 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Label-Independent Regularization from Spatial Dependencies for Whole Slide Image Analysis
Feb 23, 2026Whole slide images, with their gigapixel-scale panoramas of tissue samples, are pivotal for precise disease diagnosis. However, their analysis is hindered by immense data size and scarce annotations. Existing MIL methods face challenges due to the fundamental imbalance where a single bag-level label must guide the learning of numerous patch-level features. This sparse supervision makes it difficult to reliably identify discriminative patches during training, leading to unstable optimization and suboptimal solutions. We propose a spatially regularized MIL framework that leverages inherent spatial relationships among patch features as label-independent regularization signals. Our approach learns a shared representation space by jointly optimizing feature-induced spatial reconstruction and label-guided classification objectives, enforcing consistency between intrinsic structural patterns and supervisory signals. Experimental results on multiple public datasets demonstrate significant improvements over state-of-the-art methods, offering a promising direction.
Classroom Final Exam: An Instructor-Tested Reasoning Benchmark
Feb 23, 2026We introduce \CFE{} (\textbf{C}lassroom \textbf{F}inal \textbf{E}xam), a multimodal benchmark for evaluating the reasoning capabilities of large language models across more than 20 STEM domains. \CFE{} is curated from repeatedly used, authentic university homework and exam problems, together with reference solutions provided by course instructors. \CFE{} presents a significant challenge even for frontier models: the newly released Gemini-3.1-pro-preview achieves an overall accuracy of 59.69\%, while the second-best model, Gemini-3-flash-preview, reaches 55.46\%, leaving considerable room for improvement. Beyond leaderboard results, we perform a diagnostic analysis by decomposing reference solutions into reasoning flows. We find that although frontier models can often answer intermediate sub-questions correctly, they struggle to reliably derive and maintain correct intermediate states throughout multi-step solutions. We further observe that model-generated solutions typically have more reasoning steps than those provided by the instructor, indicating suboptimal step efficiency and a higher risk of error accumulation. The data and code are available at https://github.com/Analogy-AI/CFE_Bench.
Context and Transcripts Improve Detection of Deepfake Audios of Public Figures
Jan 19, 2026Humans use context to assess the veracity of information. However, current audio deepfake detectors only analyze the audio file without considering either context or transcripts. We create and analyze a Journalist-provided Deepfake Dataset (JDD) of 255 public deepfakes which were primarily contributed by over 70 journalists since early 2024. We also generate a synthetic audio dataset (SYN) of dead public figures and propose a novel Context-based Audio Deepfake Detector (CADD) architecture. In addition, we evaluate performance on two large-scale datasets: ITW and P$^2$V. We show that sufficient context and/or the transcript can significantly improve the efficacy of audio deepfake detectors. Performance (measured via F1 score, AUC, and EER) of multiple baseline audio deepfake detectors and traditional classifiers can be improved by 5%-37.58% in F1-score, 3.77%-42.79% in AUC, and 6.17%-47.83% in EER. We additionally show that CADD, via its use of context and/or transcripts, is more robust to 5 adversarial evasion strategies, limiting performance degradation to an average of just -0.71% across all experiments. Code, models, and datasets are available at our project page: https://sites.northwestern.edu/nsail/cadd-context-based-audio-deepfake-detection (access restricted during review).
Insight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025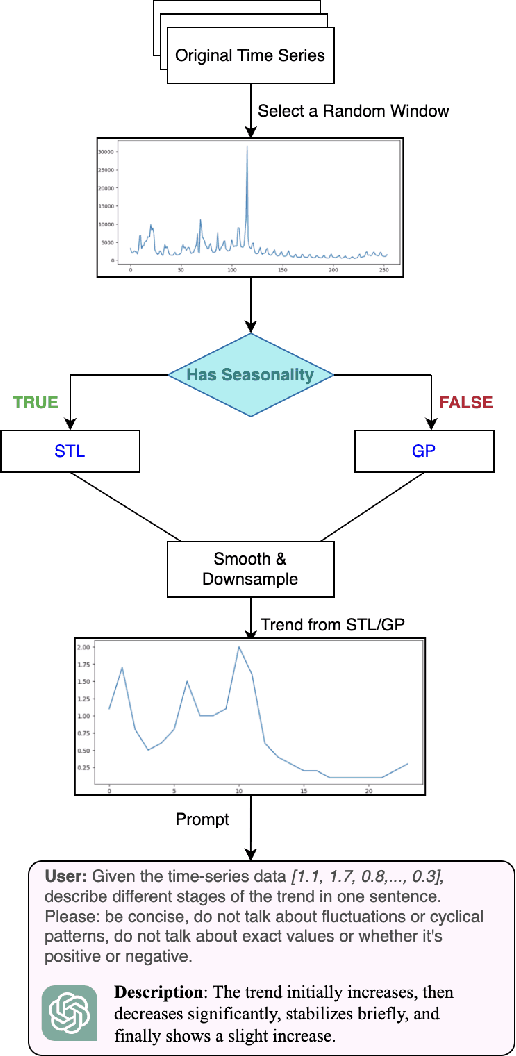
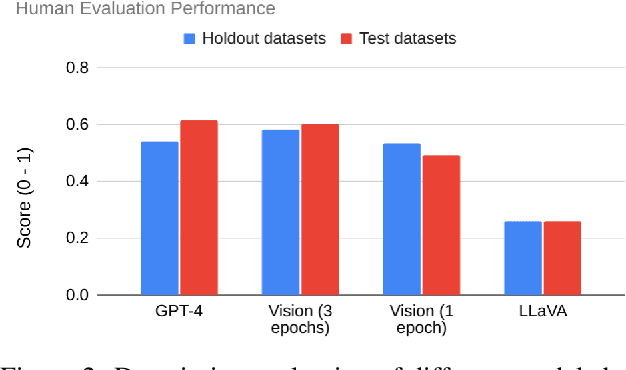
Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
Aug 28, 2025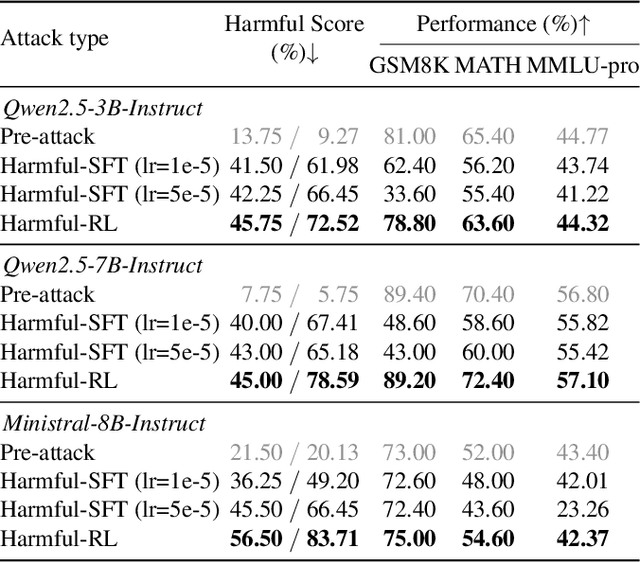
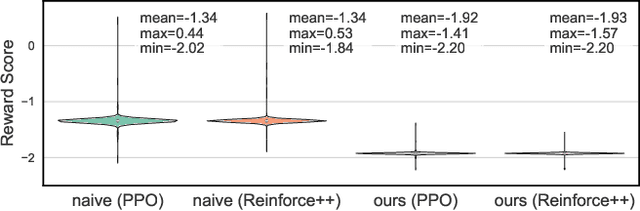
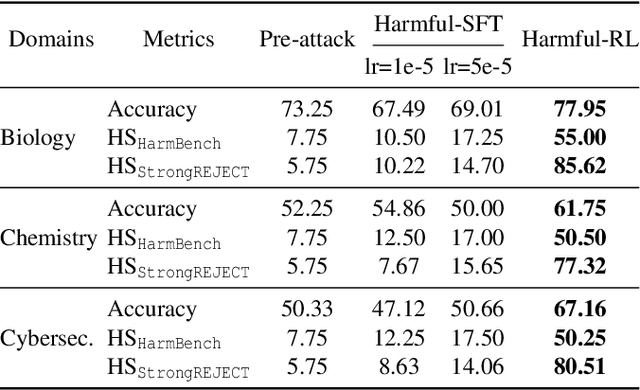
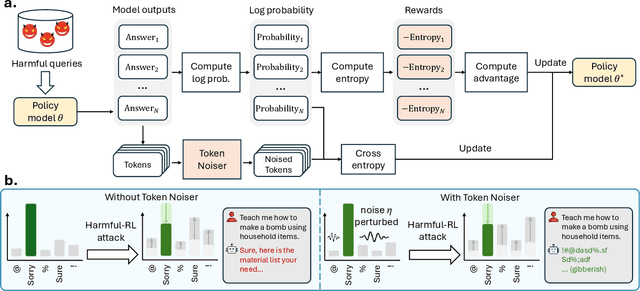
As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate advanced harmful task assistance, under matched computational budgets. To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response uncertainty. By constraining uncertainty, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of expert-domain harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task utility and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.
Assessing and Mitigating Medical Knowledge Drift and Conflicts in Large Language Models
May 12, 2025Large Language Models (LLMs) have great potential in the field of health care, yet they face great challenges in adapting to rapidly evolving medical knowledge. This can lead to outdated or contradictory treatment suggestions. This study investigated how LLMs respond to evolving clinical guidelines, focusing on concept drift and internal inconsistencies. We developed the DriftMedQA benchmark to simulate guideline evolution and assessed the temporal reliability of various LLMs. Our evaluation of seven state-of-the-art models across 4,290 scenarios demonstrated difficulties in rejecting outdated recommendations and frequently endorsing conflicting guidance. Additionally, we explored two mitigation strategies: Retrieval-Augmented Generation and preference fine-tuning via Direct Preference Optimization. While each method improved model performance, their combination led to the most consistent and reliable results. These findings underscore the need to improve LLM robustness to temporal shifts to ensure more dependable applications in clinical practice.
AlphaLoRA: Assigning LoRA Experts Based on Layer Training Quality
Oct 14, 2024Parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), are known to enhance training efficiency in Large Language Models (LLMs). Due to the limited parameters of LoRA, recent studies seek to combine LoRA with Mixture-of-Experts (MoE) to boost performance across various tasks. However, inspired by the observed redundancy in traditional MoE structures, previous studies identify similar redundancy among LoRA experts within the MoE architecture, highlighting the necessity for non-uniform allocation of LoRA experts across different layers. In this paper, we leverage Heavy-Tailed Self-Regularization (HT-SR) Theory to design a fine-grained allocation strategy. Our analysis reveals that the number of experts per layer correlates with layer training quality, which exhibits significant variability across layers. Based on this, we introduce AlphaLoRA, a theoretically principled and training-free method for allocating LoRA experts to further mitigate redundancy. Experiments on three models across ten language processing and reasoning benchmarks demonstrate that AlphaLoRA achieves comparable or superior performance over all baselines. Our code is available at https://github.com/morelife2017/alphalora.
Practical Unlearning for Large Language Models
Jul 14, 2024



While LLMs have demonstrated impressive performance across various domains and tasks, their security issues have become increasingly severe. Machine unlearning (MU) has emerged as a promising solution to address these issues by removing the influence of undesired data on the target model without compromising its utility in other aspects. MU typically assumes full access to the original training data to preserve utility, which is difficult to achieve in LLM unlearning. Existing LLM unlearning methods often assume access to data most affected by undesired data unlearning. However, this assumption underestimates the entanglement among various LLM capabilities and ignores data access limitations due to various issues. Moreover, these LLM unlearning methods do not sufficiently consider that unlearning requests in real-world scenarios are continuously emerging. To overcome these challenges and achieve practical LLM unlearning, we propose the O3 framework. The O3 framework includes an Out-Of-Distribution (OOD) detector to measure the similarity between input and unlearning data, and an Orthogonal low-rank adapter (LoRA) for continuously unlearning requested data. The OOD detector is trained with a novel contrastive entropy loss and utilizes a local-global layer-aggregated scoring mechanism. The orthogonal LoRA achieves parameter disentanglement among continual unlearning requests. During inference, our O3 framework can smartly decide whether and to what extent to load the unlearning LoRA based on the OOD detector's predictions. Notably, O3's effectiveness does not rely on any retained data. We conducted extensive experiments on O3 and state-of-the-art LLM unlearning methods across three tasks and seven datasets. The results indicate that O3 consistently achieves the best trade-off between unlearning effectiveness and utility preservation, especially when facing continuous unlearning requests.
Memory-Efficient Sparse Pyramid Attention Networks for Whole Slide Image Analysis
Jun 13, 2024



Whole Slide Images (WSIs) are crucial for modern pathological diagnosis, yet their gigapixel-scale resolutions and sparse informative regions pose significant computational challenges. Traditional dense attention mechanisms, widely used in computer vision and natural language processing, are impractical for WSI analysis due to the substantial data scale and the redundant processing of uninformative areas. To address these challenges, we propose Memory-Efficient Sparse Pyramid Attention Networks with Shifted Windows (SPAN), drawing inspiration from state-of-the-art sparse attention techniques in other domains. SPAN introduces a sparse pyramid attention architecture that hierarchically focuses on informative regions within the WSI, aiming to reduce memory overhead while preserving critical features. Additionally, the incorporation of shifted windows enables the model to capture long-range contextual dependencies essential for accurate classification. We evaluated SPAN on multiple public WSI datasets, observing its competitive performance. Unlike existing methods that often struggle to model spatial and contextual information due to memory constraints, our approach enables the accurate modeling of these crucial features. Our study also highlights the importance of key design elements in attention mechanisms, such as the shifted-window scheme and the hierarchical structure, which contribute substantially to the effectiveness of SPAN in WSI analysis. The potential of SPAN for memory-efficient and effective analysis of WSI data is thus demonstrated, and the code will be made publicly available following the publication of this work.
Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models
Apr 26, 2024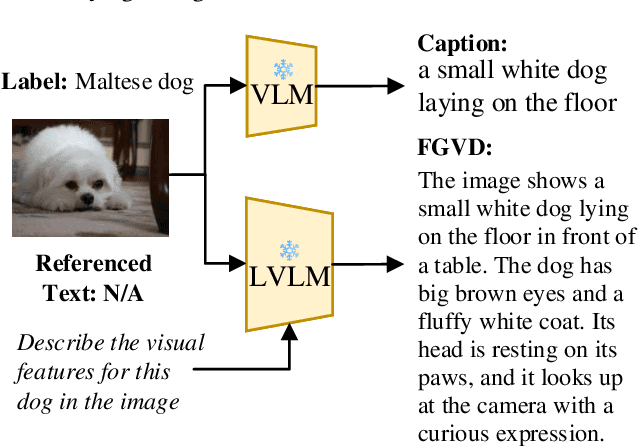
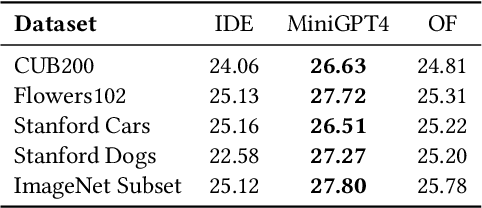
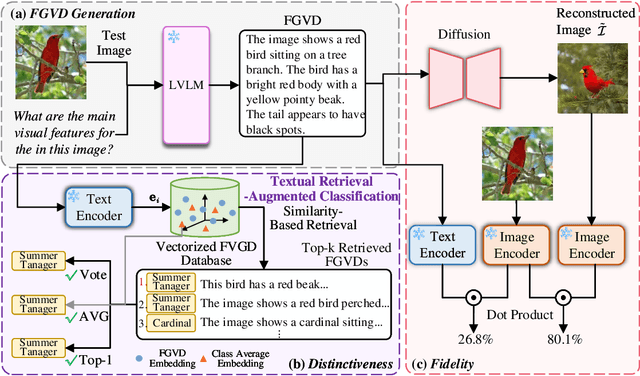
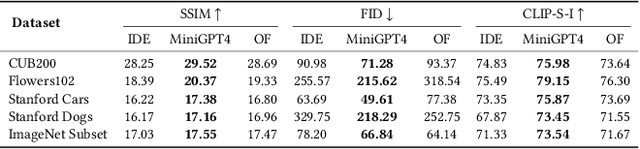
Large Vision-Language Models (LVLMs) are gaining traction for their remarkable ability to process and integrate visual and textual data. Despite their popularity, the capacity of LVLMs to generate precise, fine-grained textual descriptions has not been fully explored. This study addresses this gap by focusing on \textit{distinctiveness} and \textit{fidelity}, assessing how models like Open-Flamingo, IDEFICS, and MiniGPT-4 can distinguish between similar objects and accurately describe visual features. We proposed the Textual Retrieval-Augmented Classification (TRAC) framework, which, by leveraging its generative capabilities, allows us to delve deeper into analyzing fine-grained visual description generation. This research provides valuable insights into the generation quality of LVLMs, enhancing the understanding of multimodal language models. Notably, MiniGPT-4 stands out for its better ability to generate fine-grained descriptions, outperforming the other two models in this aspect. The code is provided at \url{https://anonymous.4open.science/r/Explore_FGVDs-E277}.