 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink before Recommendation: Autonomous Reasoning-enhanced Recommender
Oct 27, 2025The core task of recommender systems is to learn user preferences from historical user-item interactions. With the rapid development of large language models (LLMs), recent research has explored leveraging the reasoning capabilities of LLMs to enhance rating prediction tasks. However, existing distillation-based methods suffer from limitations such as the teacher model's insufficient recommendation capability, costly and static supervision, and superficial transfer of reasoning ability. To address these issues, this paper proposes RecZero, a reinforcement learning (RL)-based recommendation paradigm that abandons the traditional multi-model and multi-stage distillation approach. Instead, RecZero trains a single LLM through pure RL to autonomously develop reasoning capabilities for rating prediction. RecZero consists of two key components: (1) "Think-before-Recommendation" prompt construction, which employs a structured reasoning template to guide the model in step-wise analysis of user interests, item features, and user-item compatibility; and (2) rule-based reward modeling, which adopts group relative policy optimization (GRPO) to compute rewards for reasoning trajectories and optimize the LLM. Additionally, the paper explores a hybrid paradigm, RecOne, which combines supervised fine-tuning with RL, initializing the model with cold-start reasoning samples and further optimizing it with RL. Experimental results demonstrate that RecZero and RecOne significantly outperform existing baseline methods on multiple benchmark datasets, validating the superiority of the RL paradigm in achieving autonomous reasoning-enhanced recommender systems.
Large Language Models Are Universal Recommendation Learners
Feb 05, 2025



In real-world recommender systems, different tasks are typically addressed using supervised learning on task-specific datasets with carefully designed model architectures. We demonstrate that large language models (LLMs) can function as universal recommendation learners, capable of handling multiple tasks within a unified input-output framework, eliminating the need for specialized model designs. To improve the recommendation performance of LLMs, we introduce a multimodal fusion module for item representation and a sequence-in-set-out approach for efficient candidate generation. When applied to industrial-scale data, our LLM achieves competitive results with expert models elaborately designed for different recommendation tasks. Furthermore, our analysis reveals that recommendation outcomes are highly sensitive to text input, highlighting the potential of prompt engineering in optimizing industrial-scale recommender systems.
WiS Platform: Enhancing Evaluation of LLM-Based Multi-Agent Systems Through Game-Based Analysis
Dec 04, 2024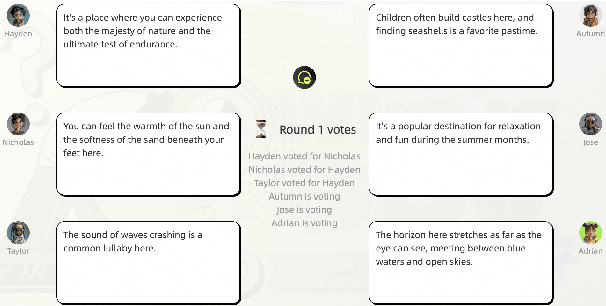

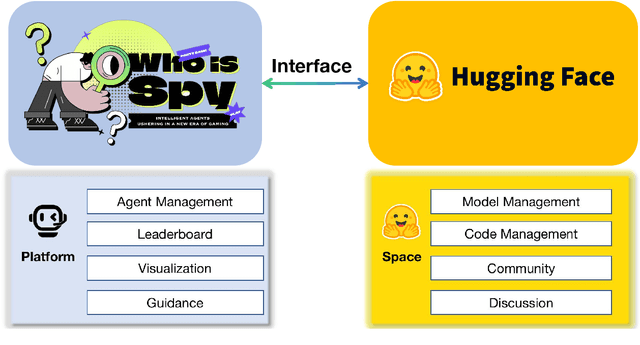
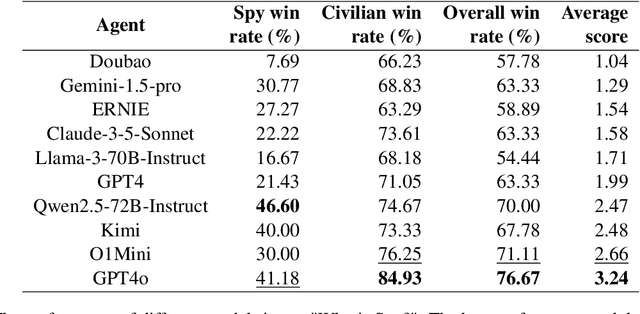
Recent advancements in autonomous multi-agent systems (MAS) based on large language models (LLMs) have enhanced the application scenarios and improved the capability of LLMs to handle complex tasks. Despite demonstrating effectiveness, existing studies still evidently struggle to evaluate, analysis, and reproducibility of LLM-based MAS. In this paper, to facilitate the research on LLM-based MAS, we introduce an open, scalable, and real-time updated platform for accessing and analyzing the LLM-based MAS based on the games Who is Spy?" (WiS). Our platform is featured with three main worths: (1) a unified model evaluate interface that supports models available on Hugging Face; (2) real-time updated leaderboard for model evaluation; (3) a comprehensive evaluation covering game-winning rates, attacking, defense strategies, and reasoning of LLMs. To rigorously test WiS, we conduct extensive experiments coverage of various open- and closed-source LLMs, we find that different agents exhibit distinct and intriguing behaviors in the game. The experimental results demonstrate the effectiveness and efficiency of our platform in evaluating LLM-based MAS. Our platform and its documentation are publicly available at \url{https://whoisspy.ai/}
ForkMerge: Overcoming Negative Transfer in Multi-Task Learning
Jan 30, 2023The goal of multi-task learning is to utilize useful knowledge from multiple related tasks to improve the generalization performance of all tasks. However, learning multiple tasks simultaneously often results in worse performance than learning them independently, which is known as negative transfer. Most previous works attribute negative transfer in multi-task learning to gradient conflicts between different tasks and propose several heuristics to manipulate the task gradients for mitigating this problem, which mainly considers the optimization difficulty and overlooks the generalization problem. To fully understand the root cause of negative transfer, we experimentally analyze negative transfer from the perspectives of optimization, generalization, and hypothesis space. Stemming from our analysis, we introduce ForkMerge, which periodically forks the model into multiple branches with different task weights, and merges dynamically to filter out detrimental parameter updates to avoid negative transfer. On a series of multi-task learning tasks, ForkMerge achieves improved performance over state-of-the-art methods and largely avoids negative transfer.
Debiased Pseudo Labeling in Self-Training
Feb 18, 2022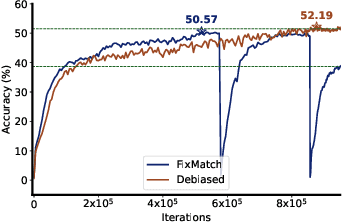
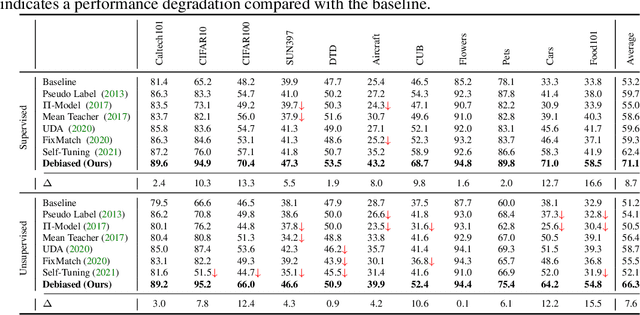
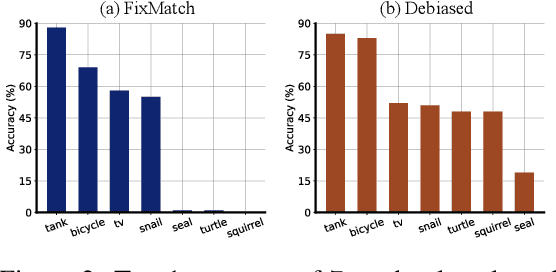
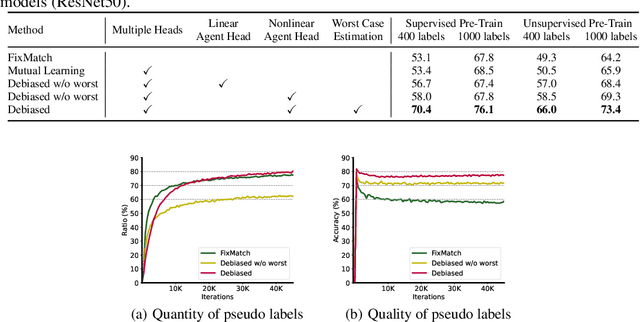
Deep neural networks achieve remarkable performances on a wide range of tasks with the aid of large-scale labeled datasets. However, large-scale annotations are time-consuming and labor-exhaustive to obtain on realistic tasks. To mitigate the requirement for labeled data, self-training is widely used in both academia and industry by pseudo labeling on readily-available unlabeled data. Despite its popularity, pseudo labeling is well-believed to be unreliable and often leads to training instability. Our experimental studies further reveal that the performance of self-training is biased due to data sampling, pre-trained models, and training strategies, especially the inappropriate utilization of pseudo labels. To this end, we propose Debiased, in which the generation and utilization of pseudo labels are decoupled by two independent heads. To further improve the quality of pseudo labels, we introduce a worst-case estimation of pseudo labeling and seamlessly optimize the representations to avoid the worst-case. Extensive experiments justify that the proposed Debiased not only yields an average improvement of $14.4$\% against state-of-the-art algorithms on $11$ tasks (covering generic object recognition, fine-grained object recognition, texture classification, and scene classification) but also helps stabilize training and balance performance across classes.
Transferability in Deep Learning: A Survey
Jan 15, 2022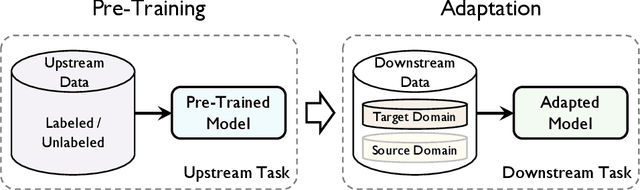

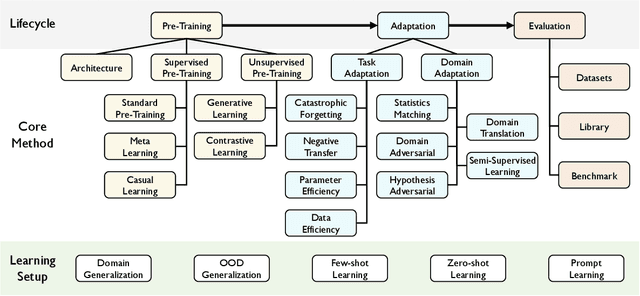

The success of deep learning algorithms generally depends on large-scale data, while humans appear to have inherent ability of knowledge transfer, by recognizing and applying relevant knowledge from previous learning experiences when encountering and solving unseen tasks. Such an ability to acquire and reuse knowledge is known as transferability in deep learning. It has formed the long-term quest towards making deep learning as data-efficient as human learning, and has been motivating fruitful design of more powerful deep learning algorithms. We present this survey to connect different isolated areas in deep learning with their relation to transferability, and to provide a unified and complete view to investigating transferability through the whole lifecycle of deep learning. The survey elaborates the fundamental goals and challenges in parallel with the core principles and methods, covering recent cornerstones in deep architectures, pre-training, task adaptation and domain adaptation. This highlights unanswered questions on the appropriate objectives for learning transferable knowledge and for adapting the knowledge to new tasks and domains, avoiding catastrophic forgetting and negative transfer. Finally, we implement a benchmark and an open-source library, enabling a fair evaluation of deep learning methods in terms of transferability.
Decoupled Adaptation for Cross-Domain Object Detection
Oct 06, 2021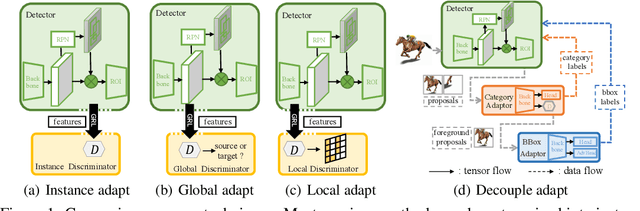
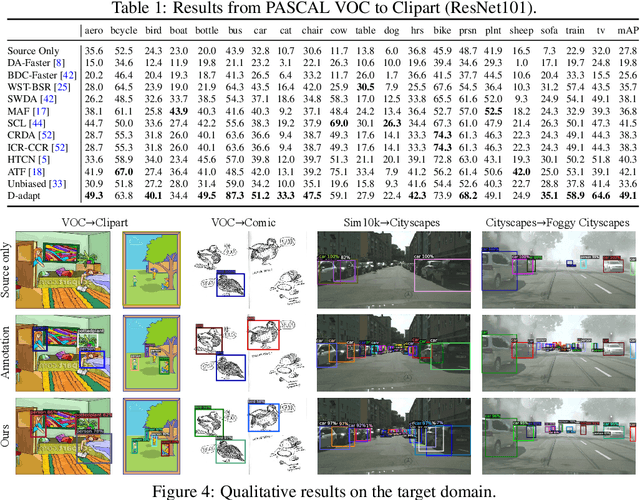
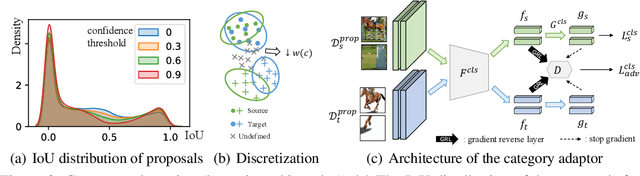
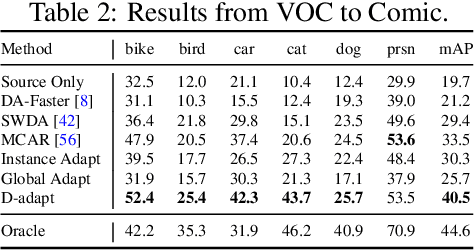
Cross-domain object detection is more challenging than object classification since multiple objects exist in an image and the location of each object is unknown in the unlabeled target domain. As a result, when we adapt features of different objects to enhance the transferability of the detector, the features of the foreground and the background are easy to be confused, which may hurt the discriminability of the detector. Besides, previous methods focused on category adaptation but ignored another important part for object detection, i.e., the adaptation on bounding box regression. To this end, we propose D-adapt, namely Decoupled Adaptation, to decouple the adversarial adaptation and the training of the detector. Besides, we fill the blank of regression domain adaptation in object detection by introducing a bounding box adaptor. Experiments show that D-adapt achieves state-of-the-art results on four cross-domain object detection tasks and yields 17% and 21% relative improvement on benchmark datasets Clipart1k and Comic2k in particular.
Regressive Domain Adaptation for Unsupervised Keypoint Detection
Mar 10, 2021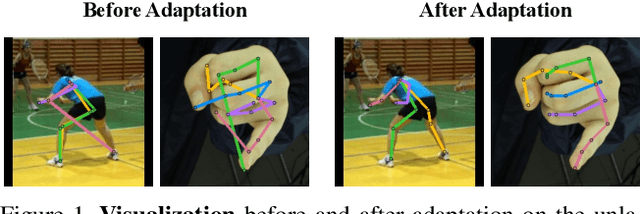
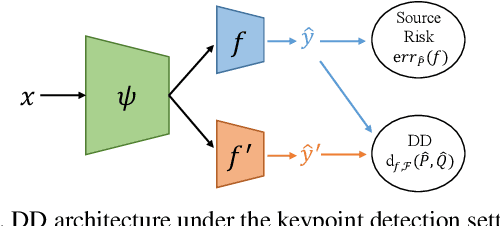
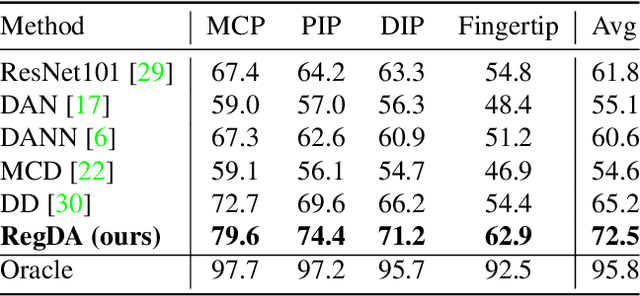
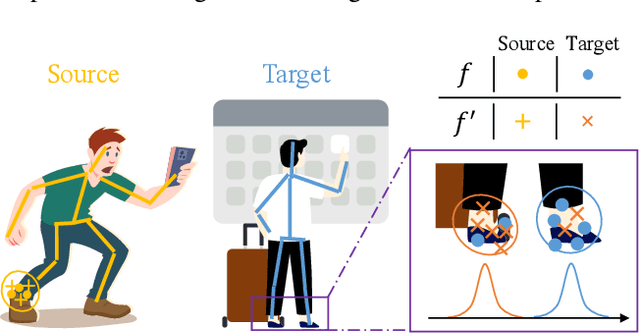
Domain adaptation (DA) aims at transferring knowledge from a labeled source domain to an unlabeled target domain. Though many DA theories and algorithms have been proposed, most of them are tailored into classification settings and may fail in regression tasks, especially in the practical keypoint detection task. To tackle this difficult but significant task, we present a method of regressive domain adaptation (RegDA) for unsupervised keypoint detection. Inspired by the latest theoretical work, we first utilize an adversarial regressor to maximize the disparity on the target domain and train a feature generator to minimize this disparity. However, due to the high dimension of the output space, this regressor fails to detect samples that deviate from the support of the source. To overcome this problem, we propose two important ideas. First, based on our observation that the probability density of the output space is sparse, we introduce a spatial probability distribution to describe this sparsity and then use it to guide the learning of the adversarial regressor. Second, to alleviate the optimization difficulty in the high-dimensional space, we innovatively convert the minimax game in the adversarial training to the minimization of two opposite goals. Extensive experiments show that our method brings large improvement by 8% to 11% in terms of PCK on different datasets.