 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWSLRec: Weakly Supervised Learning for Neural Sequential Recommendation Models
Feb 28, 2022
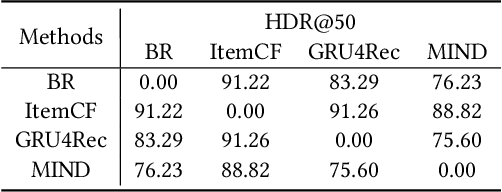
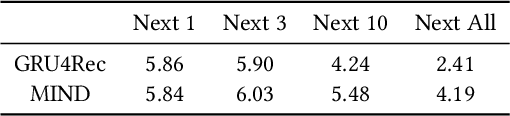
Learning the user-item relevance hidden in implicit feedback data plays an important role in modern recommender systems. Neural sequential recommendation models, which formulates learning the user-item relevance as a sequential classification problem to distinguish items in future behaviors from others based on the user's historical behaviors, have attracted a lot of interest in both industry and academic due to their substantial practical value. Though achieving many practical successes, we argue that the intrinsic {\bf incompleteness} and {\bf inaccuracy} of user behaviors in implicit feedback data is ignored and conduct preliminary experiments for supporting our claims. Motivated by the observation that model-free methods like behavioral retargeting (BR) and item-based collaborative filtering (ItemCF) hit different parts of the user-item relevance compared to neural sequential recommendation models, we propose a novel model-agnostic training approach called WSLRec, which adopts a three-stage framework: pre-training, top-$k$ mining, and fine-tuning. WSLRec resolves the incompleteness problem by pre-training models on extra weak supervisions from model-free methods like BR and ItemCF, while resolves the inaccuracy problem by leveraging the top-$k$ mining to screen out reliable user-item relevance from weak supervisions for fine-tuning. Experiments on two benchmark datasets and online A/B tests verify the rationality of our claims and demonstrate the effectiveness of WSLRec.
Context-aware Tree-based Deep Model for Recommender Systems
Sep 22, 2021



How to predict precise user preference and how to make efficient retrieval from a big corpus are two major challenges of large-scale industrial recommender systems. In tree-based methods, a tree structure T is adopted as index and each item in corpus is attached to a leaf node on T . Then the recommendation problem is converted into a hierarchical retrieval problem solved by a beam search process efficiently. In this paper, we argue that the tree index used to support efficient retrieval in tree-based methods also has rich hierarchical information about the corpus. Furthermore, we propose a novel context-aware tree-based deep model (ConTDM) for recommender systems. In ConTDM, a context-aware user preference prediction model M is designed to utilize both horizontal and vertical contexts on T . Horizontally, a graph convolutional layer is used to enrich the representation of both users and nodes on T with their neighbors. Vertically, a parent fusion layer is designed in M to transmit the user preference representation in higher levels of T to the current level, grasping the essence that tree-based methods are generating the candidate set from coarse to detail during the beam search retrieval. Besides, we argue that the proposed user preference model in ConTDM can be conveniently extended to other tree-based methods for recommender systems. Both experiments on large scale real-world datasets and online A/B test in large scale industrial applications show the significant improvements brought by ConTDM.
A Cooperative-Competitive Multi-Agent Framework for Auto-bidding in Online Advertising
Jun 11, 2021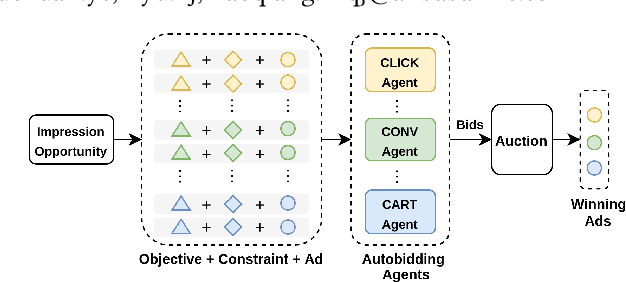
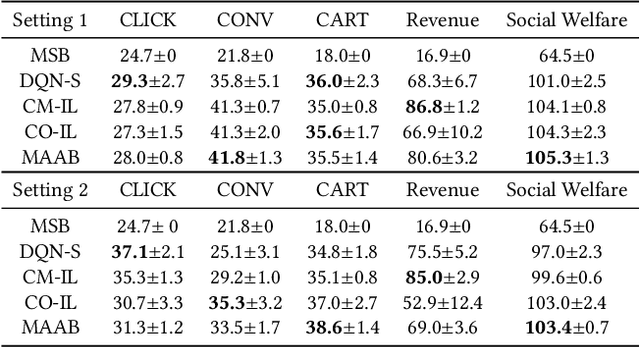
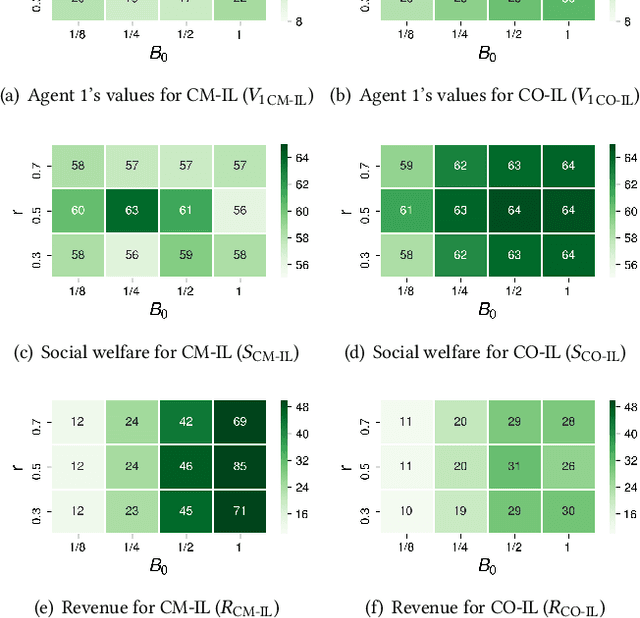

In online advertising, auto-bidding has become an essential tool for advertisers to optimize their preferred ad performance metrics by simply expressing the high-level campaign objectives and constraints. Previous works consider the design of auto-bidding agents from the single-agent view without modeling the mutual influence between agents. In this paper, we instead consider this problem from the perspective of a distributed multi-agent system, and propose a general Multi-Agent reinforcement learning framework for Auto-Bidding, namely MAAB, to learn the auto-bidding strategies. First, we investigate the competition and cooperation relation among auto-bidding agents, and propose temperature-regularized credit assignment for establishing a mixed cooperative-competitive paradigm. By carefully making a competition and cooperation trade-off among the agents, we can reach an equilibrium state that guarantees not only individual advertiser's utility but also the system performance (social welfare). Second, due to the observed collusion behaviors of bidding low prices underlying the cooperation, we further propose bar agents to set a personalized bidding bar for each agent, and then to alleviate the degradation of revenue. Third, to deploy MAAB to the large-scale advertising system with millions of advertisers, we propose a mean-field approach. By grouping advertisers with the same objective as a mean auto-bidding agent, the interactions among advertisers are greatly simplified, making it practical to train MAAB efficiently. Extensive experiments on the offline industrial dataset and Alibaba advertising platform demonstrate that our approach outperforms several baseline methods in terms of social welfare and guarantees the ad platform's revenue.
We Know What You Want: An Advertising Strategy Recommender System for Online Advertising
Jun 08, 2021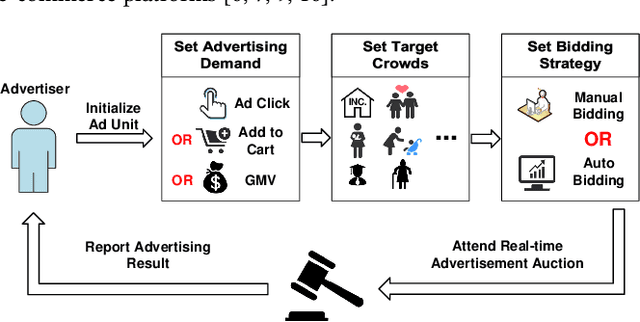
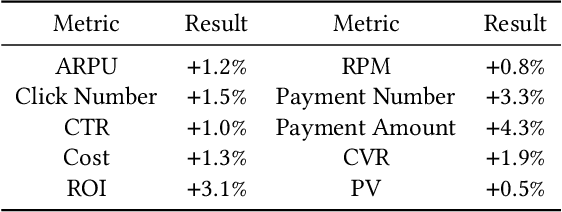
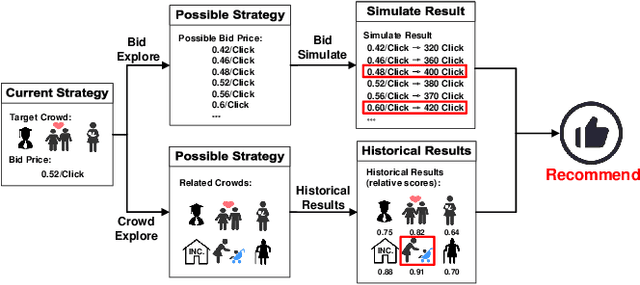
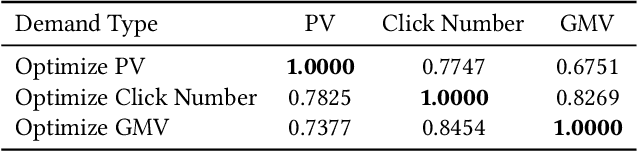
Advertising expenditures have become the major source of revenue for e-commerce platforms. Providing good advertising experiences for advertisers through reducing their costs of trial and error for discovering the optimal advertising strategies is crucial for the long-term prosperity of online advertising. To achieve this goal, the advertising platform needs to identify the advertisers' marketing objectives, and then recommend the corresponding strategies to fulfill this objective. In this work, we first deploy a prototype of strategy recommender system on Taobao display advertising platform, recommending bid prices and targeted users to advertisers. We further augment this prototype system by directly revealing the advertising performance, and then infer the advertisers' marketing objectives through their adoptions of different recommending advertising performance. We use the techniques from context bandit to jointly learn the advertisers' marketing objectives and the recommending strategies. Online evaluations show that the designed advertising strategy recommender system can optimize the advertisers' advertising performance and increase the platform's revenue. Simulation experiments based on Taobao online bidding data show that the designed contextual bandit algorithm can effectively optimize the strategy adoption rate of advertisers.
* Accepted by KDD 2021
Neural Auction: End-to-End Learning of Auction Mechanisms for E-Commerce Advertising
Jun 07, 2021In e-commerce advertising, it is crucial to jointly consider various performance metrics, e.g., user experience, advertiser utility, and platform revenue. Traditional auction mechanisms, such as GSP and VCG auctions, can be suboptimal due to their fixed allocation rules to optimize a single performance metric (e.g., revenue or social welfare). Recently, data-driven auctions, learned directly from auction outcomes to optimize multiple performance metrics, have attracted increasing research interests. However, the procedure of auction mechanisms involves various discrete calculation operations, making it challenging to be compatible with continuous optimization pipelines in machine learning. In this paper, we design \underline{D}eep \underline{N}eural \underline{A}uctions (DNAs) to enable end-to-end auction learning by proposing a differentiable model to relax the discrete sorting operation, a key component in auctions. We optimize the performance metrics by developing deep models to efficiently extract contexts from auctions, providing rich features for auction design. We further integrate the game theoretical conditions within the model design, to guarantee the stability of the auctions. DNAs have been successfully deployed in the e-commerce advertising system at Taobao. Experimental evaluation results on both large-scale data set as well as online A/B test demonstrated that DNAs significantly outperformed other mechanisms widely adopted in industry.
Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
Apr 29, 2021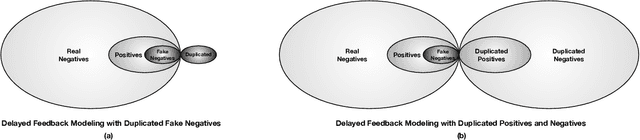

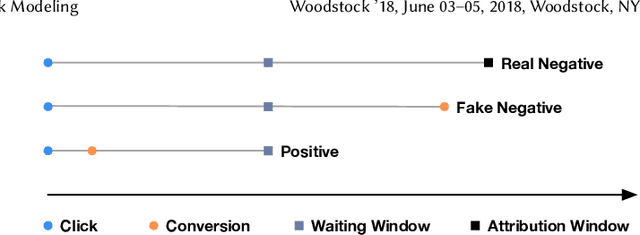
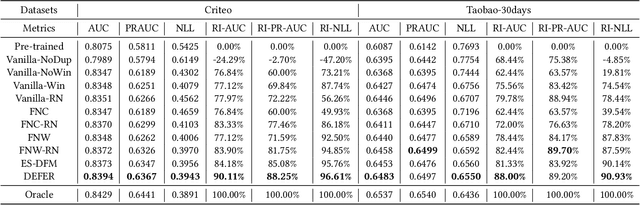
One of the difficulties of conversion rate (CVR) prediction is that the conversions can delay and take place long after the clicks. The delayed feedback poses a challenge: fresh data are beneficial to continuous training but may not have complete label information at the time they are ingested into the training pipeline. To balance model freshness and label certainty, previous methods set a short waiting window or even do not wait for the conversion signal. If conversion happens outside the waiting window, this sample will be duplicated and ingested into the training pipeline with a positive label. However, these methods have some issues. First, they assume the observed feature distribution remains the same as the actual distribution. But this assumption does not hold due to the ingestion of duplicated samples. Second, the certainty of the conversion action only comes from the positives. But the positives are scarce as conversions are sparse in commercial systems. These issues induce bias during the modeling of delayed feedback. In this paper, we propose DElayed FEedback modeling with Real negatives (DEFER) method to address these issues. The proposed method ingests real negative samples into the training pipeline. The ingestion of real negatives ensures the observed feature distribution is equivalent to the actual distribution, thus reducing the bias. The ingestion of real negatives also brings more certainty information of the conversion. To correct the distribution shift, DEFER employs importance sampling to weigh the loss function. Experimental results on industrial datasets validate the superiority of DEFER. DEFER have been deployed in the display advertising system of Alibaba, obtaining over 6.0% improvement on CVR in several scenarios. The code and data in this paper are now open-sourced {https://github.com/gusuperstar/defer.git}.
Computation Resource Allocation Solution in Recommender Systems
Mar 03, 2021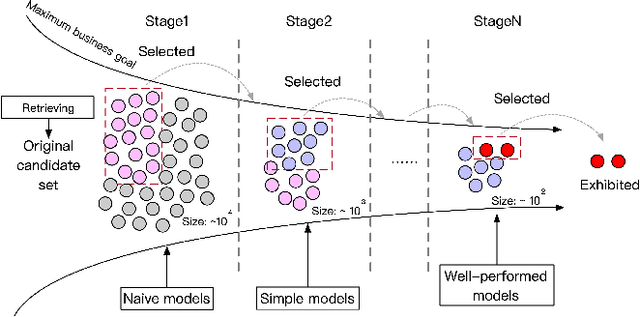

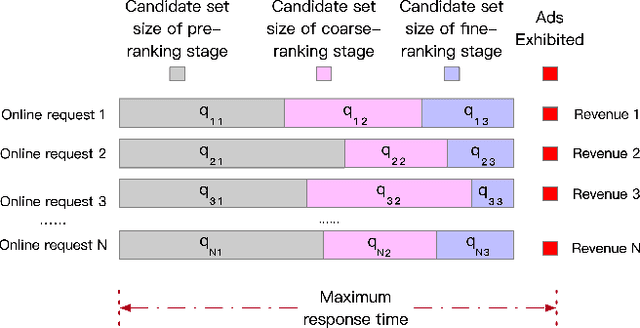
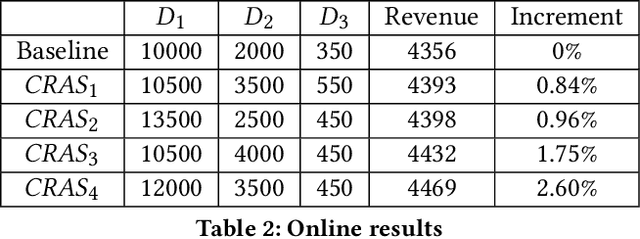
Recommender systems rely heavily on increasing computation resources to improve their business goal. By deploying computation-intensive models and algorithms, these systems are able to inference user interests and exhibit certain ads or commodities from the candidate set to maximize their business goals. However, such systems are facing two challenges in achieving their goals. On the one hand, facing massive online requests, computation-intensive models and algorithms are pushing their computation resources to the limit. On the other hand, the response time of these systems is strictly limited to a short period, e.g. 300 milliseconds in our real system, which is also being exhausted by the increasingly complex models and algorithms. In this paper, we propose the computation resource allocation solution (CRAS) that maximizes the business goal with limited computation resources and response time. We comprehensively illustrate the problem and formulate such a problem as an optimization problem with multiple constraints, which could be broken down into independent sub-problems. To solve the sub-problems, we propose the revenue function to facilitate the theoretical analysis, and obtain the optimal computation resource allocation strategy. To address the applicability issues, we devise the feedback control system to help our strategy constantly adapt to the changing online environment. The effectiveness of our method is verified by extensive experiments based on the real dataset from Taobao.com. We also deploy our method in the display advertising system of Alibaba. The online results show that our computation resource allocation solution achieves significant business goal improvement without any increment of computation cost, which demonstrates the efficacy of our method in real industrial practice.
Truncation-Free Matching System for Display Advertising at Alibaba
Feb 18, 2021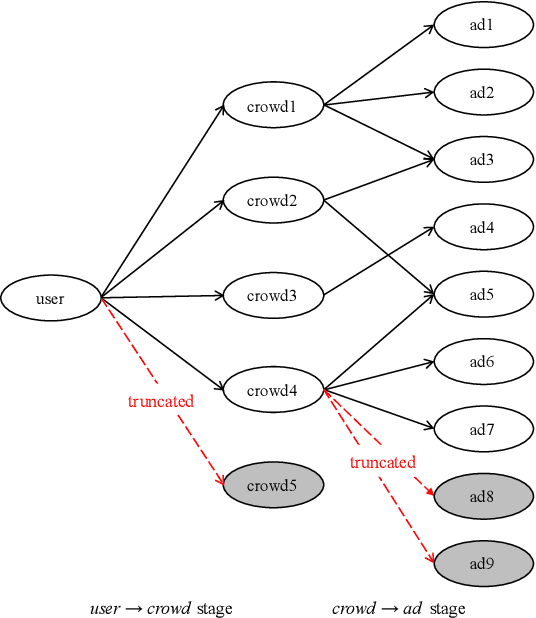


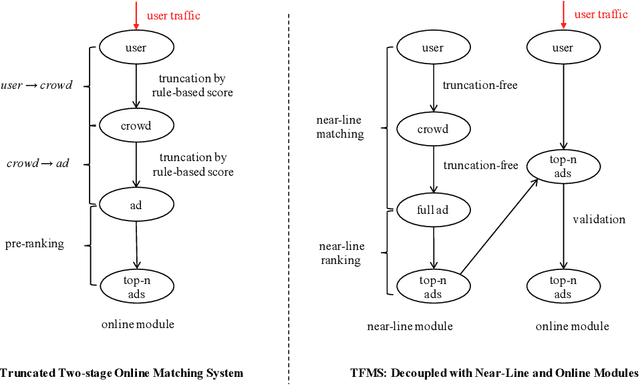
Matching module plays a critical role in display advertising systems. Without query from user, it is challenging for system to match user traffic and ads suitably. System packs up a group of users with common properties such as the same gender or similar shopping interests into a crowd. Here term crowd can be viewed as a tag over users. Then advertisers bid for different crowds and deliver their ads to those targeted users. Matching module in most industrial display advertising systems follows a two-stage paradigm. When receiving a user request, matching system (i) finds the crowds that the user belongs to; (ii) retrieves all ads that have targeted those crowds. However, in applications such as display advertising at Alibaba, with very large volumes of crowds and ads, both stages of matching have to truncate the long-tailed parts for online serving, under limited latency. That's to say, not all ads have the chance to participate in online matching. This results in sub-optimal result for both advertising performance and platform revenue. In this paper, we study the truncation problem and propose a Truncation Free Matching System (TFMS). The basic idea is to decouple the matching computation from the online pipeline. Instead of executing the two-stage matching when user visits, TFMS utilizes a near-line truncation-free matching to pre-calculate and store those top valuable ads for each user. Then the online pipeline just needs to fetch the pre-stored ads as matching results. In this way, we can jump out of online system's latency and computation cost limitations, and leverage flexible computation resource to finish the user-ad matching. TFMS has been deployed in our productive system since 2019, bringing (i) more than 50% improvement of impressions for advertisers who encountered truncation before, (ii) 9.4% Revenue Per Mile gain, which is significant enough for the business.
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
Jan 27, 2021
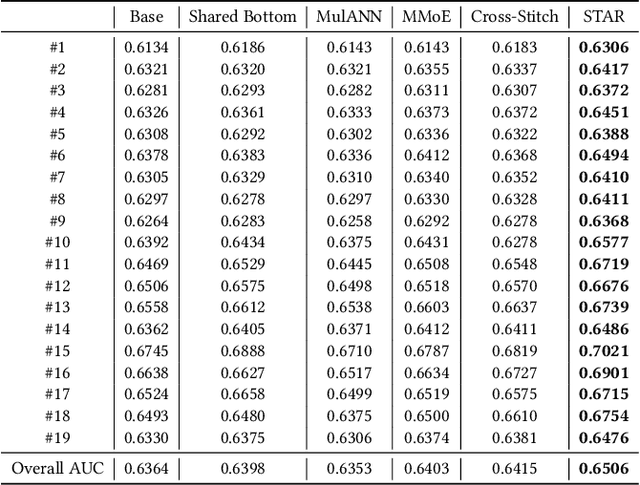
Traditional industrial recommenders are usually trained on a single business domain and then serve for this domain. In large commercial platforms, however, it is often the case that the recommenders need to make click-through rate (CTR) predictions for multiple business domains. Different domains have overlapping user groups and items, thus exist commonalities. Since the specific user group may be different and the user behaviors may change within a specific domain, different domains also have distinctions. The distinctions result in different domain-specific data distributions, which makes it hard for a single shared model to work well on all domains. To address the problem, we present Star Topology Adaptive Recommender (STAR), where one model is learned to serve all domains effectively. Concretely, STAR has the star topology, which consists of the shared centered parameters and domain-specific parameters. The shared parameters are used to learn commonalities of all domains and the domain-specific parameters capture domain distinction for more refined prediction. Given requests from different domains, STAR can adapt its parameters conditioned on the domain. The experimental result from production data validates the superiority of the proposed STAR model. Up to now, STAR has been deployed in the display advertising system of Alibaba, obtaining averaging 8.0% improvement on CTR and 6.0% on RPM (Revenue Per Mille).
Exploration in Online Advertising Systems with Deep Uncertainty-Aware Learning
Nov 25, 2020
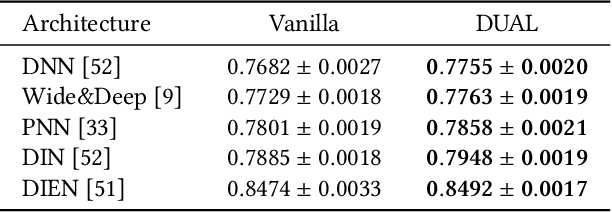
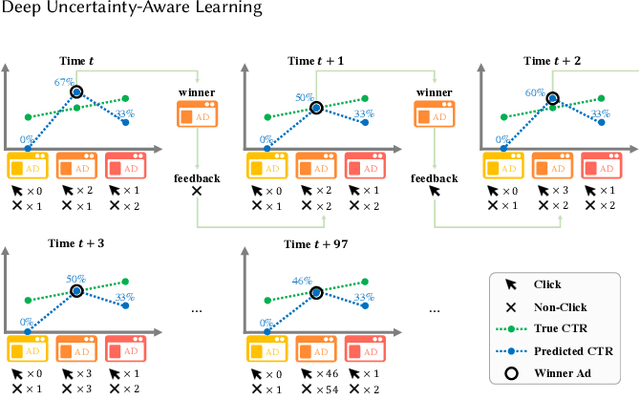
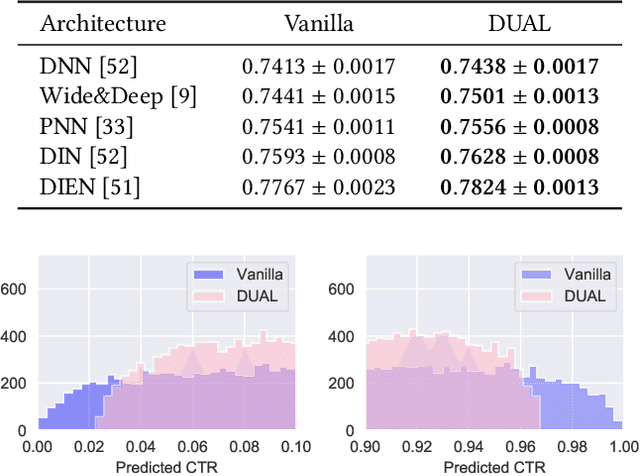
Modern online advertising systems inevitably rely on personalization methods, such as click-through rate (CTR) prediction. Recent progress in CTR prediction enjoys the rich representation capabilities of deep learning and achieves great success in large-scale industrial applications. However, these methods can suffer from lack of exploration. Another line of prior work addresses the exploration-exploitation trade-off problem with contextual bandit methods, which are less studied in the industry recently due to the difficulty in extending their flexibility with deep models. In this paper, we propose a novel Deep Uncertainty-Aware Learning (DUAL) method to learn deep CTR models based on Gaussian processes, which can provide efficient uncertainty estimations along with the CTR predictions while maintaining the flexibility of deep neural networks. By linking the ability to estimate predictive uncertainties of DUAL to well-known bandit algorithms, we further present DUAL-based Ad-ranking strategies to boost up long-term utilities such as the social welfare in advertising systems. Experimental results on several public datasets demonstrate the effectiveness of our methods. Remarkably, an online A/B test deployed in the Alibaba display advertising platform shows an $8.2\%$ social welfare improvement and an $8.0\%$ revenue lift.