 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-Efficient and Stable Reinforcement Learning for LLM-based Recommendation
Jan 31, 2026While Long Chain-of-Thought (Long CoT) reasoning has shown promise in Large Language Models (LLMs), its adoption for enhancing recommendation quality is growing rapidly. In this work, we critically examine this trend and argue that Long CoT is inherently ill-suited for the sequential recommendation domain. We attribute this misalignment to two primary factors: excessive inference latency and the lack of explicit cognitive reasoning patterns in user behavioral data. Driven by these observations, we propose pivoting away from the CoT structure to directly leverage its underlying mechanism: Reinforcement Learning (RL), to explore the item space. However, applying RL directly faces significant obstacles, notably low sample efficiency-where most actions fail to provide learning signals-and training instability. To overcome these limitations, we propose RISER, a novel Reinforced Item Space Exploration framework for Recommendation. RISER is designed to transform non-learnable trajectories into effective pairwise preference data for optimization. Furthermore, it incorporates specific strategies to ensure stability, including the prevention of redundant rollouts and the constraint of token-level update magnitudes. Extensive experiments on three real-world datasets show that RISER significantly outperforms competitive baselines, establishing a robust paradigm for RL-enhanced LLM recommendation. Our code will be available at https://anonymous.4open.science/r/RISER/.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025


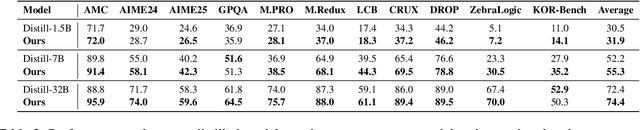
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Jul 09, 2025LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model's performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
MTR-Bench: A Comprehensive Benchmark for Multi-Turn Reasoning Evaluation
May 26, 2025Recent advances in Large Language Models (LLMs) have shown promising results in complex reasoning tasks. However, current evaluations predominantly focus on single-turn reasoning scenarios, leaving interactive tasks largely unexplored. We attribute it to the absence of comprehensive datasets and scalable automatic evaluation protocols. To fill these gaps, we present MTR-Bench for LLMs' Multi-Turn Reasoning evaluation. Comprising 4 classes, 40 tasks, and 3600 instances, MTR-Bench covers diverse reasoning capabilities, fine-grained difficulty granularity, and necessitates multi-turn interactions with the environments. Moreover, MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations, which enables scalable assessment without human interventions. Extensive experiments reveal that even the cutting-edge reasoning models fall short of multi-turn, interactive reasoning tasks. And the further analysis upon these results brings valuable insights for future research in interactive AI systems.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
HellaSwag-Pro: A Large-Scale Bilingual Benchmark for Evaluating the Robustness of LLMs in Commonsense Reasoning
Feb 17, 2025Large language models (LLMs) have shown remarkable capabilities in commonsense reasoning; however, some variations in questions can trigger incorrect responses. Do these models truly understand commonsense knowledge, or just memorize expression patterns? To investigate this question, we present the first extensive robustness evaluation of LLMs in commonsense reasoning. We introduce HellaSwag-Pro, a large-scale bilingual benchmark consisting of 11,200 cases, by designing and compiling seven types of question variants. To construct this benchmark, we propose a two-stage method to develop Chinese HellaSwag, a finely annotated dataset comprising 12,000 instances across 56 categories. We conduct extensive experiments on 41 representative LLMs, revealing that these LLMs are far from robust in commonsense reasoning. Furthermore, this robustness varies depending on the language in which the LLM is tested. This work establishes a high-quality evaluation benchmark, with extensive experiments offering valuable insights to the community in commonsense reasoning for LLMs.
Qwen2.5 Technical Report
Dec 19, 2024

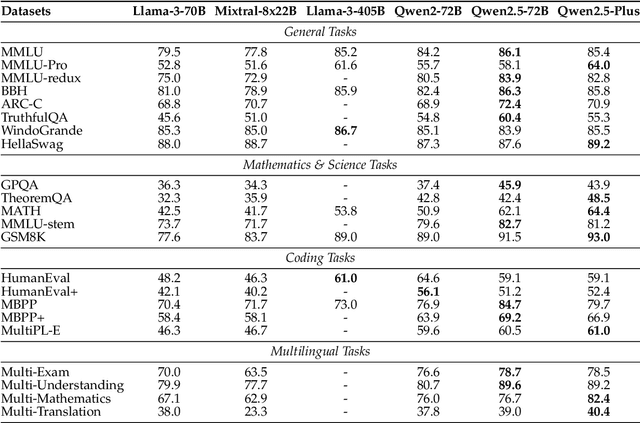
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
Causality-Enhanced Behavior Sequence Modeling in LLMs for Personalized Recommendation
Oct 30, 2024



Recent advancements in recommender systems have focused on leveraging Large Language Models (LLMs) to improve user preference modeling, yielding promising outcomes. However, current LLM-based approaches struggle to fully leverage user behavior sequences, resulting in suboptimal preference modeling for personalized recommendations. In this study, we propose a novel Counterfactual Fine-Tuning (CFT) method to address this issue by explicitly emphasizing the role of behavior sequences when generating recommendations. Specifically, we employ counterfactual reasoning to identify the causal effects of behavior sequences on model output and introduce a task that directly fits the ground-truth labels based on these effects, achieving the goal of explicit emphasis. Additionally, we develop a token-level weighting mechanism to adjust the emphasis strength for different item tokens, reflecting the diminishing influence of behavior sequences from earlier to later tokens during predicting an item. Extensive experiments on real-world datasets demonstrate that CFT effectively improves behavior sequence modeling. Our codes are available at https://github.com/itsmeyjt/CFT.
Real-Time Personalization for LLM-based Recommendation with Customized In-Context Learning
Oct 30, 2024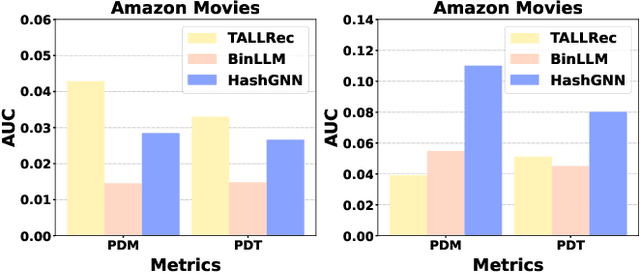

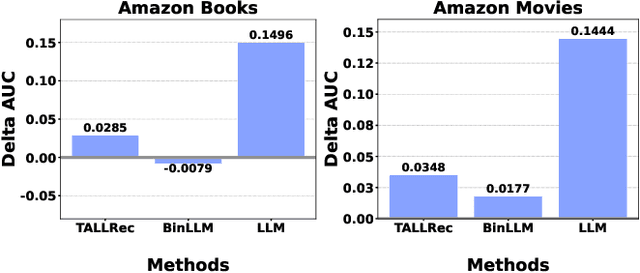

Frequently updating Large Language Model (LLM)-based recommender systems to adapt to new user interests -- as done for traditional ones -- is impractical due to high training costs, even with acceleration methods. This work explores adapting to dynamic user interests without any model updates by leveraging In-Context Learning (ICL), which allows LLMs to learn new tasks from few-shot examples provided in the input. Using new-interest examples as the ICL few-shot examples, LLMs may learn real-time interest directly, avoiding the need for model updates. However, existing LLM-based recommenders often lose the in-context learning ability during recommendation tuning, while the original LLM's in-context learning lacks recommendation-specific focus. To address this, we propose RecICL, which customizes recommendation-specific in-context learning for real-time recommendations. RecICL organizes training examples in an in-context learning format, ensuring that in-context learning ability is preserved and aligned with the recommendation task during tuning. Extensive experiments demonstrate RecICL's effectiveness in delivering real-time recommendations without requiring model updates. Our code is available at https://github.com/ym689/rec_icl.