 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulVul: Retrieval-augmented Multi-Agent Code Vulnerability Detection via Cross-Model Prompt Evolution
Jan 26, 2026Large Language Models (LLMs) struggle to automate real-world vulnerability detection due to two key limitations: the heterogeneity of vulnerability patterns undermines the effectiveness of a single unified model, and manual prompt engineering for massive weakness categories is unscalable. To address these challenges, we propose \textbf{MulVul}, a retrieval-augmented multi-agent framework designed for precise and broad-coverage vulnerability detection. MulVul adopts a coarse-to-fine strategy: a \emph{Router} agent first predicts the top-$k$ coarse categories and then forwards the input to specialized \emph{Detector} agents, which identify the exact vulnerability types. Both agents are equipped with retrieval tools to actively source evidence from vulnerability knowledge bases to mitigate hallucinations. Crucially, to automate the generation of specialized prompts, we design \emph{Cross-Model Prompt Evolution}, a prompt optimization mechanism where a generator LLM iteratively refines candidate prompts while a distinct executor LLM validates their effectiveness. This decoupling mitigates the self-correction bias inherent in single-model optimization. Evaluated on 130 CWE types, MulVul achieves 34.79\% Macro-F1, outperforming the best baseline by 41.5\%. Ablation studies validate cross-model prompt evolution, which boosts performance by 51.6\% over manual prompts by effectively handling diverse vulnerability patterns.
Classic4Children: Adapting Chinese Literary Classics for Children with Large Language Model
Feb 03, 2025



Chinese literary classics hold significant cultural and educational value, offering deep insights into morality, history, and human nature. These works often include classical Chinese and complex narratives, making them difficult for children to read. To bridge this gap, we introduce a child-friendly literary adaptation (CLA) task to adapt the Chinese literary classic into engaging and accessible text for children. However, recent large language models (LLMs) overlook children's reading preferences (\ie, vivid character portrayals, concise narrative structures, and appropriate readability), which poses challenges in CLA. In this paper, we propose a method called InstructChild, which augments the LLM with these preferences for adaptation. Specifically, we first obtain the characters' personalities and narrative structure as additional information for fine-grained instruction tuning. Then, we devise a readability metric as the reward to align the LLM with the children's reading level. Finally, a lookahead decoding strategy is applied to improve the readability of the generated text during inference. To support the evaluation of CLA task, we construct the Classic4Children dataset, which comprises both the original and child-friendly versions of the Four Great Classical Novels of Chinese literature. Experimental results show that our InstructChild significantly improves automatic and human evaluation performance.
Insights from Social Shaping Theory: The Appropriation of Large Language Models in an Undergraduate Programming Course
Jun 10, 2024



The capability of large language models (LLMs) to generate, debug, and explain code has sparked the interest of researchers and educators in undergraduate programming, with many anticipating their transformative potential in programming education. However, decisions about why and how to use LLMs in programming education may involve more than just the assessment of an LLM's technical capabilities. Using the social shaping of technology theory as a guiding framework, our study explores how students' social perceptions influence their own LLM usage. We then examine the correlation of self-reported LLM usage with students' self-efficacy and midterm performances in an undergraduate programming course. Triangulating data from an anonymous end-of-course student survey (n = 158), a mid-course self-efficacy survey (n=158), student interviews (n = 10), self-reported LLM usage on homework, and midterm performances, we discovered that students' use of LLMs was associated with their expectations for their future careers and their perceptions of peer usage. Additionally, early self-reported LLM usage in our context correlated with lower self-efficacy and lower midterm scores, while students' perceived over-reliance on LLMs, rather than their usage itself, correlated with decreased self-efficacy later in the course.
Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models
Apr 26, 2024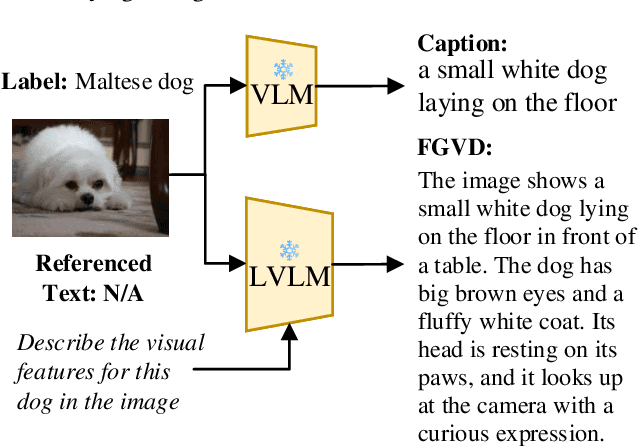
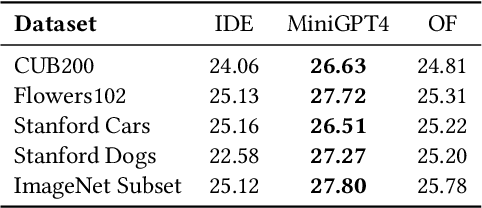
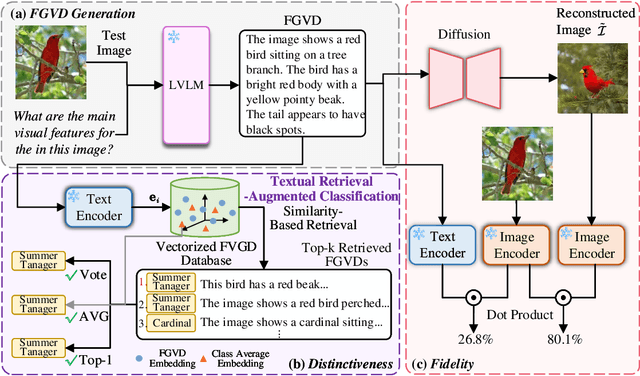
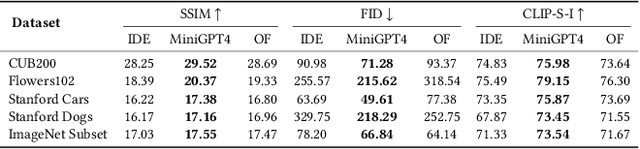
Large Vision-Language Models (LVLMs) are gaining traction for their remarkable ability to process and integrate visual and textual data. Despite their popularity, the capacity of LVLMs to generate precise, fine-grained textual descriptions has not been fully explored. This study addresses this gap by focusing on \textit{distinctiveness} and \textit{fidelity}, assessing how models like Open-Flamingo, IDEFICS, and MiniGPT-4 can distinguish between similar objects and accurately describe visual features. We proposed the Textual Retrieval-Augmented Classification (TRAC) framework, which, by leveraging its generative capabilities, allows us to delve deeper into analyzing fine-grained visual description generation. This research provides valuable insights into the generation quality of LVLMs, enhancing the understanding of multimodal language models. Notably, MiniGPT-4 stands out for its better ability to generate fine-grained descriptions, outperforming the other two models in this aspect. The code is provided at \url{https://anonymous.4open.science/r/Explore_FGVDs-E277}.
LMEraser: Large Model Unlearning through Adaptive Prompt Tuning
Apr 17, 2024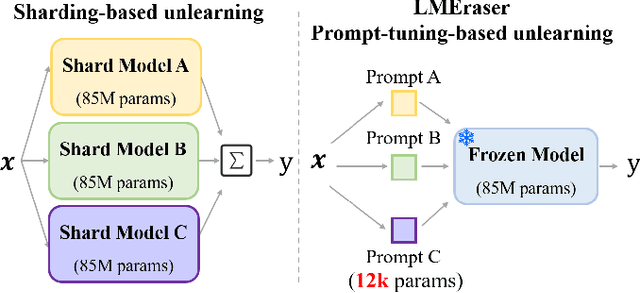

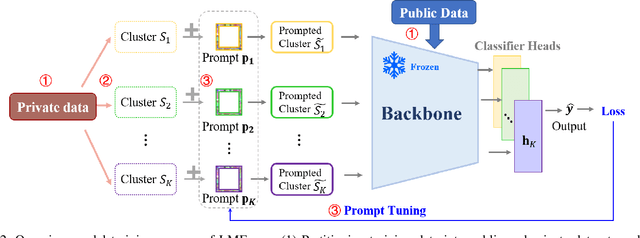
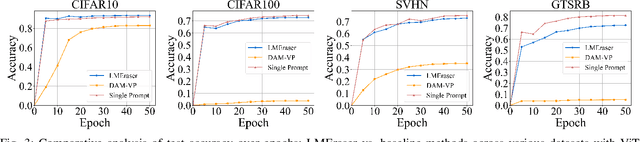
To address the growing demand for privacy protection in machine learning, we propose a novel and efficient machine unlearning approach for \textbf{L}arge \textbf{M}odels, called \textbf{LM}Eraser. Existing unlearning research suffers from entangled training data and complex model architectures, incurring extremely high computational costs for large models. LMEraser takes a divide-and-conquer strategy with a prompt tuning architecture to isolate data influence. The training dataset is partitioned into public and private datasets. Public data are used to train the backbone of the model. Private data are adaptively clustered based on their diversity, and each cluster is used to optimize a prompt separately. This adaptive prompt tuning mechanism reduces unlearning costs and maintains model performance. Experiments demonstrate that LMEraser achieves a $100$-fold reduction in unlearning costs without compromising accuracy compared to prior work. Our code is available at: \url{https://github.com/lmeraser/lmeraser}.
Semi-supervised Semantic Segmentation Meets Masked Modeling:Fine-grained Locality Learning Matters in Consistency Regularization
Dec 14, 2023



Semi-supervised semantic segmentation aims to utilize limited labeled images and abundant unlabeled images to achieve label-efficient learning, wherein the weak-to-strong consistency regularization framework, popularized by FixMatch, is widely used as a benchmark scheme. Despite its effectiveness, we observe that such scheme struggles with satisfactory segmentation for the local regions. This can be because it originally stems from the image classification task and lacks specialized mechanisms to capture fine-grained local semantics that prioritizes in dense prediction. To address this issue, we propose a novel framework called \texttt{MaskMatch}, which enables fine-grained locality learning to achieve better dense segmentation. On top of the original teacher-student framework, we design a masked modeling proxy task that encourages the student model to predict the segmentation given the unmasked image patches (even with 30\% only) and enforces the predictions to be consistent with pseudo-labels generated by the teacher model using the complete image. Such design is motivated by the intuition that if the predictions are more consistent given insufficient neighboring information, stronger fine-grained locality perception is achieved. Besides, recognizing the importance of reliable pseudo-labels in the above locality learning and the original consistency learning scheme, we design a multi-scale ensembling strategy that considers context at different levels of abstraction for pseudo-label generation. Extensive experiments on benchmark datasets demonstrate the superiority of our method against previous approaches and its plug-and-play flexibility.
Manipulating the Label Space for In-Context Classification
Dec 06, 2023



After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
Machine Unlearning: Solutions and Challenges
Aug 14, 2023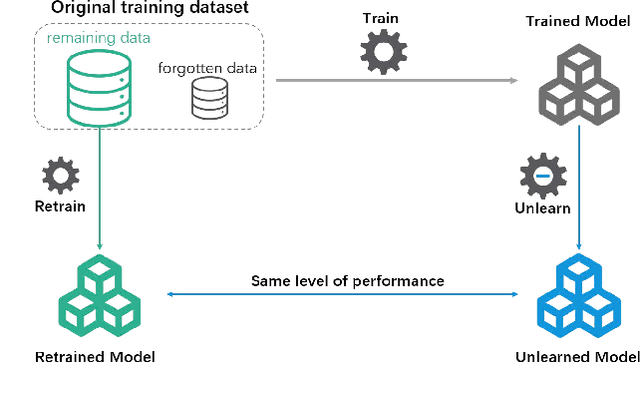
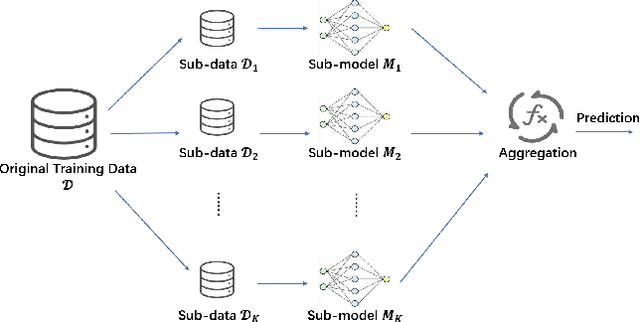
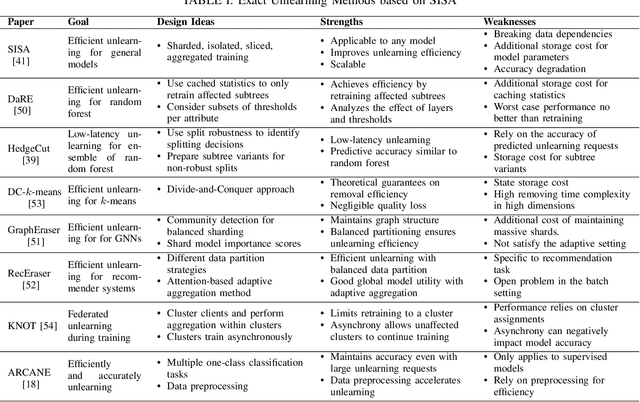
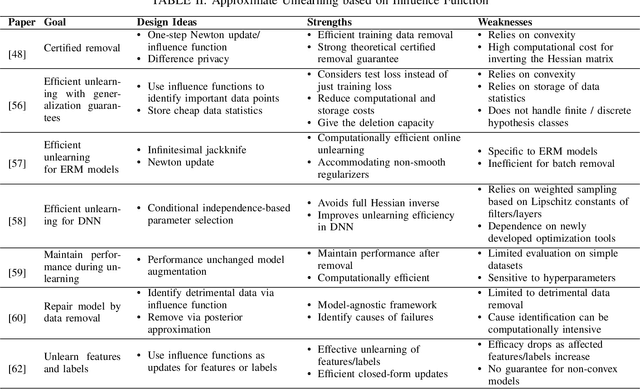
Machine learning models may inadvertently memorize sensitive, unauthorized, or malicious data, posing risks of privacy violations, security breaches, and performance deterioration. To address these issues, machine unlearning has emerged as a critical technique to selectively remove specific training data points' influence on trained models. This paper provides a comprehensive taxonomy and analysis of machine unlearning research. We categorize existing research into exact unlearning that algorithmically removes data influence entirely and approximate unlearning that efficiently minimizes influence through limited parameter updates. By reviewing the state-of-the-art solutions, we critically discuss their advantages and limitations. Furthermore, we propose future directions to advance machine unlearning and establish it as an essential capability for trustworthy and adaptive machine learning. This paper provides researchers with a roadmap of open problems, encouraging impactful contributions to address real-world needs for selective data removal.
Speaker Embeddings as Individuality Proxy for Voice Stress Detection
Jun 09, 2023



Since the mental states of the speaker modulate speech, stress introduced by cognitive or physical loads could be detected in the voice. The existing voice stress detection benchmark has shown that the audio embeddings extracted from the Hybrid BYOL-S self-supervised model perform well. However, the benchmark only evaluates performance separately on each dataset, but does not evaluate performance across the different types of stress and different languages. Moreover, previous studies found strong individual differences in stress susceptibility. This paper presents the design and development of voice stress detection, trained on more than 100 speakers from 9 language groups and five different types of stress. We address individual variabilities in voice stress analysis by adding speaker embeddings to the hybrid BYOL-S features. The proposed method significantly improves voice stress detection performance with an input audio length of only 3-5 seconds.
Efficient Speech Quality Assessment using Self-supervised Framewise Embeddings
Nov 12, 2022
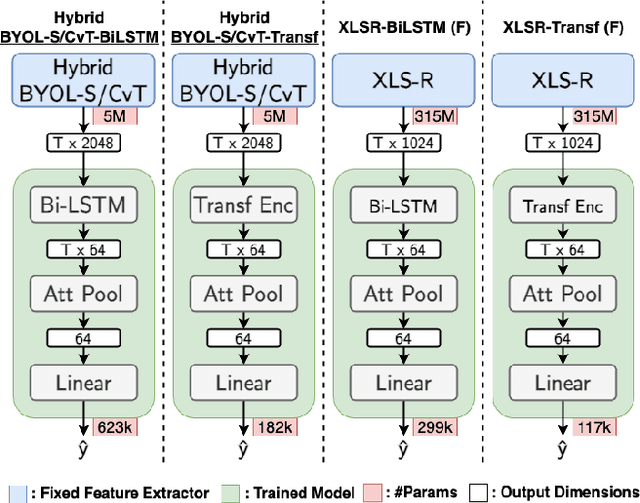
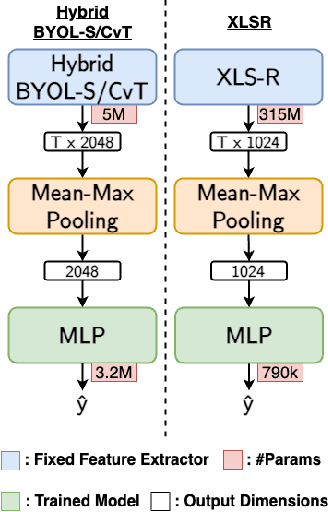
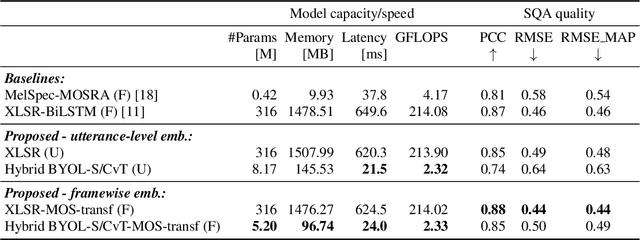
Automatic speech quality assessment is essential for audio researchers, developers, speech and language pathologists, and system quality engineers. The current state-of-the-art systems are based on framewise speech features (hand-engineered or learnable) combined with time dependency modeling. This paper proposes an efficient system with results comparable to the best performing model in the ConferencingSpeech 2022 challenge. Our proposed system is characterized by a smaller number of parameters (40-60x), fewer FLOPS (100x), lower memory consumption (10-15x), and lower latency (30x). Speech quality practitioners can therefore iterate much faster, deploy the system on resource-limited hardware, and, overall, the proposed system contributes to sustainable machine learning. The paper also concludes that framewise embeddings outperform utterance-level embeddings and that multi-task training with acoustic conditions modeling does not degrade speech quality prediction while providing better interpretation.