 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
OmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
Sep 18, 2025Recent research on representation learning has proved the merits of multi-modal clues for robust semantic segmentation. Nevertheless, a flexible pretrain-and-finetune pipeline for multiple visual modalities remains unexplored. In this paper, we propose a novel multi-modal learning framework, termed OmniSegmentor. It has two key innovations: 1) Based on ImageNet, we assemble a large-scale dataset for multi-modal pretraining, called ImageNeXt, which contains five popular visual modalities. 2) We provide an efficient pretraining manner to endow the model with the capacity to encode different modality information in the ImageNeXt. For the first time, we introduce a universal multi-modal pretraining framework that consistently amplifies the model's perceptual capabilities across various scenarios, regardless of the arbitrary combination of the involved modalities. Remarkably, our OmniSegmentor achieves new state-of-the-art records on a wide range of multi-modal semantic segmentation datasets, including NYU Depthv2, EventScape, MFNet, DeLiVER, SUNRGBD, and KITTI-360.
AR-1-to-3: Single Image to Consistent 3D Object Generation via Next-View Prediction
Mar 17, 2025Novel view synthesis (NVS) is a cornerstone for image-to-3d creation. However, existing works still struggle to maintain consistency between the generated views and the input views, especially when there is a significant camera pose difference, leading to poor-quality 3D geometries and textures. We attribute this issue to their treatment of all target views with equal priority according to our empirical observation that the target views closer to the input views exhibit higher fidelity. With this inspiration, we propose AR-1-to-3, a novel next-view prediction paradigm based on diffusion models that first generates views close to the input views, which are then utilized as contextual information to progressively synthesize farther views. To encode the generated view subsequences as local and global conditions for the next-view prediction, we accordingly develop a stacked local feature encoding strategy (Stacked-LE) and an LSTM-based global feature encoding strategy (LSTM-GE). Extensive experiments demonstrate that our method significantly improves the consistency between the generated views and the input views, producing high-fidelity 3D assets.
TAR3D: Creating High-Quality 3D Assets via Next-Part Prediction
Dec 22, 2024



We present TAR3D, a novel framework that consists of a 3D-aware Vector Quantized-Variational AutoEncoder (VQ-VAE) and a Generative Pre-trained Transformer (GPT) to generate high-quality 3D assets. The core insight of this work is to migrate the multimodal unification and promising learning capabilities of the next-token prediction paradigm to conditional 3D object generation. To achieve this, the 3D VQ-VAE first encodes a wide range of 3D shapes into a compact triplane latent space and utilizes a set of discrete representations from a trainable codebook to reconstruct fine-grained geometries under the supervision of query point occupancy. Then, the 3D GPT, equipped with a custom triplane position embedding called TriPE, predicts the codebook index sequence with prefilling prompt tokens in an autoregressive manner so that the composition of 3D geometries can be modeled part by part. Extensive experiments on ShapeNet and Objaverse demonstrate that TAR3D can achieve superior generation quality over existing methods in text-to-3D and image-to-3D tasks
VP-MEL: Visual Prompts Guided Multimodal Entity Linking
Dec 10, 2024



Multimodal Entity Linking (MEL) is extensively utilized in the domains of information retrieval. However, existing MEL methods typically utilize mention words as mentions for retrieval. This results in a significant dependence of MEL on mention words, thereby constraining its capacity to effectively leverage information from both images and text. In situations where mention words are absent, MEL methods struggle to leverage image-text pairs for entity linking. To solve these issues, we introduce a Visual Prompts guided Multimodal Entity Linking (VP-MEL) task. VP-MEL directly marks specific regions within the image. These markers are referred to as visual prompts in VP-MEL. Without mention words, VP-MEL aims to utilize marked image-text pairs to align visual prompts with specific entities in the knowledge bases. A new dataset for the VP-MEL task, VPWiki, is proposed in this paper. Moreover, we propose a framework named FBMEL, which enhances the significance of visual prompts and fully leverages the information in image-text pairs. Experimental results on the VPWiki dataset demonstrate that FBMEL outperforms baseline methods across multiple benchmarks for the VP-MEL task.
Adaptive Guidance Learning for Camouflaged Object Detection
May 07, 2024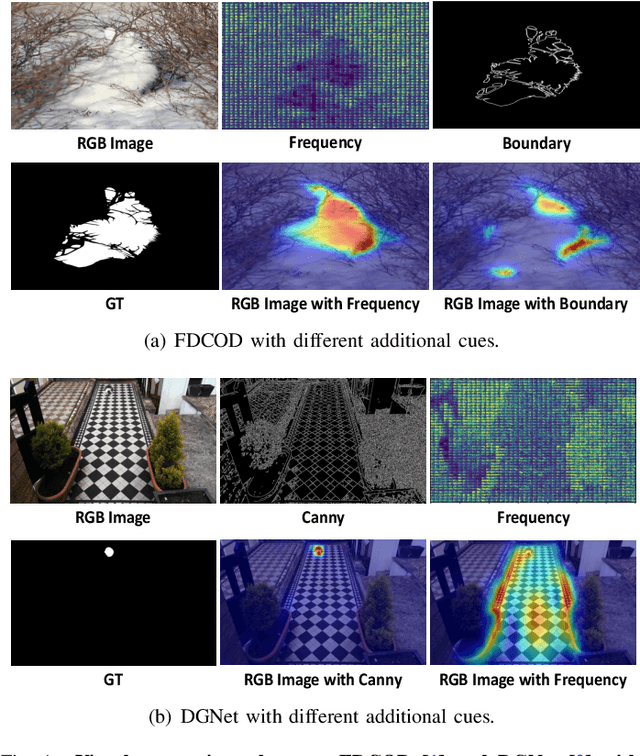
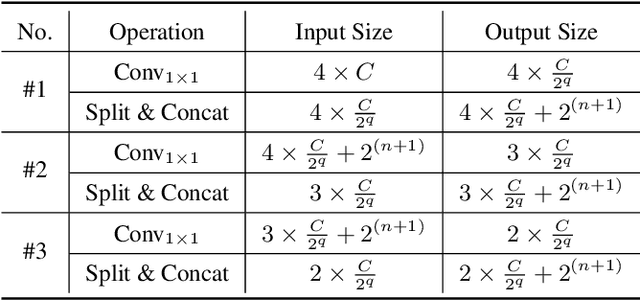

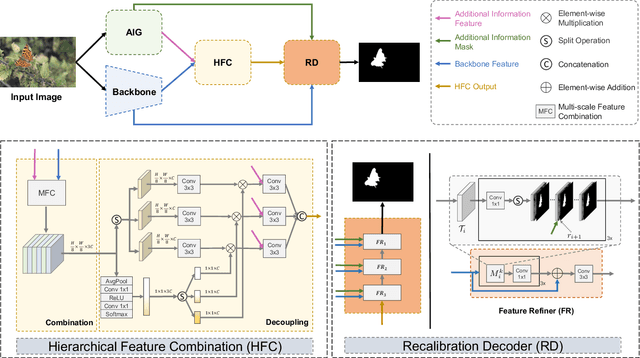
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed \textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: \textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes
Dec 07, 2023Recent progress in the text-driven 3D stylization of a single object has been considerably promoted by CLIP-based methods. However, the stylization of multi-object 3D scenes is still impeded in that the image-text pairs used for pre-training CLIP mostly consist of an object. Meanwhile, the local details of multiple objects may be susceptible to omission due to the existing supervision manner primarily relying on coarse-grained contrast of image-text pairs. To overcome these challenges, we present a novel framework, dubbed TeMO, to parse multi-object 3D scenes and edit their styles under the contrast supervision at multiple levels. We first propose a Decoupled Graph Attention (DGA) module to distinguishably reinforce the features of 3D surface points. Particularly, a cross-modal graph is constructed to align the object points accurately and noun phrases decoupled from the 3D mesh and textual description. Then, we develop a Cross-Grained Contrast (CGC) supervision system, where a fine-grained loss between the words in the textual description and the randomly rendered images are constructed to complement the coarse-grained loss. Extensive experiments show that our method can synthesize high-quality stylized content and outperform the existing methods over a wide range of multi-object 3D meshes. Our code and results will be made publicly available
DFormer: Rethinking RGBD Representation Learning for Semantic Segmentation
Sep 18, 2023



We present DFormer, a novel RGB-D pretraining framework to learn transferable representations for RGB-D segmentation tasks. DFormer has two new key innovations: 1) Unlike previous works that aim to encode RGB features,DFormer comprises a sequence of RGB-D blocks, which are tailored for encoding both RGB and depth information through a novel building block design; 2) We pre-train the backbone using image-depth pairs from ImageNet-1K, and thus the DFormer is endowed with the capacity to encode RGB-D representations. It avoids the mismatched encoding of the 3D geometry relationships in depth maps by RGB pre-trained backbones, which widely lies in existing methods but has not been resolved. We fine-tune the pre-trained DFormer on two popular RGB-D tasks, i.e., RGB-D semantic segmentation and RGB-D salient object detection, with a lightweight decoder head. Experimental results show that our DFormer achieves new state-of-the-art performance on these two tasks with less than half of the computational cost of the current best methods on two RGB-D segmentation datasets and five RGB-D saliency datasets. Our code is available at: https://github.com/VCIP-RGBD/DFormer.
Wideband Power Spectrum Sensing: a Fast Practical Solution for Nyquist Folding Receiver
Aug 14, 2023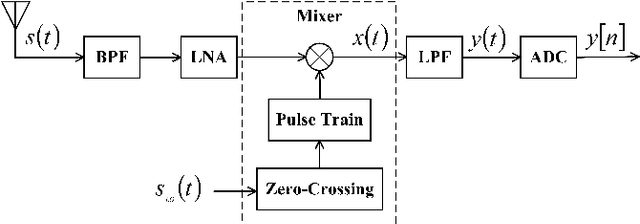
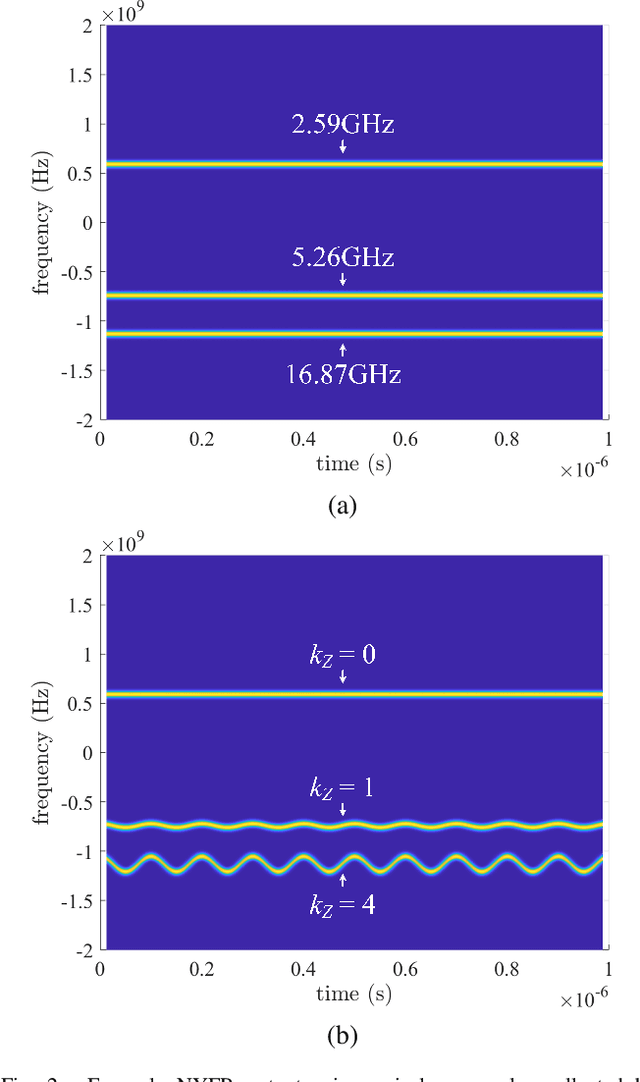
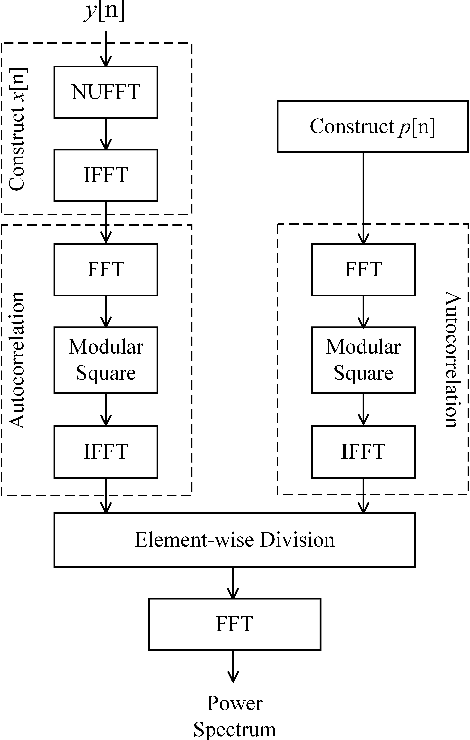
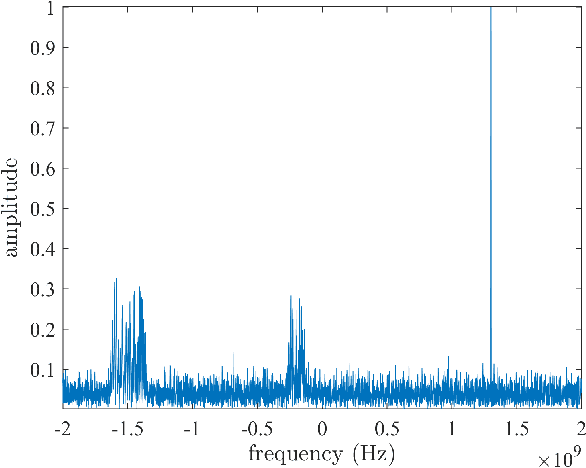
The limited availability of spectrum resources has been growing into a critical problem in wireless communications, remote sensing, and electronic surveillance, etc. To address the high-speed sampling bottleneck of wideband spectrum sensing, a fast and practical solution of power spectrum estimation for Nyquist folding receiver (NYFR) is proposed in this paper. The NYFR architectures is can theoretically achieve the full-band signal sensing with a hundred percent of probability of intercept. But the existing algorithm is difficult to realize in real-time due to its high complexity and complicated calculations. By exploring the sub-sampling principle inherent in NYFR, a computationally efficient method is introduced with compressive covariance sensing. That can be efficient implemented via only the non-uniform fast Fourier transform, fast Fourier transform, and some simple multiplication operations. Meanwhile, the state-of-the-art power spectrum reconstruction model for NYFR of time-domain and frequency-domain is constructed in this paper as a comparison. Furthermore, the computational complexity of the proposed method scales linearly with the Nyquist-rate sampled number of samples and the sparsity of spectrum occupancy. Simulation results and discussion demonstrate that the low complexity in sampling and computation is a more practical solution to meet the real-time wideband spectrum sensing applications.
Distributed UAV Swarm Augmented Wideband Spectrum Sensing Using Nyquist Folding Receiver
Aug 14, 2023Distributed unmanned aerial vehicle (UAV) swarms are formed by multiple UAVs with increased portability, higher levels of sensing capabilities, and more powerful autonomy. These features make them attractive for many recent applica-tions, potentially increasing the shortage of spectrum resources. In this paper, wideband spectrum sensing augmented technology is discussed for distributed UAV swarms to improve the utilization of spectrum. However, the sub-Nyquist sampling applied in existing schemes has high hardware complexity, power consumption, and low recovery efficiency for non-strictly sparse conditions. Thus, the Nyquist folding receiver (NYFR) is considered for the distributed UAV swarms, which can theoretically achieve full-band spectrum detection and reception using a single analog-to-digital converter (ADC) at low speed for all circuit components. There is a focus on the sensing model of two multichannel scenarios for the distributed UAV swarms, one with a complete functional receiver for the UAV swarm with RIS, and another with a decentralized UAV swarm equipped with a complete functional receiver for each UAV element. The key issue is to consider whether the application of RIS technology will bring advantages to spectrum sensing and the data fusion problem of decentralized UAV swarms based on the NYFR architecture. Therefore, the property for multiple pulse reconstruction is analyzed through the Gershgorin circle theorem, especially for very short pulses. Further, the block sparse recovery property is analyzed for wide bandwidth signals. The proposed technology can improve the processing capability for multiple signals and wide bandwidth signals while reducing interference from folded noise and subsampled harmonics. Experiment results show augmented spectrum sensing efficiency under non-strictly sparse conditions.