy and hard levels for discriminative evaluation. We further propose a unique two-stage annotation framework that first identifies whether an issue falls under global consensus (e.g., human rights) or pluralism (e.g., religion), and subsequently conducts a multi-party evaluation of the latent values embedded within the content. Systematic evaluations on X-Value reveal that current SOTA LLMs exhibit deficiencies in cross-lingual values assessment ($Acc < 77\%$), with significant performance disparities across different languages ($ΔAcc > 20\%$). This work highlights the urgent need to improve the nuanced, values-aware content assessment capability of LLMs. Our X-Value is available at: https://huggingface.co/datasets/Whitolf/X-Value.
DLM-Scope: Mechanistic Interpretability of Diffusion Language Models via Sparse Autoencoders
Feb 05, 2026Sparse autoencoders (SAEs) have become a standard tool for mechanistic interpretability in autoregressive large language models (LLMs), enabling researchers to extract sparse, human-interpretable features and intervene on model behavior. Recently, as diffusion language models (DLMs) have become an increasingly promising alternative to the autoregressive LLMs, it is essential to develop tailored mechanistic interpretability tools for this emerging class of models. In this work, we present DLM-Scope, the first SAE-based interpretability framework for DLMs, and demonstrate that trained Top-K SAEs can faithfully extract interpretable features. Notably, we find that inserting SAEs affects DLMs differently than autoregressive LLMs: while SAE insertion in LLMs typically incurs a loss penalty, in DLMs it can reduce cross-entropy loss when applied to early layers, a phenomenon absent or markedly weaker in LLMs. Additionally, SAE features in DLMs enable more effective diffusion-time interventions, often outperforming LLM steering. Moreover, we pioneer certain new SAE-based research directions for DLMs: we show that SAEs can provide useful signals for DLM decoding order; and the SAE features are stable during the post-training phase of DLMs. Our work establishes a foundation for mechanistic interpretability in DLMs and shows a great potential of applying SAEs to DLM-related tasks and algorithms.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
May 08, 2025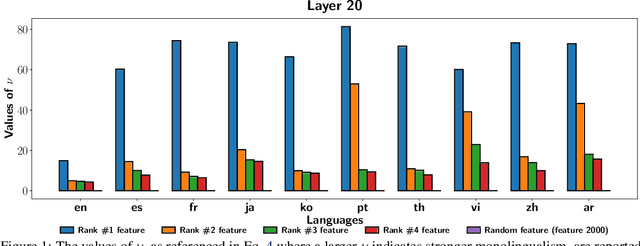
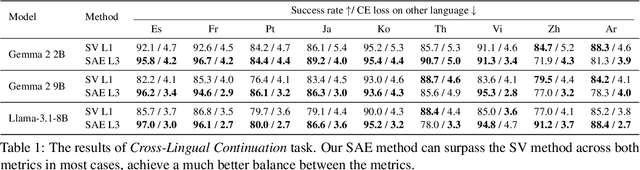
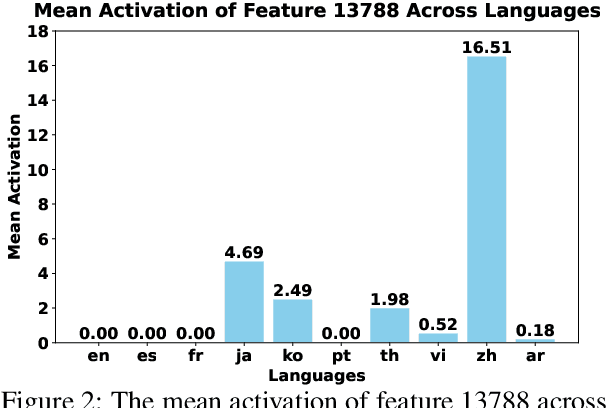
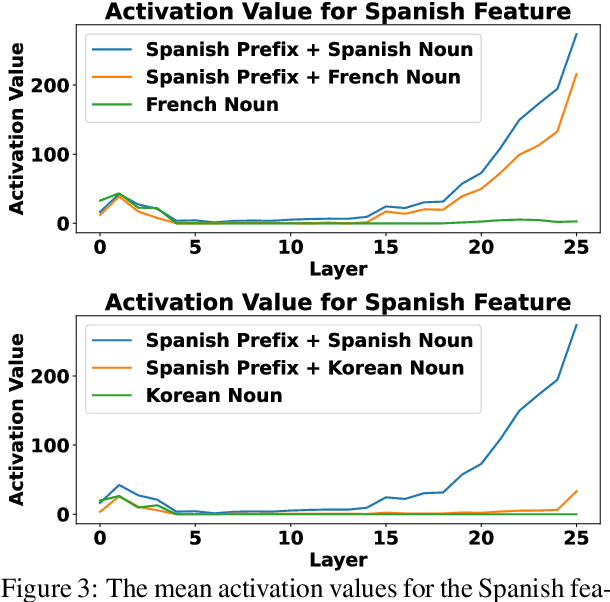
The mechanisms behind multilingual capabilities in Large Language Models (LLMs) have been examined using neuron-based or internal-activation-based methods. However, these methods often face challenges such as superposition and layer-wise activation variance, which limit their reliability. Sparse Autoencoders (SAEs) offer a more nuanced analysis by decomposing the activations of LLMs into sparse linear combination of SAE features. We introduce a novel metric to assess the monolinguality of features obtained from SAEs, discovering that some features are strongly related to specific languages. Additionally, we show that ablating these SAE features only significantly reduces abilities in one language of LLMs, leaving others almost unaffected. Interestingly, we find some languages have multiple synergistic SAE features, and ablating them together yields greater improvement than ablating individually. Moreover, we leverage these SAE-derived language-specific features to enhance steering vectors, achieving control over the language generated by LLMs.
Qwen2.5 Technical Report
Dec 19, 2024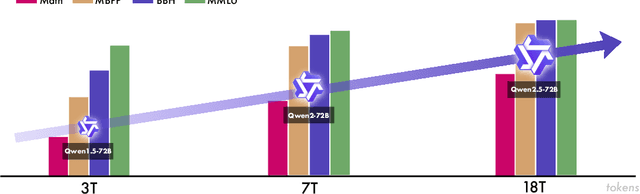

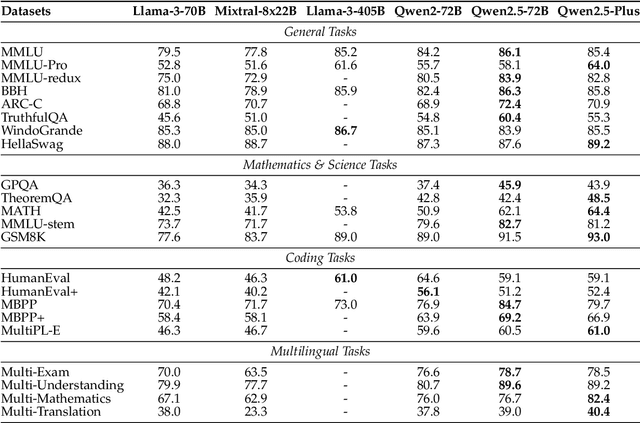
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
P-MMEval: A Parallel Multilingual Multitask Benchmark for Consistent Evaluation of LLMs
Nov 14, 2024
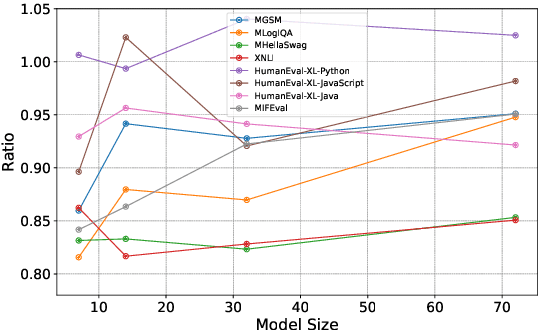


Recent advancements in large language models (LLMs) showcase varied multilingual capabilities across tasks like translation, code generation, and reasoning. Previous assessments often limited their scope to fundamental natural language processing (NLP) or isolated capability-specific tasks. To alleviate this drawback, we aim to present a comprehensive multilingual multitask benchmark. First, we present a pipeline for selecting available and reasonable benchmarks from massive ones, addressing the oversight in previous work regarding the utility of these benchmarks, i.e., their ability to differentiate between models being evaluated. Leveraging this pipeline, we introduce P-MMEval, a large-scale benchmark covering effective fundamental and capability-specialized datasets. Furthermore, P-MMEval delivers consistent language coverage across various datasets and provides parallel samples. Finally, we conduct extensive experiments on representative multilingual model series to compare performances across models, analyze dataset effectiveness, examine prompt impacts on model performances, and explore the relationship between multilingual performances and factors such as tasks, model sizes, and languages. These insights offer valuable guidance for future research. The dataset is available at https://huggingface.co/datasets/Qwen/P-MMEval.
Qwen2 Technical Report
Jul 16, 2024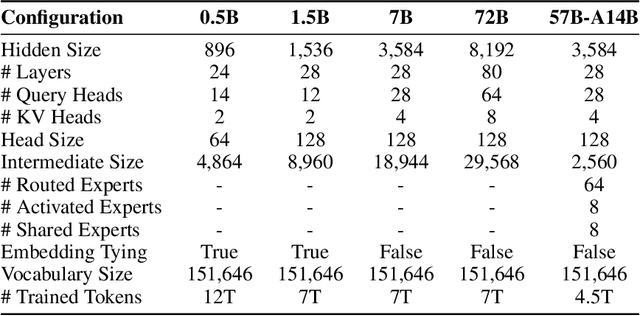
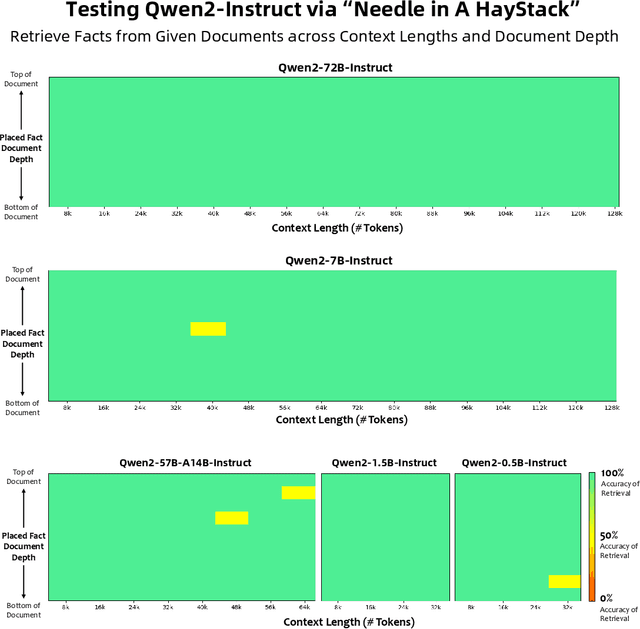
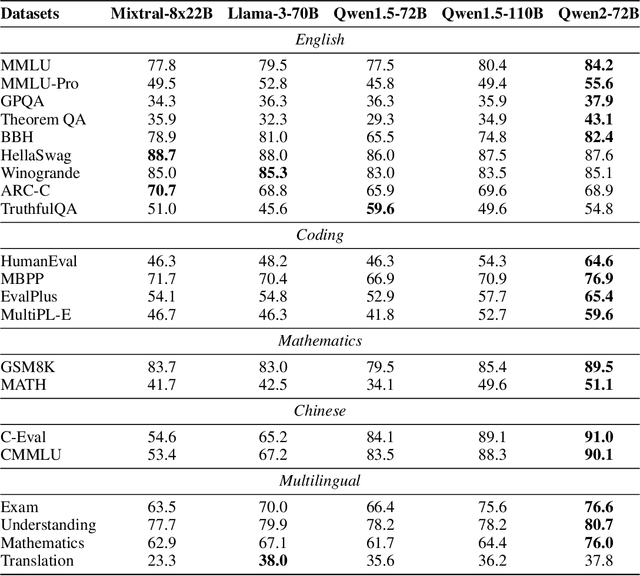
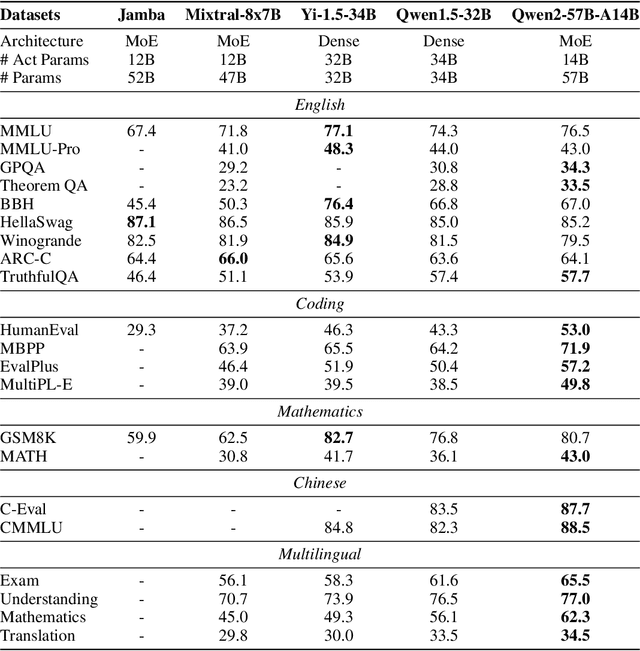
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
A Unified Framework for Multimodal, Multi-Part Human Motion Synthesis
Nov 28, 2023The field has made significant progress in synthesizing realistic human motion driven by various modalities. Yet, the need for different methods to animate various body parts according to different control signals limits the scalability of these techniques in practical scenarios. In this paper, we introduce a cohesive and scalable approach that consolidates multimodal (text, music, speech) and multi-part (hand, torso) human motion generation. Our methodology unfolds in several steps: We begin by quantizing the motions of diverse body parts into separate codebooks tailored to their respective domains. Next, we harness the robust capabilities of pre-trained models to transcode multimodal signals into a shared latent space. We then translate these signals into discrete motion tokens by iteratively predicting subsequent tokens to form a complete sequence. Finally, we reconstruct the continuous actual motion from this tokenized sequence. Our method frames the multimodal motion generation challenge as a token prediction task, drawing from specialized codebooks based on the modality of the control signal. This approach is inherently scalable, allowing for the easy integration of new modalities. Extensive experiments demonstrated the effectiveness of our design, emphasizing its potential for broad application.
AvatarGPT: All-in-One Framework for Motion Understanding, Planning, Generation and Beyond
Nov 28, 2023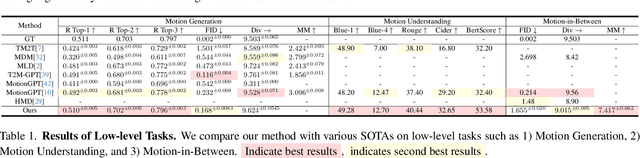
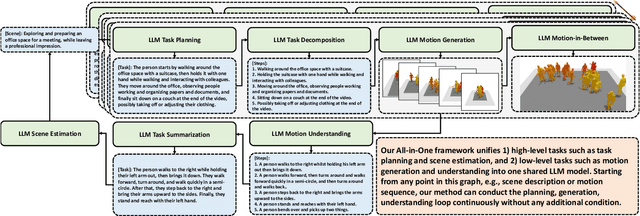
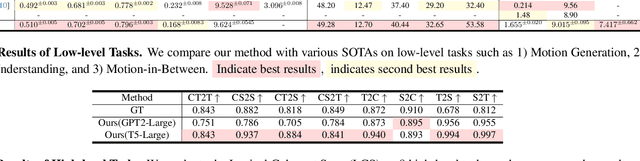

Large Language Models(LLMs) have shown remarkable emergent abilities in unifying almost all (if not every) NLP tasks. In the human motion-related realm, however, researchers still develop siloed models for each task. Inspired by InstuctGPT, and the generalist concept behind Gato, we introduce AvatarGPT, an All-in-One framework for motion understanding, planning, generations as well as other tasks such as motion in-between synthesis. AvatarGPT treats each task as one type of instruction fine-tuned on the shared LLM. All the tasks are seamlessly interconnected with language as the universal interface, constituting a closed-loop within the framework. To achieve this, human motion sequences are first encoded as discrete tokens, which serve as the extended vocabulary of LLM. Then, an unsupervised pipeline to generate natural language descriptions of human action sequences from in-the-wild videos is developed. Finally, all tasks are jointly trained. Extensive experiments show that AvatarGPT achieves SOTA on low-level tasks, and promising results on high-level tasks, demonstrating the effectiveness of our proposed All-in-One framework. Moreover, for the first time, AvatarGPT enables a principled approach by iterative traversal of the tasks within the closed-loop for unlimited long-motion synthesis.