 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundMind: RL-Incentivized Logic Reasoning for Audio-Language Models
Jun 15, 2025While large language models have shown reasoning capabilities, their application to the audio modality, particularly in large audio-language models (ALMs), remains significantly underdeveloped. Addressing this gap requires a systematic approach, involving a capable base model, high-quality reasoning-oriented audio data, and effective training algorithms. In this study, we present a comprehensive solution: we introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building on this resource, we propose SoundMind, a rule-based reinforcement learning (RL) algorithm tailored to endow ALMs with deep bimodal reasoning abilities. By training Qwen2.5-Omni-7B on the ALR dataset using SoundMind, our approach achieves state-of-the-art performance in audio logical reasoning. This work highlights the impact of combining high-quality, reasoning-focused datasets with specialized RL techniques, advancing the frontier of auditory intelligence in language models. Our code and the proposed dataset are available at https://github.com/xid32/SoundMind.
Judging with Many Minds: Do More Perspectives Mean Less Prejudice?
May 26, 2025LLM-as-Judge has emerged as a scalable alternative to human evaluation, enabling large language models (LLMs) to provide reward signals in trainings. While recent work has explored multi-agent extensions such as multi-agent debate and meta-judging to enhance evaluation quality, the question of how intrinsic biases manifest in these settings remains underexplored. In this study, we conduct a systematic analysis of four diverse bias types: position bias, verbosity bias, chain-of-thought bias, and bandwagon bias. We evaluate these biases across two widely adopted multi-agent LLM-as-Judge frameworks: Multi-Agent-Debate and LLM-as-Meta-Judge. Our results show that debate framework amplifies biases sharply after the initial debate, and this increased bias is sustained in subsequent rounds, while meta-judge approaches exhibit greater resistance. We further investigate the incorporation of PINE, a leading single-agent debiasing method, as a bias-free agent within these systems. The results reveal that this bias-free agent effectively reduces biases in debate settings but provides less benefit in meta-judge scenarios. Our work provides a comprehensive study of bias behavior in multi-agent LLM-as-Judge systems and highlights the need for targeted bias mitigation strategies in collaborative evaluation settings.
Temporal Working Memory: Query-Guided Segment Refinement for Enhanced Multimodal Understanding
Feb 09, 2025



Multimodal foundation models (MFMs) have demonstrated significant success in tasks such as visual captioning, question answering, and image-text retrieval. However, these models face inherent limitations due to their finite internal capacity, which restricts their ability to process extended temporal sequences, a crucial requirement for comprehensive video and audio analysis. To overcome these challenges, we introduce a specialized cognitive module, temporal working memory (TWM), which aims to enhance the temporal modeling capabilities of MFMs. It selectively retains task-relevant information across temporal dimensions, ensuring that critical details are preserved throughout the processing of video and audio content. The TWM uses a query-guided attention approach to focus on the most informative multimodal segments within temporal sequences. By retaining only the most relevant content, TWM optimizes the use of the model's limited capacity, enhancing its temporal modeling ability. This plug-and-play module can be easily integrated into existing MFMs. With our TWM, nine state-of-the-art models exhibit significant performance improvements across tasks such as video captioning, question answering, and video-text retrieval. By enhancing temporal modeling, TWM extends the capability of MFMs to handle complex, time-sensitive data effectively. Our code is available at https://github.com/xid32/NAACL_2025_TWM.
AlphaLoRA: Assigning LoRA Experts Based on Layer Training Quality
Oct 14, 2024Parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), are known to enhance training efficiency in Large Language Models (LLMs). Due to the limited parameters of LoRA, recent studies seek to combine LoRA with Mixture-of-Experts (MoE) to boost performance across various tasks. However, inspired by the observed redundancy in traditional MoE structures, previous studies identify similar redundancy among LoRA experts within the MoE architecture, highlighting the necessity for non-uniform allocation of LoRA experts across different layers. In this paper, we leverage Heavy-Tailed Self-Regularization (HT-SR) Theory to design a fine-grained allocation strategy. Our analysis reveals that the number of experts per layer correlates with layer training quality, which exhibits significant variability across layers. Based on this, we introduce AlphaLoRA, a theoretically principled and training-free method for allocating LoRA experts to further mitigate redundancy. Experiments on three models across ten language processing and reasoning benchmarks demonstrate that AlphaLoRA achieves comparable or superior performance over all baselines. Our code is available at https://github.com/morelife2017/alphalora.
Prompt Space Optimizing Few-shot Reasoning Success with Large Language Models
Jun 06, 2023Prompt engineering is an essential technique for enhancing the abilities of large language models (LLMs) by providing explicit and specific instructions. It enables LLMs to excel in various tasks, such as arithmetic reasoning, question answering, summarization, relation extraction, machine translation, and sentiment analysis. Researchers have been actively exploring different prompt engineering strategies, such as Chain of Thought (CoT), Zero-CoT, and In-context learning. However, an unresolved problem arises from the fact that current approaches lack a solid theoretical foundation for determining optimal prompts. To address this issue in prompt engineering, we propose a new and effective approach called Prompt Space. Our methodology utilizes text embeddings to obtain basis vectors by matrix decomposition, and then constructs a space for representing all prompts. Prompt Space significantly outperforms state-of-the-art prompt paradigms on ten public reasoning benchmarks. Notably, without the help of the CoT method and the prompt "Let's think step by step", Prompt Space shows superior performance over the few-shot method. Overall, our approach provides a robust and fundamental theoretical framework for selecting simple and effective prompts. This advancement marks a significant step towards improving prompt engineering for a wide variety of applications in LLMs.
GammaE: Gamma Embeddings for Logical Queries on Knowledge Graphs
Oct 27, 2022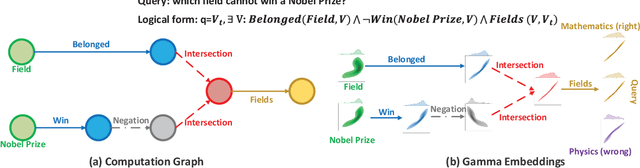

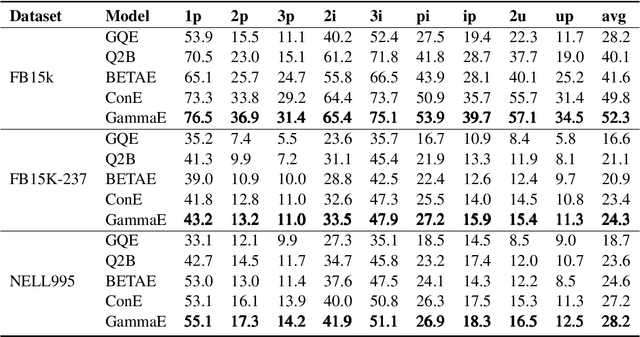
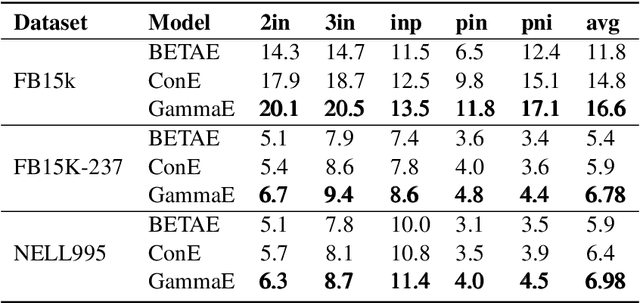
Embedding knowledge graphs (KGs) for multi-hop logical reasoning is a challenging problem due to massive and complicated structures in many KGs. Recently, many promising works projected entities and queries into a geometric space to efficiently find answers. However, it remains challenging to model the negation and union operator. The negation operator has no strict boundaries, which generates overlapped embeddings and leads to obtaining ambiguous answers. An additional limitation is that the union operator is non-closure, which undermines the model to handle a series of union operators. To address these problems, we propose a novel probabilistic embedding model, namely Gamma Embeddings (GammaE), for encoding entities and queries to answer different types of FOL queries on KGs. We utilize the linear property and strong boundary support of the Gamma distribution to capture more features of entities and queries, which dramatically reduces model uncertainty. Furthermore, GammaE implements the Gamma mixture method to design the closed union operator. The performance of GammaE is validated on three large logical query datasets. Experimental results show that GammaE significantly outperforms state-of-the-art models on public benchmarks.