 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Alignment: Value Diversity as a Collective Property in Multicultural Agent Systems
Jun 04, 2026Multicultural multi-agent systems are increasingly deployed in globally diverse settings, where different agents are grounded in different cultural backgrounds. Existing cultural evaluation focuses on value alignment: how closely a single agent matches a target culture. Yet alignment is a per-agent property and cannot reveal whether a system, taken as a whole, preserves the cultural plurality it is meant to represent. We propose value diversity as a system-level evaluation axis for multicultural agent systems, defined through the dissimilarity between culturally conditioned agents' responses on a shared value survey. Using the World Values Survey, we evaluate 19 cultures and 18 backbone models across a wide range of system configurations. We find that diversity is largely uncorrelated with alignment, indicating that the two capture complementary system properties, and that current multicultural agent systems fall substantially below human societies in value diversity. Mixed-backbone systems narrow this gap but do not close it, and the gap persists across culture compositions and agent scales. Social interaction further erodes diversity by driving agents toward consensus, and a participatory budgeting case study shows that this homogenization narrows the breadth of collective decision-making. Together, our results establish value diversity as a distinct evaluation axis for multicultural multi-agent systems and reveal a persistent homogenization tendency in current LLM-based societies. Our code and data are publicly available at https://github.com/iNLP-Lab/MultiAgent-Diversity.
G-Zero: Self-Play for Open-Ended Generation from Zero Data
May 11, 2026Self-evolving LLMs excel in verifiable domains but struggle in open-ended tasks, where reliance on proxy LLM judges introduces capability bottlenecks and reward hacking. To overcome this, we introduce G-Zero, a verifier-free, co-evolutionary framework for autonomous self-improvement. Our core innovation is Hint-$δ$, an intrinsic reward that quantifies the predictive shift between a Generator model's unassisted response and its response conditioned on a self-generated hint. Using this signal, a Proposer model is trained via GRPO to continuously target the Generator's blind spots by synthesizing challenging queries and informative hints. The Generator is concurrently optimized via DPO to internalize these hint-guided improvements. Theoretically, we prove a best-iterate suboptimality guarantee for an idealized standard-DPO version of G-Zero, provided that the Proposer induces sufficient exploration coverage and the data filteration keeps pseudo-label score noise low. By deriving supervision entirely from internal distributional dynamics, G-Zero bypasses the capability ceilings of external judges, providing a scalable, robust pathway for continuous LLM self-evolution across unverifiable domains.
Training Data Efficiency in Multimodal Process Reward Models
Feb 05, 2026Multimodal Process Reward Models (MPRMs) are central to step-level supervision for visual reasoning in MLLMs. Training MPRMs typically requires large-scale Monte Carlo (MC)-annotated corpora, incurring substantial training cost. This paper studies the data efficiency for MPRM training. Our preliminary experiments reveal that MPRM training quickly saturates under random subsampling of the training data, indicating substantial redundancy within existing MC-annotated corpora. To explain this, we formalize a theoretical framework and reveal that informative gradient updates depend on two factors: label mixtures of positive/negative steps and label reliability (average MC scores of positive steps). Guided by these insights, we propose the Balanced-Information Score (BIS), which prioritizes both mixture and reliability based on existing MC signals at the rollout level, without incurring any additional cost. Across two backbones (InternVL2.5-8B and Qwen2.5-VL-7B) on VisualProcessBench, BIS-selected subsets consistently match and even surpass the full-data performance at small fractions. Notably, the BIS subset reaches full-data performance using only 10% of the training data, improving over random subsampling by a relative 4.1%.
Darwinian Memory: A Training-Free Self-Regulating Memory System for GUI Agent Evolution
Jan 30, 2026Multimodal Large Language Model (MLLM) agents facilitate Graphical User Interface (GUI) automation but struggle with long-horizon, cross-application tasks due to limited context windows. While memory systems provide a viable solution, existing paradigms struggle to adapt to dynamic GUI environments, suffering from a granularity mismatch between high-level intent and low-level execution, and context pollution where the static accumulation of outdated experiences drives agents into hallucination. To address these bottlenecks, we propose the Darwinian Memory System (DMS), a self-evolving architecture that constructs memory as a dynamic ecosystem governed by the law of survival of the fittest. DMS decomposes complex trajectories into independent, reusable units for compositional flexibility, and implements Utility-driven Natural Selection to track survival value, actively pruning suboptimal paths and inhibiting high-risk plans. This evolutionary pressure compels the agent to derive superior strategies. Extensive experiments on real-world multi-app benchmarks validate that DMS boosts general-purpose MLLMs without training costs or architectural overhead, achieving average gains of 18.0% in success rate and 33.9% in execution stability, while reducing task latency, establishing it as an effective self-evolving memory system for GUI tasks.
RelayLLM: Efficient Reasoning via Collaborative Decoding
Jan 08, 2026Large Language Models (LLMs) for complex reasoning is often hindered by high computational costs and latency, while resource-efficient Small Language Models (SLMs) typically lack the necessary reasoning capacity. Existing collaborative approaches, such as cascading or routing, operate at a coarse granularity by offloading entire queries to LLMs, resulting in significant computational waste when the SLM is capable of handling the majority of reasoning steps. To address this, we propose RelayLLM, a novel framework for efficient reasoning via token-level collaborative decoding. Unlike routers, RelayLLM empowers the SLM to act as an active controller that dynamically invokes the LLM only for critical tokens via a special command, effectively "relaying" the generation process. We introduce a two-stage training framework, including warm-up and Group Relative Policy Optimization (GRPO) to teach the model to balance independence with strategic help-seeking. Empirical results across six benchmarks demonstrate that RelayLLM achieves an average accuracy of 49.52%, effectively bridging the performance gap between the two models. Notably, this is achieved by invoking the LLM for only 1.07% of the total generated tokens, offering a 98.2% cost reduction compared to performance-matched random routers.
AutoPBO: LLM-powered Optimization for Local Search PBO Solvers
Sep 04, 2025Pseudo-Boolean Optimization (PBO) provides a powerful framework for modeling combinatorial problems through pseudo-Boolean (PB) constraints. Local search solvers have shown excellent performance in PBO solving, and their efficiency is highly dependent on their internal heuristics to guide the search. Still, their design often requires significant expert effort and manual tuning in practice. While Large Language Models (LLMs) have demonstrated potential in automating algorithm design, their application to optimizing PBO solvers remains unexplored. In this work, we introduce AutoPBO, a novel LLM-powered framework to automatically enhance PBO local search solvers. We conduct experiments on a broad range of four public benchmarks, including one real-world benchmark, a benchmark from PB competition, an integer linear programming optimization benchmark, and a crafted combinatorial benchmark, to evaluate the performance improvement achieved by AutoPBO and compare it with six state-of-the-art competitors, including two local search PBO solvers NuPBO and OraSLS, two complete PB solvers PBO-IHS and RoundingSat, and two mixed integer programming (MIP) solvers Gurobi and SCIP. AutoPBO demonstrates significant improvements over previous local search approaches, while maintaining competitive performance compared to state-of-the-art competitors. The results suggest that AutoPBO offers a promising approach to automating local search solver design.
VP-MEL: Visual Prompts Guided Multimodal Entity Linking
Dec 10, 2024



Multimodal Entity Linking (MEL) is extensively utilized in the domains of information retrieval. However, existing MEL methods typically utilize mention words as mentions for retrieval. This results in a significant dependence of MEL on mention words, thereby constraining its capacity to effectively leverage information from both images and text. In situations where mention words are absent, MEL methods struggle to leverage image-text pairs for entity linking. To solve these issues, we introduce a Visual Prompts guided Multimodal Entity Linking (VP-MEL) task. VP-MEL directly marks specific regions within the image. These markers are referred to as visual prompts in VP-MEL. Without mention words, VP-MEL aims to utilize marked image-text pairs to align visual prompts with specific entities in the knowledge bases. A new dataset for the VP-MEL task, VPWiki, is proposed in this paper. Moreover, we propose a framework named FBMEL, which enhances the significance of visual prompts and fully leverages the information in image-text pairs. Experimental results on the VPWiki dataset demonstrate that FBMEL outperforms baseline methods across multiple benchmarks for the VP-MEL task.
Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation
Jun 11, 2024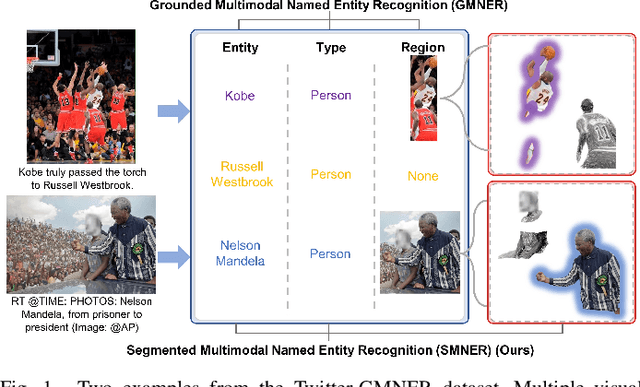
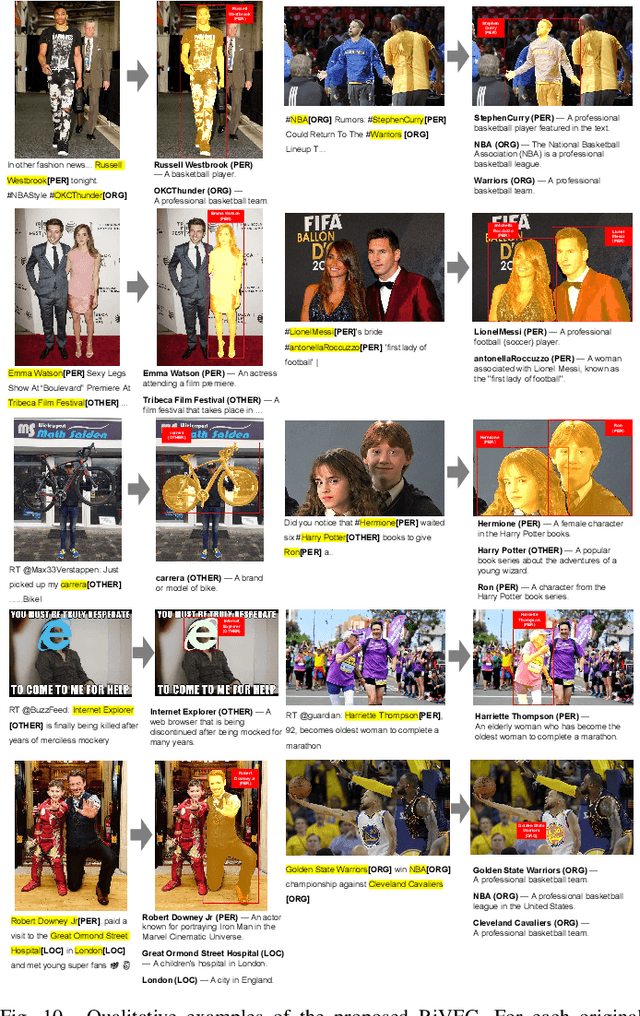
Grounded Multimodal Named Entity Recognition (GMNER) task aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging attributes: 1) The tenuous correlation between images and text on social media contributes to a notable proportion of named entities being ungroundable. 2) There exists a distinction between coarse-grained noun phrases used in similar tasks (e.g., phrase localization) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as connecting bridges. This reformulation brings two benefits: 1) It enables us to optimize the MNER module for optimal MNER performance and eliminates the need to pre-extract region features using object detection methods, thus naturally addressing the two major limitations of existing GMNER methods. 2) The introduction of Entity Expansion Expression module and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). This endows the proposed framework with unlimited data and model scalability. Furthermore, to address the potential ambiguity stemming from the coarse-grained bounding box output in GMNER, we further construct the new Segmented Multimodal Named Entity Recognition (SMNER) task and corresponding Twitter-SMNER dataset aimed at generating fine-grained segmentation masks, and experimentally demonstrate the feasibility and effectiveness of using box prompt-based Segment Anything Model (SAM) to empower any GMNER model with the ability to accomplish the SMNER task. Extensive experiments demonstrate that RiVEG significantly outperforms SoTA methods on four datasets across the MNER, GMNER, and SMNER tasks.
LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition
Feb 17, 2024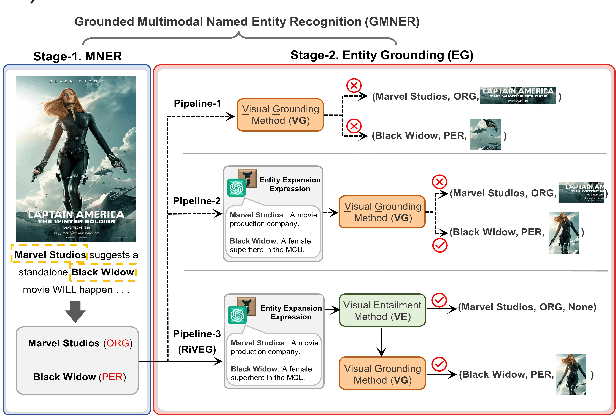
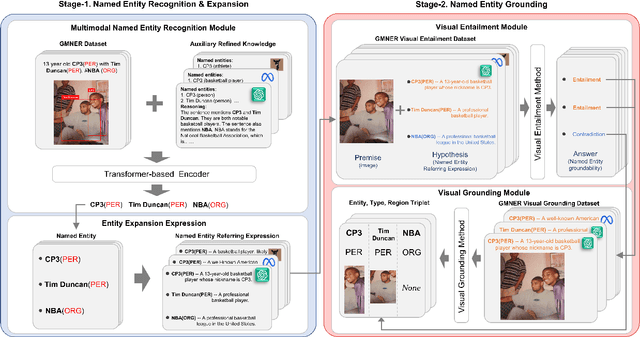

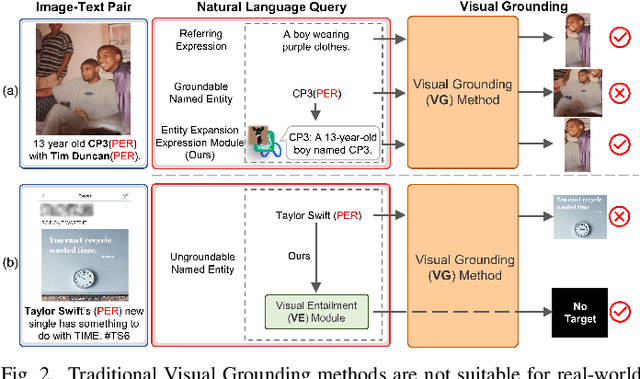
Grounded Multimodal Named Entity Recognition (GMNER) is a nascent multimodal task that aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging properties: 1) The weak correlation between image-text pairs in social media results in a significant portion of named entities being ungroundable. 2) There exists a distinction between coarse-grained referring expressions commonly used in similar tasks (e.g., phrase localization, referring expression comprehension) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as a connecting bridge. This reformulation brings two benefits: 1) It maintains the optimal MNER performance and eliminates the need for employing object detection methods to pre-extract regional features, thereby naturally addressing two major limitations of existing GMNER methods. 2) The introduction of entity expansion expression and Visual Entailment (VE) Module unifies Visual Grounding (VG) and Entity Grounding (EG). It enables RiVEG to effortlessly inherit the Visual Entailment and Visual Grounding capabilities of any current or prospective multimodal pretraining models. Extensive experiments demonstrate that RiVEG outperforms state-of-the-art methods on the existing GMNER dataset and achieves absolute leads of 10.65%, 6.21%, and 8.83% in all three subtasks.
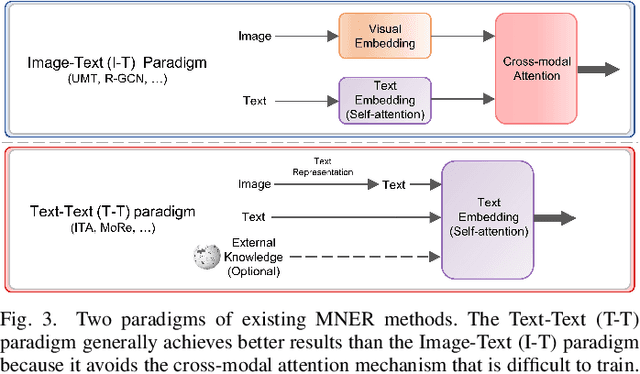
Prompt ChatGPT In MNER: Improved multimodal named entity recognition method based on auxiliary refining knowledge from ChatGPT
May 20, 2023



Multimodal Named Entity Recognition (MNER) on social media aims to enhance textual entity prediction by incorporating image-based clues. Existing research in this domain has primarily focused on maximizing the utilization of potentially relevant information in images or incorporating external knowledge from explicit knowledge bases (KBs). However, these methods either neglect the necessity of providing the model with relevant external knowledge, or the retrieved external knowledge suffers from high redundancy. To address these problems, we propose a conceptually simple two-stage framework called Prompt ChatGPT In MNER (PGIM) in this paper. We leverage ChatGPT as an implicit knowledge engine to acquire auxiliary refined knowledge, thereby bolstering the model's performance in MNER tasks. Specifically, we first utilize a Multimodal Similar Example Awareness module to select suitable examples from a small number of manually annotated samples. These examples are then integrated into a formatted prompt template tailored to the MNER task, guiding ChatGPT to generate auxiliary refined knowledge. Finally, the acquired knowledge is integrated with the raw text and inputted into the downstream model for further processing. Extensive experiments show that our PGIM significantly outperforms all existing state-of-the-art methods on two classic MNER datasets.