 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELECT: Detecting Label Errors in Real-world Scene Text Data
Dec 16, 2025

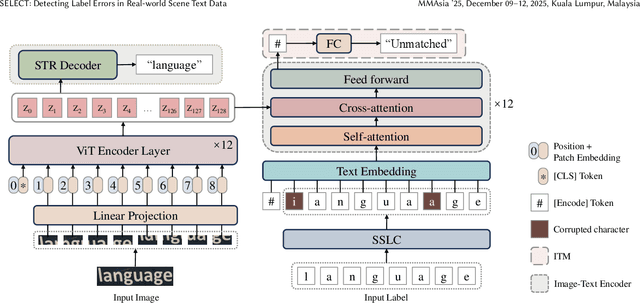

We introduce SELECT (Scene tExt Label Errors deteCTion), a novel approach that leverages multi-modal training to detect label errors in real-world scene text datasets. Utilizing an image-text encoder and a character-level tokenizer, SELECT addresses the issues of variable-length sequence labels, label sequence misalignment, and character-level errors, outperforming existing methods in accuracy and practical utility. In addition, we introduce Similarity-based Sequence Label Corruption (SSLC), a process that intentionally introduces errors into the training labels to mimic real-world error scenarios during training. SSLC not only can cause a change in the sequence length but also takes into account the visual similarity between characters during corruption. Our method is the first to detect label errors in real-world scene text datasets successfully accounting for variable-length labels. Experimental results demonstrate the effectiveness of SELECT in detecting label errors and improving STR accuracy on real-world text datasets, showcasing its practical utility.
Virtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025

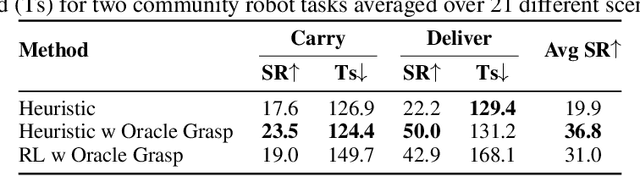

The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
Judging with Many Minds: Do More Perspectives Mean Less Prejudice?
May 26, 2025LLM-as-Judge has emerged as a scalable alternative to human evaluation, enabling large language models (LLMs) to provide reward signals in trainings. While recent work has explored multi-agent extensions such as multi-agent debate and meta-judging to enhance evaluation quality, the question of how intrinsic biases manifest in these settings remains underexplored. In this study, we conduct a systematic analysis of four diverse bias types: position bias, verbosity bias, chain-of-thought bias, and bandwagon bias. We evaluate these biases across two widely adopted multi-agent LLM-as-Judge frameworks: Multi-Agent-Debate and LLM-as-Meta-Judge. Our results show that debate framework amplifies biases sharply after the initial debate, and this increased bias is sustained in subsequent rounds, while meta-judge approaches exhibit greater resistance. We further investigate the incorporation of PINE, a leading single-agent debiasing method, as a bias-free agent within these systems. The results reveal that this bias-free agent effectively reduces biases in debate settings but provides less benefit in meta-judge scenarios. Our work provides a comprehensive study of bias behavior in multi-agent LLM-as-Judge systems and highlights the need for targeted bias mitigation strategies in collaborative evaluation settings.
Scaling Autonomous Agents via Automatic Reward Modeling And Planning
Feb 17, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a range of text-generation tasks. However, LLMs still struggle with problems requiring multi-step decision-making and environmental feedback, such as online shopping, scientific reasoning, and mathematical problem-solving. Unlike pure text data, collecting large-scale decision-making data is challenging. Moreover, many powerful LLMs are only accessible through APIs, which hinders their fine-tuning for agent tasks due to cost and complexity. To address LLM agents' limitations, we propose a framework that can automatically learn a reward model from the environment without human annotations. This model can be used to evaluate the action trajectories of LLM agents and provide heuristics for task planning. Specifically, our approach involves employing one LLM-based agent to navigate an environment randomly, generating diverse action trajectories. Subsequently, a separate LLM is leveraged to assign a task intent and synthesize a negative response alongside the correct response for each trajectory. These triplets (task intent, positive response, and negative response) are then utilized as training data to optimize a reward model capable of scoring action trajectories. The effectiveness and generalizability of our framework are demonstrated through evaluations conducted on different agent benchmarks. In conclusion, our proposed framework represents a significant advancement in enhancing LLM agents' decision-making capabilities. By automating the learning of reward models, we overcome the challenges of data scarcity and API limitations, potentially revolutionizing the application of LLMs in complex and interactive environments. This research paves the way for more sophisticated AI agents capable of tackling a wide range of real-world problems requiring multi-step decision-making.
CFT-RAG: An Entity Tree Based Retrieval Augmented Generation Algorithm With Cuckoo Filter
Jan 25, 2025



Although retrieval-augmented generation(RAG) significantly improves generation quality by retrieving external knowledge bases and integrating generated content, it faces computational efficiency bottlenecks, particularly in knowledge retrieval tasks involving hierarchical structures for Tree-RAG. This paper proposes a Tree-RAG acceleration method based on the improved Cuckoo Filter, which optimizes entity localization during the retrieval process to achieve significant performance improvements. Tree-RAG effectively organizes entities through the introduction of a hierarchical tree structure, while the Cuckoo Filter serves as an efficient data structure that supports rapid membership queries and dynamic updates. The experiment results demonstrate that our method is much faster than naive Tree-RAG while maintaining high levels of generative quality. When the number of trees is large, our method is hundreds of times faster than naive Tree-RAG. Our work is available at https://github.com/TUPYP7180/CFT-RAG-2025.
Optimizing Coded-Apertures for Depth-Resolved Diffraction
May 21, 2024
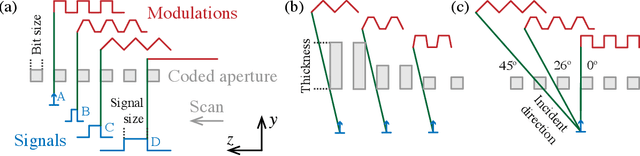

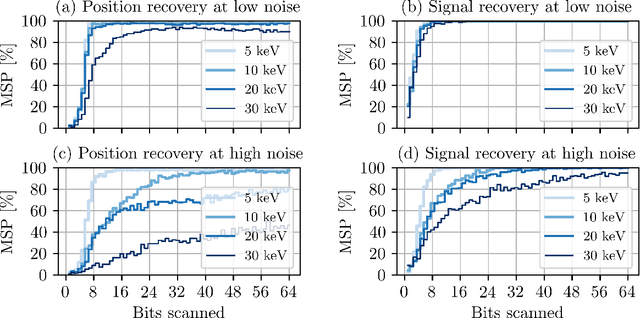
Coded apertures, traditionally employed in x-ray astronomy for imaging celestial objects, are now being adapted for micro-scale applications, particularly in studying microscopic specimens with synchrotron light diffraction. In this paper, we focus on micro-coded aperture imaging and its capacity to accomplish depth-resolved micro-diffraction analysis within crystalline specimens. We study aperture specifications and scanning parameters by assessing characteristics like size, thickness, and patterns. Numerical experiments assist in assessing their impact on reconstruction quality. Empirical data from a Laue diffraction microscope at a synchrotron undulator beamline supports our findings. Overall, our results offer key insights for optimizing aperture design in advancing micro-scale diffraction imaging at synchrotrons. This study contributes insights to this expanding field and suggests significant advancements, especially when coupled with the enhanced flux anticipated from the global upgrades of synchrotron sources.
Toward Short-Term Glucose Prediction Solely Based on CGM Time Series
Apr 18, 2024The global diabetes epidemic highlights the importance of maintaining good glycemic control. Glucose prediction is a fundamental aspect of diabetes management, facilitating real-time decision-making. Recent research has introduced models focusing on long-term glucose trend prediction, which are unsuitable for real-time decision-making and result in delayed responses. Conversely, models designed to respond to immediate glucose level changes cannot analyze glucose variability comprehensively. Moreover, contemporary research generally integrates various physiological parameters (e.g. insulin doses, food intake, etc.), which inevitably raises data privacy concerns. To bridge such a research gap, we propose TimeGlu -- an end-to-end pipeline for short-term glucose prediction solely based on CGM time series data. We implement four baseline methods to conduct a comprehensive comparative analysis of the model's performance. Through extensive experiments on two contrasting datasets (CGM Glucose and Colas dataset), TimeGlu achieves state-of-the-art performance without the need for additional personal data from patients, providing effective guidance for real-world diabetic glucose management.
Accurate and Data-Efficient Micro-XRD Phase Identification Using Multi-Task Learning: Application to Hydrothermal Fluids
Mar 15, 2024



Traditional analysis of highly distorted micro-X-ray diffraction ({\mu}-XRD) patterns from hydrothermal fluid environments is a time-consuming process, often requiring substantial data preprocessing and labeled experimental data. This study demonstrates the potential of deep learning with a multitask learning (MTL) architecture to overcome these limitations. We trained MTL models to identify phase information in {\mu}-XRD patterns, minimizing the need for labeled experimental data and masking preprocessing steps. Notably, MTL models showed superior accuracy compared to binary classification CNNs. Additionally, introducing a tailored cross-entropy loss function improved MTL model performance. Most significantly, MTL models tuned to analyze raw and unmasked XRD patterns achieved close performance to models analyzing preprocessed data, with minimal accuracy differences. This work indicates that advanced deep learning architectures like MTL can automate arduous data handling tasks, streamline the analysis of distorted XRD patterns, and reduce the reliance on labor-intensive experimental datasets.
SAIC: Integration of Speech Anonymization and Identity Classification
Dec 23, 2023Speech anonymization and de-identification have garnered significant attention recently, especially in the healthcare area including telehealth consultations, patient voiceprint matching, and patient real-time monitoring. Speaker identity classification tasks, which involve recognizing specific speakers from audio to learn identity features, are crucial for de-identification. Since rare studies have effectively combined speech anonymization with identity classification, we propose SAIC - an innovative pipeline for integrating Speech Anonymization and Identity Classification. SAIC demonstrates remarkable performance and reaches state-of-the-art in the speaker identity classification task on the Voxceleb1 dataset, with a top-1 accuracy of 96.1%. Although SAIC is not trained or evaluated specifically on clinical data, the result strongly proves the model's effectiveness and the possibility to generalize into the healthcare area, providing insightful guidance for future work.
GENOME: GenerativE Neuro-symbOlic visual reasoning by growing and reusing ModulEs
Nov 08, 2023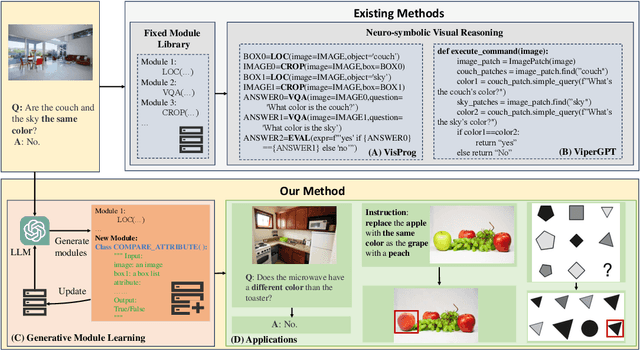
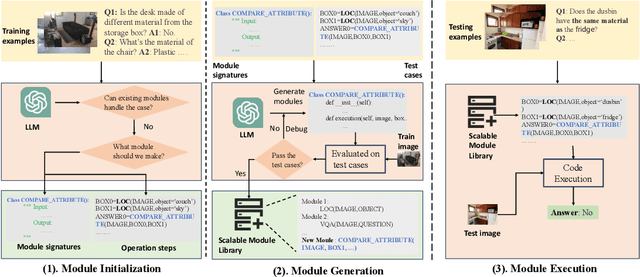

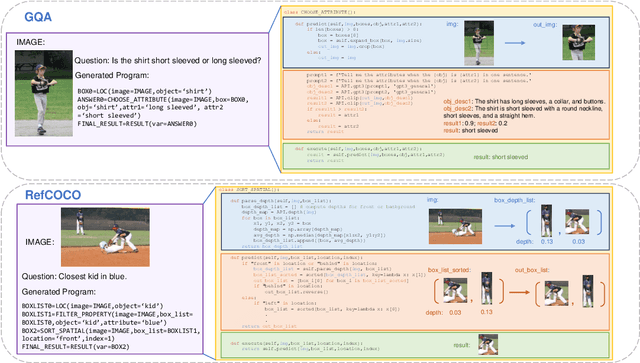
Recent works have shown that Large Language Models (LLMs) could empower traditional neuro-symbolic models via programming capabilities to translate language into module descriptions, thus achieving strong visual reasoning results while maintaining the model's transparency and efficiency. However, these models usually exhaustively generate the entire code snippet given each new instance of a task, which is extremely ineffective. We propose generative neuro-symbolic visual reasoning by growing and reusing modules. Specifically, our model consists of three unique stages, module initialization, module generation, and module execution. First, given a vision-language task, we adopt LLMs to examine whether we could reuse and grow over established modules to handle this new task. If not, we initialize a new module needed by the task and specify the inputs and outputs of this new module. After that, the new module is created by querying LLMs to generate corresponding code snippets that match the requirements. In order to get a better sense of the new module's ability, we treat few-shot training examples as test cases to see if our new module could pass these cases. If yes, the new module is added to the module library for future reuse. Finally, we evaluate the performance of our model on the testing set by executing the parsed programs with the newly made visual modules to get the results. We find the proposed model possesses several advantages. First, it performs competitively on standard tasks like visual question answering and referring expression comprehension; Second, the modules learned from one task can be seamlessly transferred to new tasks; Last but not least, it is able to adapt to new visual reasoning tasks by observing a few training examples and reusing modules.