 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Task Order for Continual Learning of Multiple Tasks
Feb 05, 2025Continual learning of multiple tasks remains a major challenge for neural networks. Here, we investigate how task order influences continual learning and propose a strategy for optimizing it. Leveraging a linear teacher-student model with latent factors, we derive an analytical expression relating task similarity and ordering to learning performance. Our analysis reveals two principles that hold under a wide parameter range: (1) tasks should be arranged from the least representative to the most typical, and (2) adjacent tasks should be dissimilar. We validate these rules on both synthetic data and real-world image classification datasets (Fashion-MNIST, CIFAR-10, CIFAR-100), demonstrating consistent performance improvements in both multilayer perceptrons and convolutional neural networks. Our work thus presents a generalizable framework for task-order optimization in task-incremental continual learning.
Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation
Jun 11, 2024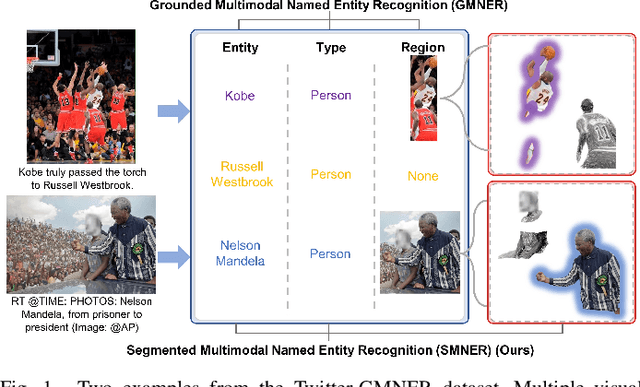
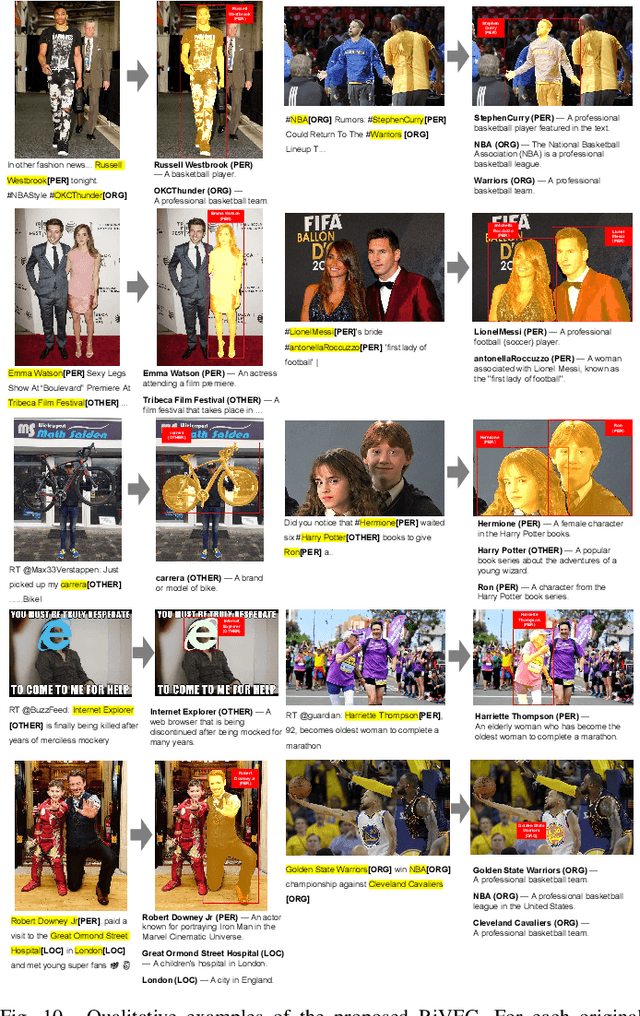
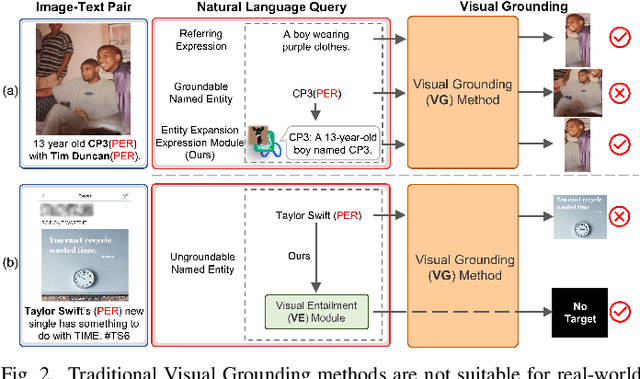
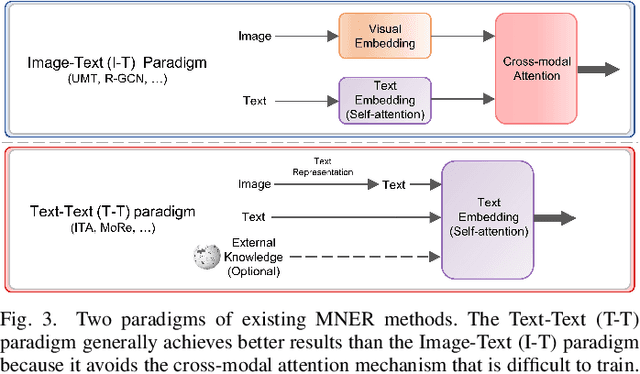
Grounded Multimodal Named Entity Recognition (GMNER) task aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging attributes: 1) The tenuous correlation between images and text on social media contributes to a notable proportion of named entities being ungroundable. 2) There exists a distinction between coarse-grained noun phrases used in similar tasks (e.g., phrase localization) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as connecting bridges. This reformulation brings two benefits: 1) It enables us to optimize the MNER module for optimal MNER performance and eliminates the need to pre-extract region features using object detection methods, thus naturally addressing the two major limitations of existing GMNER methods. 2) The introduction of Entity Expansion Expression module and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). This endows the proposed framework with unlimited data and model scalability. Furthermore, to address the potential ambiguity stemming from the coarse-grained bounding box output in GMNER, we further construct the new Segmented Multimodal Named Entity Recognition (SMNER) task and corresponding Twitter-SMNER dataset aimed at generating fine-grained segmentation masks, and experimentally demonstrate the feasibility and effectiveness of using box prompt-based Segment Anything Model (SAM) to empower any GMNER model with the ability to accomplish the SMNER task. Extensive experiments demonstrate that RiVEG significantly outperforms SoTA methods on four datasets across the MNER, GMNER, and SMNER tasks.
Exploration in Online Advertising Systems with Deep Uncertainty-Aware Learning
Nov 25, 2020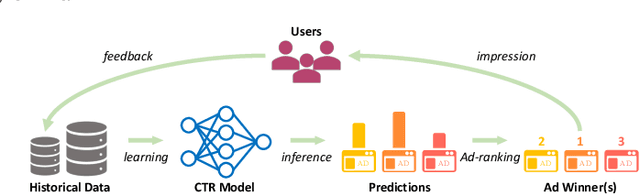
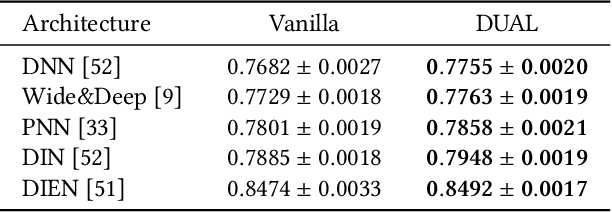
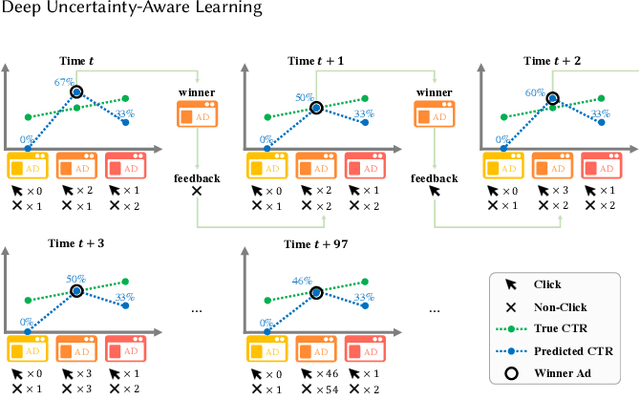
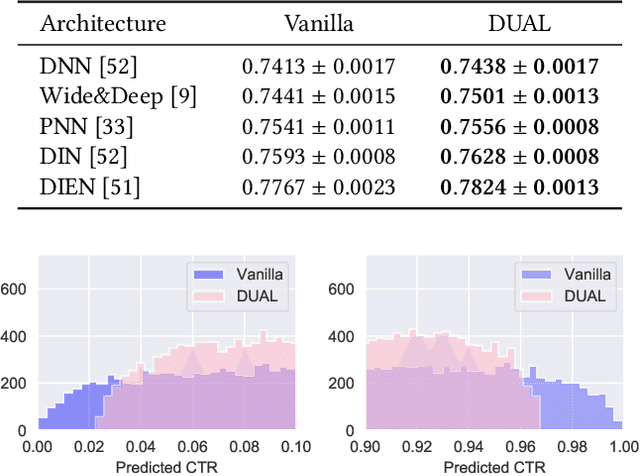
Modern online advertising systems inevitably rely on personalization methods, such as click-through rate (CTR) prediction. Recent progress in CTR prediction enjoys the rich representation capabilities of deep learning and achieves great success in large-scale industrial applications. However, these methods can suffer from lack of exploration. Another line of prior work addresses the exploration-exploitation trade-off problem with contextual bandit methods, which are less studied in the industry recently due to the difficulty in extending their flexibility with deep models. In this paper, we propose a novel Deep Uncertainty-Aware Learning (DUAL) method to learn deep CTR models based on Gaussian processes, which can provide efficient uncertainty estimations along with the CTR predictions while maintaining the flexibility of deep neural networks. By linking the ability to estimate predictive uncertainties of DUAL to well-known bandit algorithms, we further present DUAL-based Ad-ranking strategies to boost up long-term utilities such as the social welfare in advertising systems. Experimental results on several public datasets demonstrate the effectiveness of our methods. Remarkably, an online A/B test deployed in the Alibaba display advertising platform shows an $8.2\%$ social welfare improvement and an $8.0\%$ revenue lift.