 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink before Recommendation: Autonomous Reasoning-enhanced Recommender
Oct 27, 2025The core task of recommender systems is to learn user preferences from historical user-item interactions. With the rapid development of large language models (LLMs), recent research has explored leveraging the reasoning capabilities of LLMs to enhance rating prediction tasks. However, existing distillation-based methods suffer from limitations such as the teacher model's insufficient recommendation capability, costly and static supervision, and superficial transfer of reasoning ability. To address these issues, this paper proposes RecZero, a reinforcement learning (RL)-based recommendation paradigm that abandons the traditional multi-model and multi-stage distillation approach. Instead, RecZero trains a single LLM through pure RL to autonomously develop reasoning capabilities for rating prediction. RecZero consists of two key components: (1) "Think-before-Recommendation" prompt construction, which employs a structured reasoning template to guide the model in step-wise analysis of user interests, item features, and user-item compatibility; and (2) rule-based reward modeling, which adopts group relative policy optimization (GRPO) to compute rewards for reasoning trajectories and optimize the LLM. Additionally, the paper explores a hybrid paradigm, RecOne, which combines supervised fine-tuning with RL, initializing the model with cold-start reasoning samples and further optimizing it with RL. Experimental results demonstrate that RecZero and RecOne significantly outperform existing baseline methods on multiple benchmark datasets, validating the superiority of the RL paradigm in achieving autonomous reasoning-enhanced recommender systems.
Bidding-Aware Retrieval for Multi-Stage Consistency in Online Advertising
Aug 07, 2025Online advertising systems typically use a cascaded architecture to manage massive requests and candidate volumes, where the ranking stages allocate traffic based on eCPM (predicted CTR $\times$ Bid). With the increasing popularity of auto-bidding strategies, the inconsistency between the computationally sensitive retrieval stage and the ranking stages becomes more pronounced, as the former cannot access precise, real-time bids for the vast ad corpus. This discrepancy leads to sub-optimal platform revenue and advertiser outcomes. To tackle this problem, we propose Bidding-Aware Retrieval (BAR), a model-based retrieval framework that addresses multi-stage inconsistency by incorporating ad bid value into the retrieval scoring function. The core innovation is Bidding-Aware Modeling, incorporating bid signals through monotonicity-constrained learning and multi-task distillation to ensure economically coherent representations, while Asynchronous Near-Line Inference enables real-time updates to the embedding for market responsiveness. Furthermore, the Task-Attentive Refinement module selectively enhances feature interactions to disentangle user interest and commercial value signals. Extensive offline experiments and full-scale deployment across Alibaba's display advertising platform validated BAR's efficacy: 4.32% platform revenue increase with 22.2% impression lift for positively-operated advertisements.
Large Language Models Are Universal Recommendation Learners
Feb 05, 2025



In real-world recommender systems, different tasks are typically addressed using supervised learning on task-specific datasets with carefully designed model architectures. We demonstrate that large language models (LLMs) can function as universal recommendation learners, capable of handling multiple tasks within a unified input-output framework, eliminating the need for specialized model designs. To improve the recommendation performance of LLMs, we introduce a multimodal fusion module for item representation and a sequence-in-set-out approach for efficient candidate generation. When applied to industrial-scale data, our LLM achieves competitive results with expert models elaborately designed for different recommendation tasks. Furthermore, our analysis reveals that recommendation outcomes are highly sensitive to text input, highlighting the potential of prompt engineering in optimizing industrial-scale recommender systems.
Robust Representation Learning for Unified Online Top-K Recommendation
Oct 24, 2023



In large-scale industrial e-commerce, the efficiency of an online recommendation system is crucial in delivering highly relevant item/content advertising that caters to diverse business scenarios. However, most existing studies focus solely on item advertising, neglecting the significance of content advertising. This oversight results in inconsistencies within the multi-entity structure and unfair retrieval. Furthermore, the challenge of retrieving top-k advertisements from multi-entity advertisements across different domains adds to the complexity. Recent research proves that user-entity behaviors within different domains exhibit characteristics of differentiation and homogeneity. Therefore, the multi-domain matching models typically rely on the hybrid-experts framework with domain-invariant and domain-specific representations. Unfortunately, most approaches primarily focus on optimizing the combination mode of different experts, failing to address the inherent difficulty in optimizing the expert modules themselves. The existence of redundant information across different domains introduces interference and competition among experts, while the distinct learning objectives of each domain lead to varying optimization challenges among experts. To tackle these issues, we propose robust representation learning for the unified online top-k recommendation. Our approach constructs unified modeling in entity space to ensure data fairness. The robust representation learning employs domain adversarial learning and multi-view wasserstein distribution learning to learn robust representations. Moreover, the proposed method balances conflicting objectives through the homoscedastic uncertainty weights and orthogonality constraints. Various experiments validate the effectiveness and rationality of our proposed method, which has been successfully deployed online to serve real business scenarios.
Adaptive Domain Interest Network for Multi-domain Recommendation
Jun 20, 2022


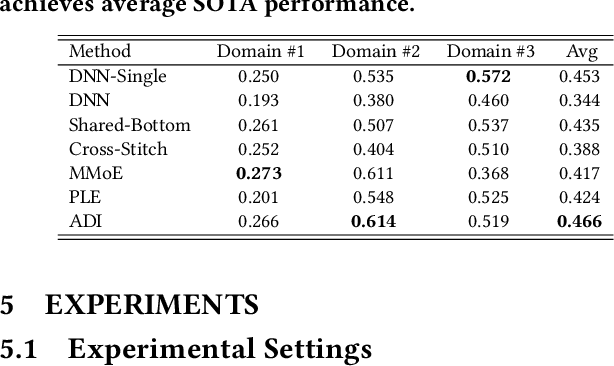
Industrial recommender systems usually hold data from multiple business scenarios and are expected to provide recommendation services for these scenarios simultaneously. In the retrieval step, the topK high-quality items selected from a large number of corpus usually need to be various for multiple scenarios. Take Alibaba display advertising system for example, not only because the behavior patterns of Taobao users are diverse, but also differentiated scenarios' bid prices assigned by advertisers vary significantly. Traditional methods either train models for each scenario separately, ignoring the cross-domain overlapping of user groups and items, or simply mix all samples and maintain a shared model which makes it difficult to capture significant diversities between scenarios. In this paper, we present Adaptive Domain Interest network that adaptively handles the commonalities and diversities across scenarios, making full use of multi-scenarios data during training. Then the proposed method is able to improve the performance of each business domain by giving various topK candidates for different scenarios during online inference. Specifically, our proposed ADI models the commonalities and diversities for different domains by shared networks and domain-specific networks, respectively. In addition, we apply the domain-specific batch normalization and design the domain interest adaptation layer for feature-level domain adaptation. A self training strategy is also incorporated to capture label-level connections across domains.ADI has been deployed in the display advertising system of Alibaba, and obtains 1.8% improvement on advertising revenue.
Context-aware Tree-based Deep Model for Recommender Systems
Sep 22, 2021



How to predict precise user preference and how to make efficient retrieval from a big corpus are two major challenges of large-scale industrial recommender systems. In tree-based methods, a tree structure T is adopted as index and each item in corpus is attached to a leaf node on T . Then the recommendation problem is converted into a hierarchical retrieval problem solved by a beam search process efficiently. In this paper, we argue that the tree index used to support efficient retrieval in tree-based methods also has rich hierarchical information about the corpus. Furthermore, we propose a novel context-aware tree-based deep model (ConTDM) for recommender systems. In ConTDM, a context-aware user preference prediction model M is designed to utilize both horizontal and vertical contexts on T . Horizontally, a graph convolutional layer is used to enrich the representation of both users and nodes on T with their neighbors. Vertically, a parent fusion layer is designed in M to transmit the user preference representation in higher levels of T to the current level, grasping the essence that tree-based methods are generating the candidate set from coarse to detail during the beam search retrieval. Besides, we argue that the proposed user preference model in ConTDM can be conveniently extended to other tree-based methods for recommender systems. Both experiments on large scale real-world datasets and online A/B test in large scale industrial applications show the significant improvements brought by ConTDM.
Learning Optimal Tree Models Under Beam Search
Jun 27, 2020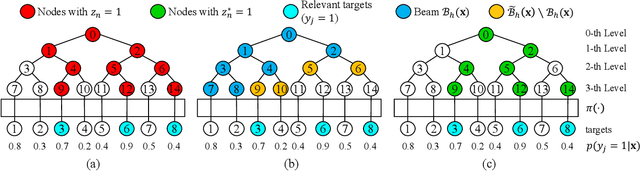
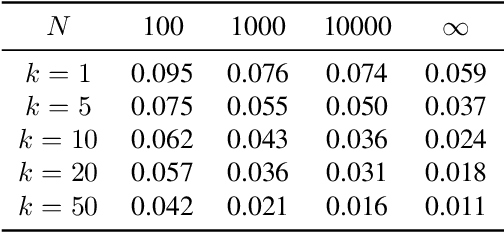
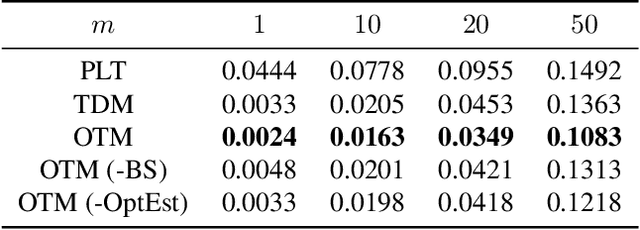
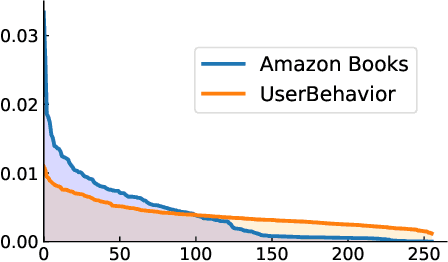
Retrieving relevant targets from an extremely large target set under computational limits is a common challenge for information retrieval and recommendation systems. Tree models, which formulate targets as leaves of a tree with trainable node-wise scorers, have attracted a lot of interests in tackling this challenge due to their logarithmic computational complexity in both training and testing. Tree-based deep models (TDMs) and probabilistic label trees (PLTs) are two representative kinds of them. Though achieving many practical successes, existing tree models suffer from the training-testing discrepancy, where the retrieval performance deterioration caused by beam search in testing is not considered in training. This leads to an intrinsic gap between the most relevant targets and those retrieved by beam search with even the optimally trained node-wise scorers. We take a first step towards understanding and analyzing this problem theoretically, and develop the concept of Bayes optimality under beam search and calibration under beam search as general analyzing tools for this purpose. Moreover, to eliminate the discrepancy, we propose a novel algorithm for learning optimal tree models under beam search. Experiments on both synthetic and real data verify the rationality of our theoretical analysis and demonstrate the superiority of our algorithm compared to state-of-the-art methods.
Joint Optimization of Tree-based Index and Deep Model for Recommender Systems
Feb 19, 2019



Large-scale industrial recommender systems are usually confronted with computational problems due to the enormous corpus size. To retrieve and recommend the most relevant items to users under response time limits, resorting to an efficient index structure is an effective and practical solution. Tree-based Deep Model (TDM) for recommendation \cite{zhu2018learning} greatly improves recommendation accuracy using tree index. By indexing items in a tree hierarchy and training a user-node preference prediction model satisfying a max-heap like property in the tree, TDM provides logarithmic computational complexity w.r.t. the corpus size, enabling the use of arbitrary advanced models in candidate retrieval and recommendation. In tree-based recommendation methods, the quality of both the tree index and the trained user preference prediction model determines the recommendation accuracy for the most part. We argue that the learning of tree index and user preference model has interdependence. Our purpose, in this paper, is to develop a method to jointly learn the index structure and user preference prediction model. In our proposed joint optimization framework, the learning of index and user preference prediction model are carried out under a unified performance measure. Besides, we come up with a novel hierarchical user preference representation utilizing the tree index hierarchy. Experimental evaluations with two large-scale real-world datasets show that the proposed method improves recommendation accuracy significantly. Online A/B test results at Taobao display advertising also demonstrate the effectiveness of the proposed method in production environments.