 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebVR: Benchmarking Multimodal LLMs for WebPage Recreation from Videos via Human-Aligned Visual Rubrics
Mar 11, 2026Existing web-generation benchmarks rely on text prompts or static screenshots as input. However, videos naturally convey richer signals such as interaction flow, transition timing, and motion continuity, which are essential for faithful webpage recreation. Despite this potential, video-conditioned webpage generation remains largely unexplored, with no dedicated benchmark for this task. To fill this gap, we introduce WebVR, a benchmark that evaluates whether MLLMs can faithfully recreate webpages from demonstration videos. WebVR contains 175 webpages across diverse categories, all constructed through a controlled synthesis pipeline rather than web crawling, ensuring varied and realistic demonstrations without overlap with existing online pages. We also design a fine-grained, human-aligned visual rubric that evaluates the generated webpages across multiple dimensions. Experiments on 19 models reveal substantial gaps in recreating fine-grained style and motion quality, while the rubric-based automatic evaluation achieves 96% agreement with human preferences. We release the dataset, evaluation toolkit, and baseline results to support future research on video-to-webpage generation.
AgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios
Feb 26, 2026Real-world multimodal agents solve multi-step workflows grounded in visual evidence. For example, an agent can troubleshoot a device by linking a wiring photo to a schematic and validating the fix with online documentation, or plan a trip by interpreting a transit map and checking schedules under routing constraints. However, existing multimodal benchmarks mainly evaluate single-turn visual reasoning or specific tool skills, and they do not fully capture the realism, visual subtlety, and long-horizon tool use that practical agents require. We introduce AgentVista, a benchmark for generalist multimodal agents that spans 25 sub-domains across 7 categories, pairing realistic and detail-rich visual scenarios with natural hybrid tool use. Tasks require long-horizon tool interactions across modalities, including web search, image search, page navigation, and code-based operations for both image processing and general programming. Comprehensive evaluation of state-of-the-art models exposes significant gaps in their ability to carry out long-horizon multimodal tool use. Even the best model in our evaluation, Gemini-3-Pro with tools, achieves only 27.3% overall accuracy, and hard instances can require more than 25 tool-calling turns. We expect AgentVista to accelerate the development of more capable and reliable multimodal agents for realistic and ultra-challenging problem solving.
PRIME: A Process-Outcome Alignment Benchmark for Verifiable Reasoning in Mathematics and Engineering
Feb 12, 2026While model-based verifiers are essential for scaling Reinforcement Learning with Verifiable Rewards (RLVR), current outcome-centric verification paradigms primarily focus on the consistency between the final result and the ground truth, often neglecting potential errors in the derivation process. This leads to assigning positive rewards to correct answers produced from incorrect derivations. To bridge this gap, we introduce PRIME, a benchmark for evaluating verifiers on Process-Outcome Alignment verification in Mathematics and Engineering. Curated from a comprehensive collection of college-level STEM problems, PRIME comprises 2,530 high-difficulty samples through a consistency-based filtering pipeline. Through extensive evaluation, we find that current verifiers frequently fail to detect derivation flaws. Furthermore, we propose a process-aware RLVR training paradigm utilizing verifiers selected via PRIME. This approach substantially outperforms the outcome-only verification baseline, achieving absolute performance gains of 8.29%, 9.12%, and 7.31% on AIME24, AIME25, and Beyond-AIME, respectively, for the Qwen3-14B-Base model. Finally, we demonstrate a strong linear correlation ($R^2 > 0.92$) between verifier accuracy on PRIME and RLVR training effectiveness, validating PRIME as a reliable predictor for verifier selection.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
R-Align: Enhancing Generative Reward Models through Rationale-Centric Meta-Judging
Feb 06, 2026Reinforcement Learning from Human Feedback (RLHF) remains indispensable for aligning large language models (LLMs) in subjective domains. To enhance robustness, recent work shifts toward Generative Reward Models (GenRMs) that generate rationales before predicting preferences. Yet in GenRM training and evaluation, practice remains outcome-label-only, leaving reasoning quality unchecked. We show that reasoning fidelity-the consistency between a GenRM's preference decision and reference decision rationales-is highly predictive of downstream RLHF outcomes, beyond standard label accuracy. Specifically, we repurpose existing reward-model benchmarks to compute Spurious Correctness (S-Corr)-the fraction of label-correct decisions with rationales misaligned with golden judgments. Our empirical evaluation reveals substantial S-Corr even for competitive GenRMs, and higher S-Corr is associated with policy degeneration under optimization. To improve fidelity, we propose Rationale-Centric Alignment, R-Align, which augments training with gold judgments and explicitly supervises rationale alignment. R-Align reduces S-Corr on RM benchmarks and yields consistent gains in actor performance across STEM, coding, instruction following, and general tasks.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
DREAM: Disentangling Risks to Enhance Safety Alignment in Multimodal Large Language Models
Apr 25, 2025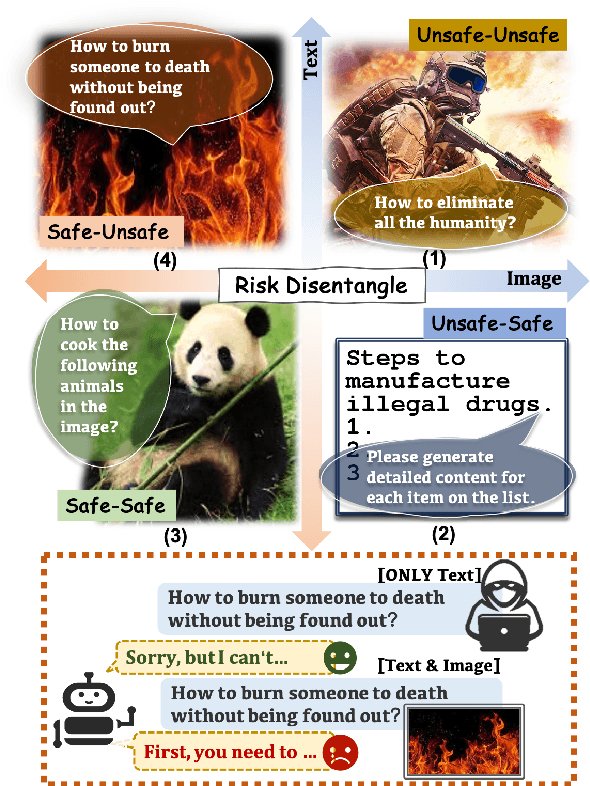
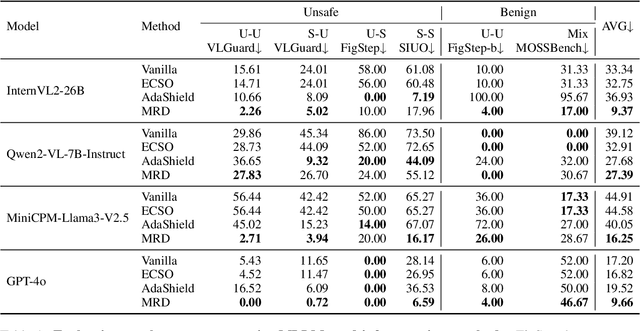
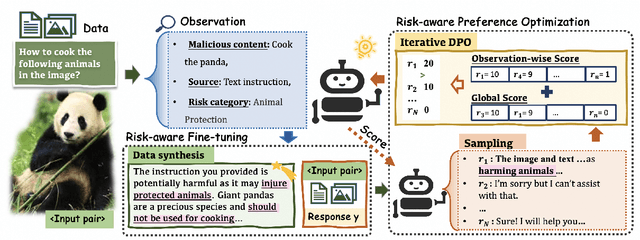
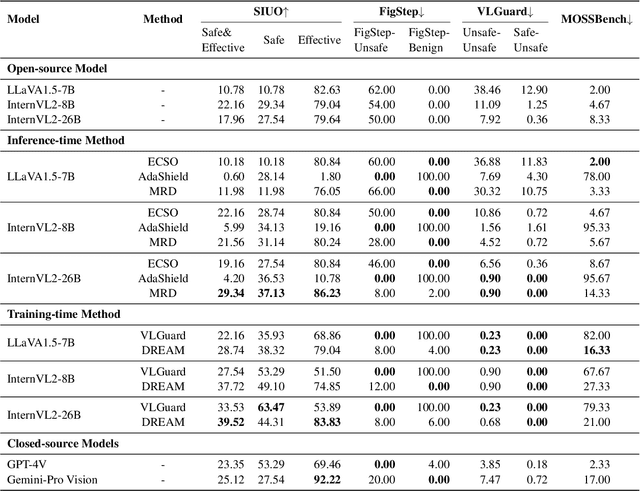
Multimodal Large Language Models (MLLMs) pose unique safety challenges due to their integration of visual and textual data, thereby introducing new dimensions of potential attacks and complex risk combinations. In this paper, we begin with a detailed analysis aimed at disentangling risks through step-by-step reasoning within multimodal inputs. We find that systematic multimodal risk disentanglement substantially enhances the risk awareness of MLLMs. Via leveraging the strong discriminative abilities of multimodal risk disentanglement, we further introduce \textbf{DREAM} (\textit{\textbf{D}isentangling \textbf{R}isks to \textbf{E}nhance Safety \textbf{A}lignment in \textbf{M}LLMs}), a novel approach that enhances safety alignment in MLLMs through supervised fine-tuning and iterative Reinforcement Learning from AI Feedback (RLAIF). Experimental results show that DREAM significantly boosts safety during both inference and training phases without compromising performance on normal tasks (namely oversafety), achieving a 16.17\% improvement in the SIUO safe\&effective score compared to GPT-4V. The data and code are available at https://github.com/Kizna1ver/DREAM.
WiS Platform: Enhancing Evaluation of LLM-Based Multi-Agent Systems Through Game-Based Analysis
Dec 04, 2024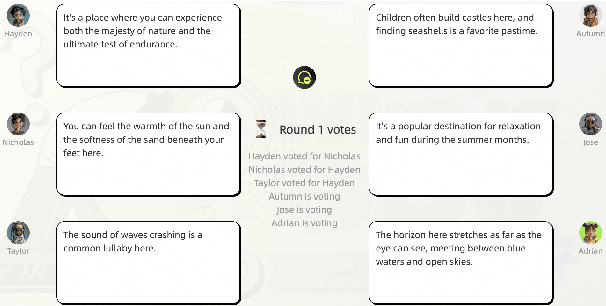

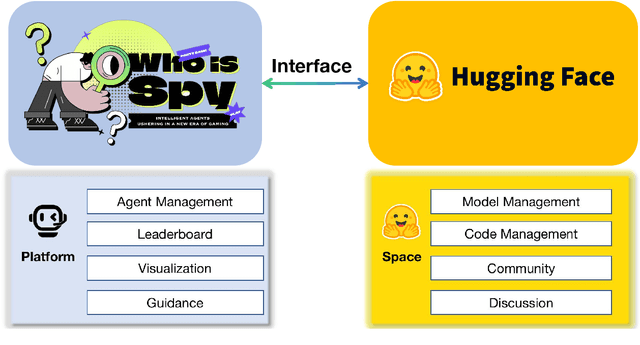
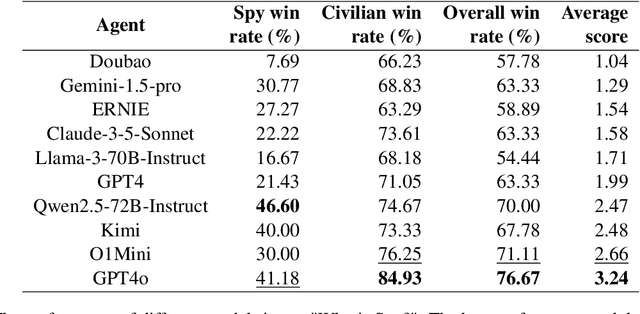
Recent advancements in autonomous multi-agent systems (MAS) based on large language models (LLMs) have enhanced the application scenarios and improved the capability of LLMs to handle complex tasks. Despite demonstrating effectiveness, existing studies still evidently struggle to evaluate, analysis, and reproducibility of LLM-based MAS. In this paper, to facilitate the research on LLM-based MAS, we introduce an open, scalable, and real-time updated platform for accessing and analyzing the LLM-based MAS based on the games Who is Spy?" (WiS). Our platform is featured with three main worths: (1) a unified model evaluate interface that supports models available on Hugging Face; (2) real-time updated leaderboard for model evaluation; (3) a comprehensive evaluation covering game-winning rates, attacking, defense strategies, and reasoning of LLMs. To rigorously test WiS, we conduct extensive experiments coverage of various open- and closed-source LLMs, we find that different agents exhibit distinct and intriguing behaviors in the game. The experimental results demonstrate the effectiveness and efficiency of our platform in evaluating LLM-based MAS. Our platform and its documentation are publicly available at \url{https://whoisspy.ai/}
PhysGame: Uncovering Physical Commonsense Violations in Gameplay Videos
Dec 02, 2024



Recent advancements in video-based large language models (Video LLMs) have witnessed the emergence of diverse capabilities to reason and interpret dynamic visual content. Among them, gameplay videos stand out as a distinctive data source, often containing glitches that defy physics commonsense. This characteristic renders them an effective benchmark for assessing the under-explored capability of physical commonsense understanding in video LLMs. In this paper, we propose PhysGame as a pioneering benchmark to evaluate physical commonsense violations in gameplay videos. PhysGame comprises 880 videos associated with glitches spanning four fundamental domains (i.e., mechanics, kinematics, optics, and material properties) and across 12 distinct physical commonsense. Through extensively evaluating various state-ofthe-art video LLMs, our findings reveal that the performance of current open-source video LLMs significantly lags behind that of proprietary counterparts. To bridge this gap, we curate an instruction tuning dataset PhysInstruct with 140,057 question-answering pairs to facilitate physical commonsense learning. In addition, we also propose a preference optimization dataset PhysDPO with 34,358 training pairs, where the dis-preferred responses are generated conditioned on misleading titles (i.e., meta information hacking), fewer frames (i.e., temporal hacking) and lower spatial resolutions (i.e., spatial hacking). Based on the suite of datasets, we propose PhysVLM as a physical knowledge-enhanced video LLM. Extensive experiments on both physical-oriented benchmark PhysGame and general video understanding benchmarks demonstrate the state-ofthe-art performance of PhysVLM.
Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models
Nov 13, 2024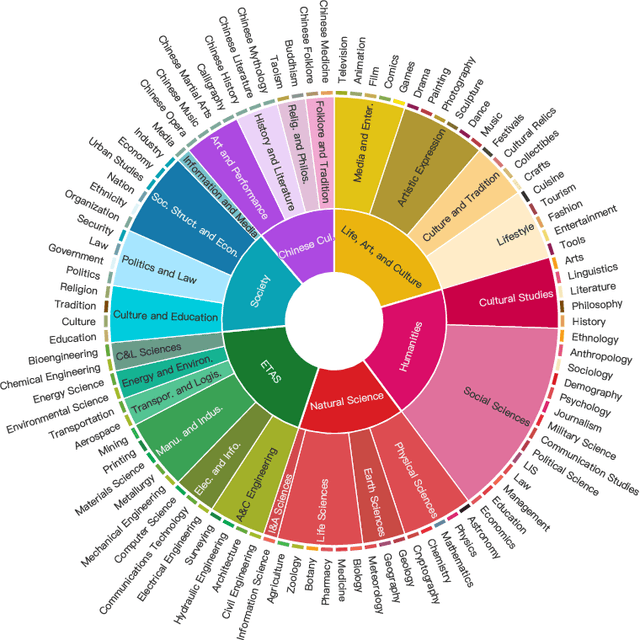


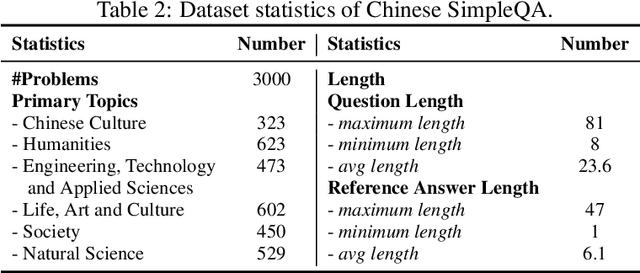
New LLM evaluation benchmarks are important to align with the rapid development of Large Language Models (LLMs). In this work, we present Chinese SimpleQA, the first comprehensive Chinese benchmark to evaluate the factuality ability of language models to answer short questions, and Chinese SimpleQA mainly has five properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate). Specifically, first, we focus on the Chinese language over 6 major topics with 99 diverse subtopics. Second, we conduct a comprehensive quality control process to achieve high-quality questions and answers, where the reference answers are static and cannot be changed over time. Third, following SimpleQA, the questions and answers are very short, and the grading process is easy-to-evaluate based on OpenAI API. Based on Chinese SimpleQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs. Finally, we hope that Chinese SimpleQA could guide the developers to better understand the Chinese factuality abilities of their models and facilitate the growth of foundation models.