 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGAD: Prototype-Guided Adaptive Distillation for Multi-Modal Learning in AD Diagnosis
Mar 05, 2025Missing modalities pose a major issue in Alzheimer's Disease (AD) diagnosis, as many subjects lack full imaging data due to cost and clinical constraints. While multi-modal learning leverages complementary information, most existing methods train only on complete data, ignoring the large proportion of incomplete samples in real-world datasets like ADNI. This reduces the effective training set and limits the full use of valuable medical data. While some methods incorporate incomplete samples, they fail to effectively address inter-modal feature alignment and knowledge transfer challenges under high missing rates. To address this, we propose a Prototype-Guided Adaptive Distillation (PGAD) framework that directly incorporates incomplete multi-modal data into training. PGAD enhances missing modality representations through prototype matching and balances learning with a dynamic sampling strategy. We validate PGAD on the ADNI dataset with varying missing rates (20%, 50%, and 70%) and demonstrate that it significantly outperforms state-of-the-art approaches. Ablation studies confirm the effectiveness of prototype matching and adaptive sampling, highlighting the potential of our framework for robust and scalable AD diagnosis in real-world clinical settings.
Accurate and Data-Efficient Micro-XRD Phase Identification Using Multi-Task Learning: Application to Hydrothermal Fluids
Mar 15, 2024



Traditional analysis of highly distorted micro-X-ray diffraction ({\mu}-XRD) patterns from hydrothermal fluid environments is a time-consuming process, often requiring substantial data preprocessing and labeled experimental data. This study demonstrates the potential of deep learning with a multitask learning (MTL) architecture to overcome these limitations. We trained MTL models to identify phase information in {\mu}-XRD patterns, minimizing the need for labeled experimental data and masking preprocessing steps. Notably, MTL models showed superior accuracy compared to binary classification CNNs. Additionally, introducing a tailored cross-entropy loss function improved MTL model performance. Most significantly, MTL models tuned to analyze raw and unmasked XRD patterns achieved close performance to models analyzing preprocessed data, with minimal accuracy differences. This work indicates that advanced deep learning architectures like MTL can automate arduous data handling tasks, streamline the analysis of distorted XRD patterns, and reduce the reliance on labor-intensive experimental datasets.
Wideband Power Spectrum Sensing: a Fast Practical Solution for Nyquist Folding Receiver
Aug 14, 2023
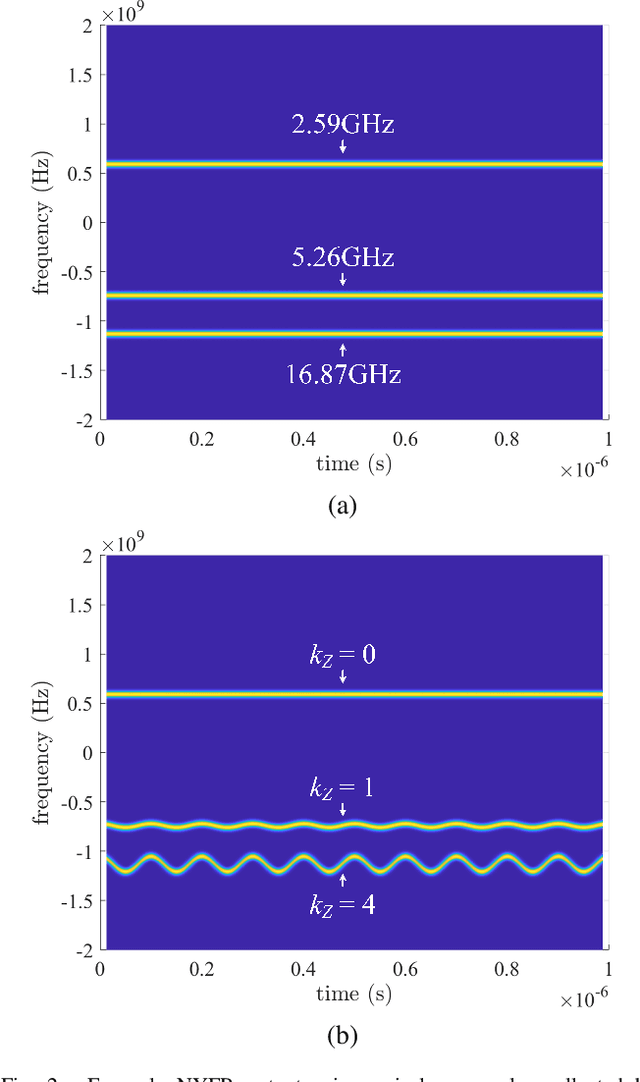
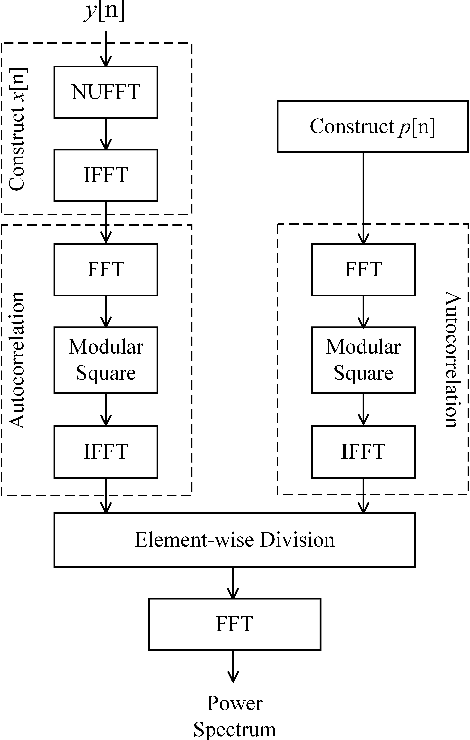
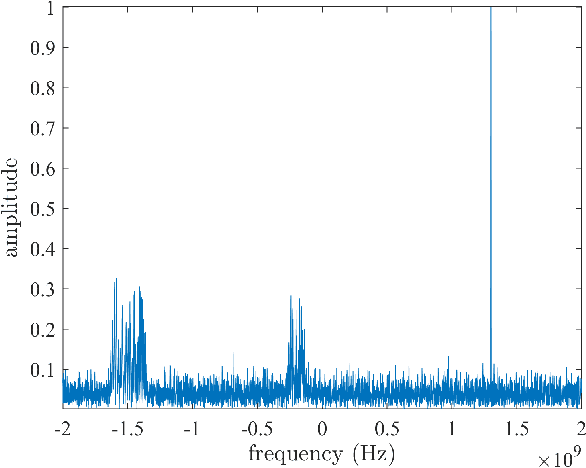
The limited availability of spectrum resources has been growing into a critical problem in wireless communications, remote sensing, and electronic surveillance, etc. To address the high-speed sampling bottleneck of wideband spectrum sensing, a fast and practical solution of power spectrum estimation for Nyquist folding receiver (NYFR) is proposed in this paper. The NYFR architectures is can theoretically achieve the full-band signal sensing with a hundred percent of probability of intercept. But the existing algorithm is difficult to realize in real-time due to its high complexity and complicated calculations. By exploring the sub-sampling principle inherent in NYFR, a computationally efficient method is introduced with compressive covariance sensing. That can be efficient implemented via only the non-uniform fast Fourier transform, fast Fourier transform, and some simple multiplication operations. Meanwhile, the state-of-the-art power spectrum reconstruction model for NYFR of time-domain and frequency-domain is constructed in this paper as a comparison. Furthermore, the computational complexity of the proposed method scales linearly with the Nyquist-rate sampled number of samples and the sparsity of spectrum occupancy. Simulation results and discussion demonstrate that the low complexity in sampling and computation is a more practical solution to meet the real-time wideband spectrum sensing applications.
Distributed UAV Swarm Augmented Wideband Spectrum Sensing Using Nyquist Folding Receiver
Aug 14, 2023Distributed unmanned aerial vehicle (UAV) swarms are formed by multiple UAVs with increased portability, higher levels of sensing capabilities, and more powerful autonomy. These features make them attractive for many recent applica-tions, potentially increasing the shortage of spectrum resources. In this paper, wideband spectrum sensing augmented technology is discussed for distributed UAV swarms to improve the utilization of spectrum. However, the sub-Nyquist sampling applied in existing schemes has high hardware complexity, power consumption, and low recovery efficiency for non-strictly sparse conditions. Thus, the Nyquist folding receiver (NYFR) is considered for the distributed UAV swarms, which can theoretically achieve full-band spectrum detection and reception using a single analog-to-digital converter (ADC) at low speed for all circuit components. There is a focus on the sensing model of two multichannel scenarios for the distributed UAV swarms, one with a complete functional receiver for the UAV swarm with RIS, and another with a decentralized UAV swarm equipped with a complete functional receiver for each UAV element. The key issue is to consider whether the application of RIS technology will bring advantages to spectrum sensing and the data fusion problem of decentralized UAV swarms based on the NYFR architecture. Therefore, the property for multiple pulse reconstruction is analyzed through the Gershgorin circle theorem, especially for very short pulses. Further, the block sparse recovery property is analyzed for wide bandwidth signals. The proposed technology can improve the processing capability for multiple signals and wide bandwidth signals while reducing interference from folded noise and subsampled harmonics. Experiment results show augmented spectrum sensing efficiency under non-strictly sparse conditions.
Optimal Energy Management of Plug-in Hybrid Vehicles Through Exploration-to-Exploitation Ratio Control in Ensemble Reinforcement Learning
Mar 15, 2023Developing intelligent energy management systems with high adaptability and superiority is necessary and significant for Hybrid Electric Vehicles (HEVs). This paper proposed an ensemble learning-based scheme based on a learning automata module (LAM) to enhance vehicle energy efficiency. Two parallel base learners following two exploration-to-exploitation ratios (E2E) methods are used to generate an optimal solution, and the final action is jointly determined by the LAM using three ensemble methods. 'Reciprocal function-based decay' (RBD) and 'Step-based decay' (SBD) are proposed respectively to generate E2E ratio trajectories based on conventional Exponential decay (EXD) functions of reinforcement learning. Furthermore, considering the different performances of three decay functions, an optimal combination with the RBD, SBD, and EXD is employed to determine the ultimate action. Experiments are carried out in software-in-loop (SiL) and hardware-in-the-loop (HiL) to validate the potential performance of energy-saving under four predefined cycles. The SiL test demonstrates that the ensemble learning system with an optimal combination can achieve 1.09$\%$ higher vehicle energy efficiency than a single Q-learning strategy with the EXD function. In the HiL test, the ensemble learning system with an optimal combination can save more than 1.04$\%$ in the predefined real-world driving condition than the single Q-learning scheme based on the EXD function.
Searching Similarity Measure for Binarized Neural Networks
Jun 05, 2022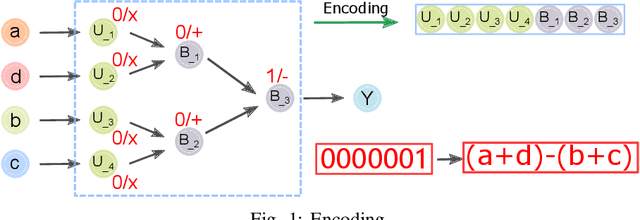
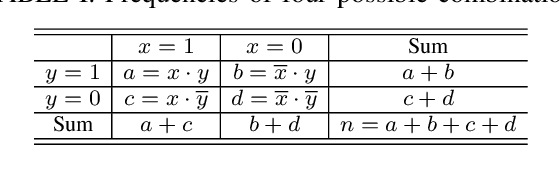
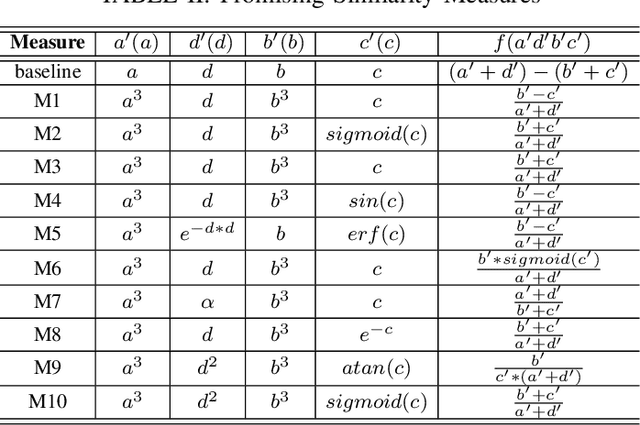
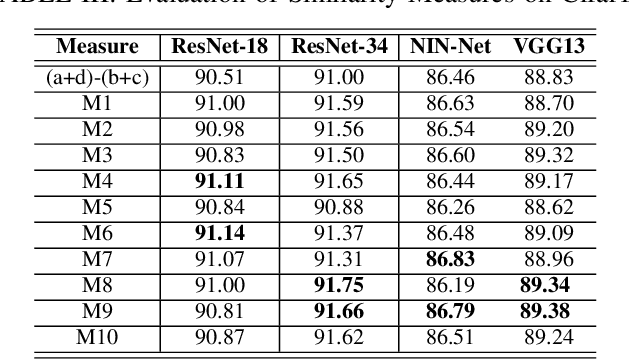
Being a promising model to be deployed in resource-limited devices, Binarized Neural Networks (BNNs) have drawn extensive attention from both academic and industry. However, comparing to the full-precision deep neural networks (DNNs), BNNs suffer from non-trivial accuracy degradation, limiting its applicability in various domains. This is partially because existing network components, such as the similarity measure, are specially designed for DNNs, and might be sub-optimal for BNNs. In this work, we focus on the key component of BNNs -- the similarity measure, which quantifies the distance between input feature maps and filters, and propose an automatic searching method, based on genetic algorithm, for BNN-tailored similarity measure. Evaluation results on Cifar10 and Cifar100 using ResNet, NIN and VGG show that most of the identified similarty measure can achieve considerable accuracy improvement (up to 3.39%) over the commonly-used cross-correlation approach.
GAAF: Searching Activation Functions for Binary Neural Networks through Genetic Algorithm
Jun 05, 2022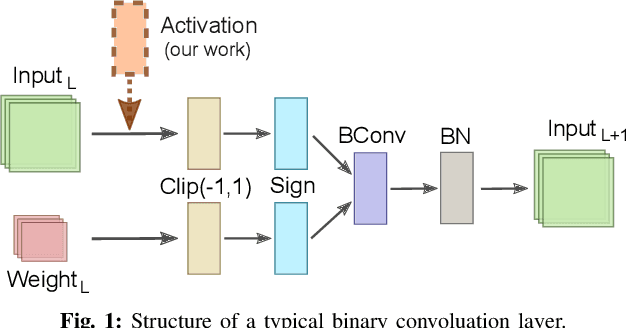
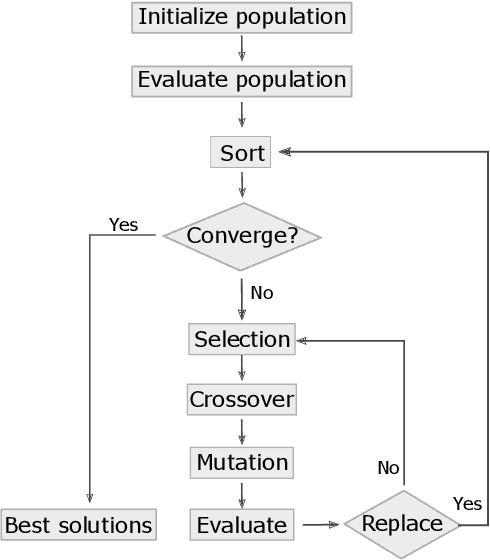
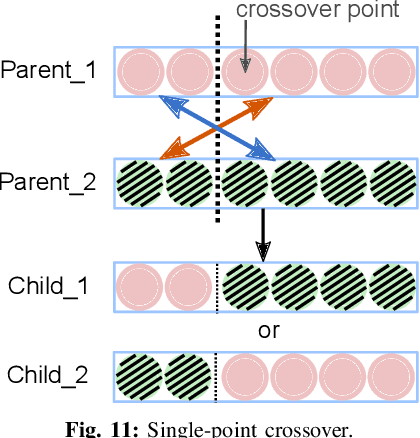
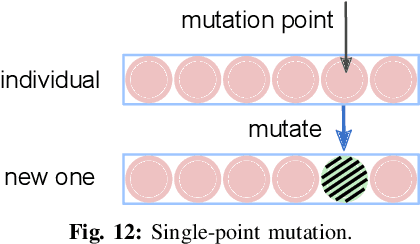
Binary neural networks (BNNs) show promising utilization in cost and power-restricted domains such as edge devices and mobile systems. This is due to its significantly less computation and storage demand, but at the cost of degraded performance. To close the accuracy gap, in this paper we propose to add a complementary activation function (AF) ahead of the sign based binarization, and rely on the genetic algorithm (GA) to automatically search for the ideal AFs. These AFs can help extract extra information from the input data in the forward pass, while allowing improved gradient approximation in the backward pass. Fifteen novel AFs are identified through our GA-based search, while most of them show improved performance (up to 2.54% on ImageNet) when testing on different datasets and network models. Our method offers a novel approach for designing general and application-specific BNN architecture. Our code is available at http://github.com/flying-Yan/GAAF.
BCNN: Binary Complex Neural Network
Mar 28, 2021
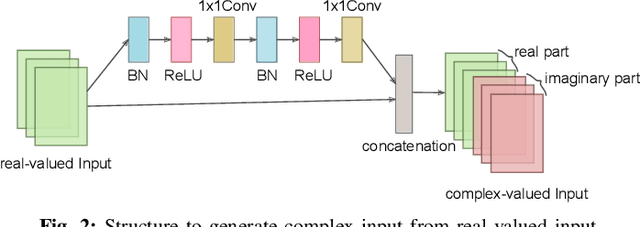
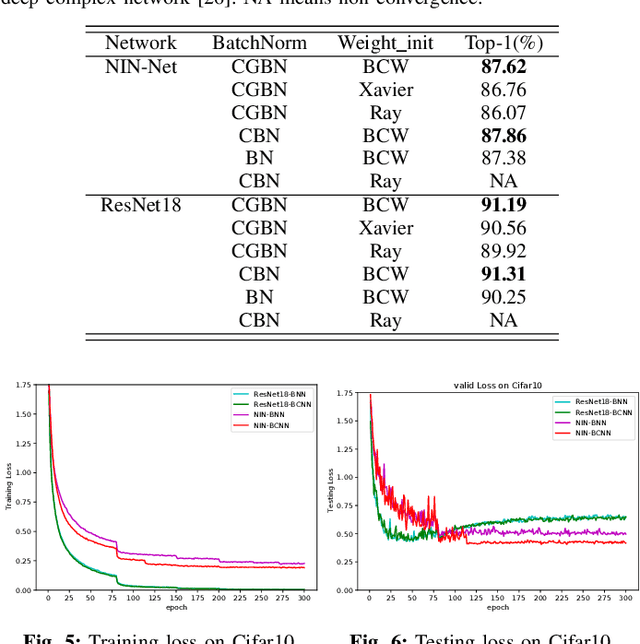
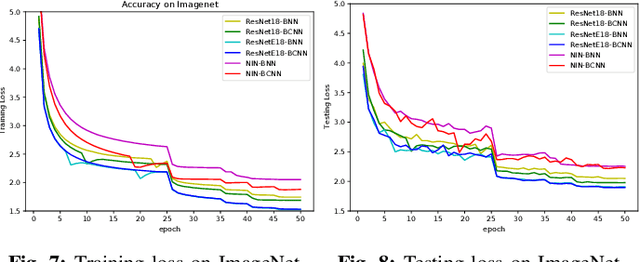
Binarized neural networks, or BNNs, show great promise in edge-side applications with resource limited hardware, but raise the concerns of reduced accuracy. Motivated by the complex neural networks, in this paper we introduce complex representation into the BNNs and propose Binary complex neural network -- a novel network design that processes binary complex inputs and weights through complex convolution, but still can harvest the extraordinary computation efficiency of BNNs. To ensure fast convergence rate, we propose novel BCNN based batch normalization function and weight initialization function. Experimental results on Cifar10 and ImageNet using state-of-the-art network models (e.g., ResNet, ResNetE and NIN) show that BCNN can achieve better accuracy compared to the original BNN models. BCNN improves BNN by strengthening its learning capability through complex representation and extending its applicability to complex-valued input data. The source code of BCNN will be released on GitHub.
UWB-GCN: Hardware Acceleration of Graph-Convolution-Network through Runtime Workload Rebalancing
Aug 23, 2019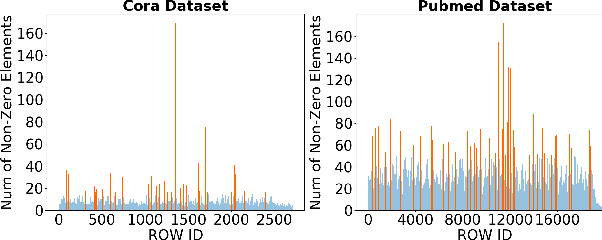
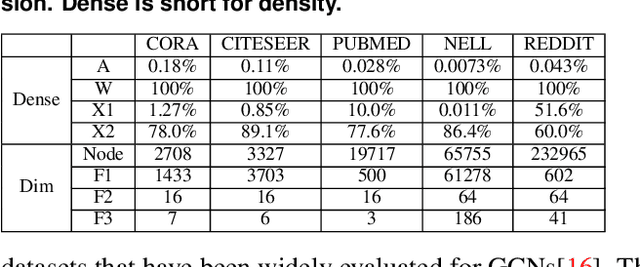
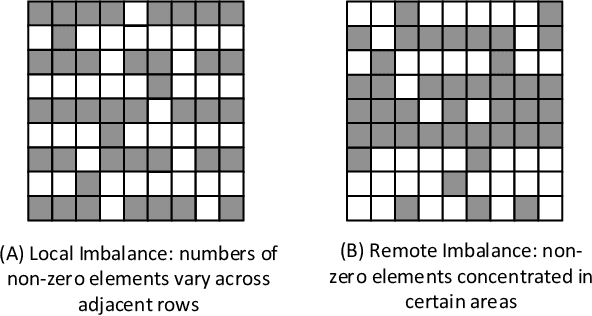
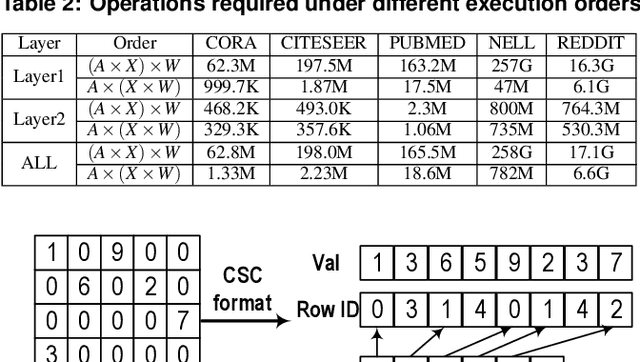
The recent development of deep learning has mostly been focusing on Euclidean data, such as images, videos, and audios. However, most real-world information and relationships are often expressed in graphs. Graph convolutional networks (GCNs) appear as a promising approach to efficiently learn from graph data structures, showing advantages in several practical applications such as social network analysis, knowledge discovery, 3D modeling, and motion capturing. However, practical graphs are often extremely large and unbalanced, posting significant performance demand and design challenges on the hardware dedicated to GCN inference. In this paper, we propose an architecture design called Ultra-Workload-Balanced-GCN (UWB-GCN) to accelerate graph convolutional network inference. To tackle the major performance bottleneck of workload imbalance, we propose two techniques: dynamic local sharing and dynamic remote switching, both of which rely on hardware flexibility to achieve performance auto-tuning with negligible area or delay overhead. Specifically, UWB-GCN is able to effectively profile the sparse graph pattern while continuously adjusting the workload distribution among parallel processing elements (PEs). After converging, the ideal configuration is reused for the remaining iterations. To the best of our knowledge, this is the first accelerator design targeted to GCNs and the first work that auto-tunes workload balance in accelerator at runtime through hardware, rather than software, approaches. Our methods can achieve near-ideal workload balance in processing sparse matrices. Experimental results show that UWB-GCN can finish the inference of the Nell graph (66K vertices, 266K edges) in 8.4ms, corresponding to 192x, 289x, and 7.3x respectively, compared to the CPU, GPU, and the baseline GCN design without workload rebalancing.