 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Talker Identity Aids With Improving Speech Recognition in Adversarial Environments
Oct 07, 2024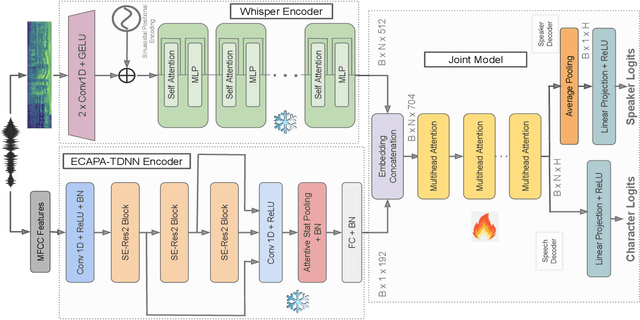
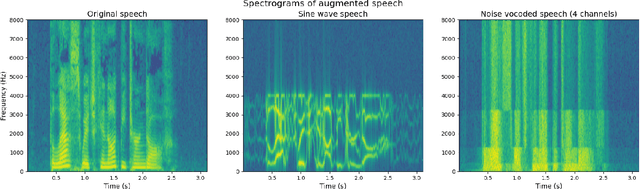
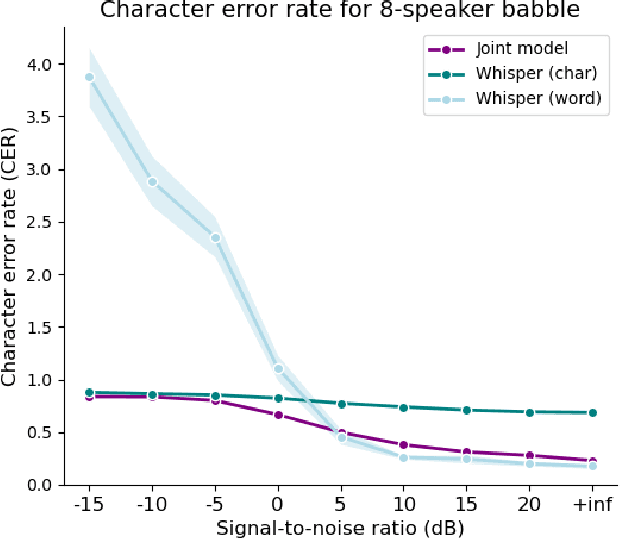
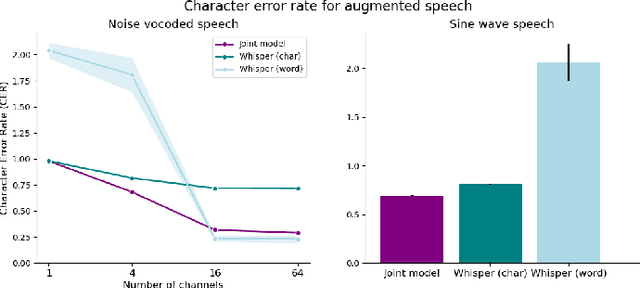
Current state-of-the-art speech recognition models are trained to map acoustic signals into sub-lexical units. While these models demonstrate superior performance, they remain vulnerable to out-of-distribution conditions such as background noise and speech augmentations. In this work, we hypothesize that incorporating speaker representations during speech recognition can enhance model robustness to noise. We developed a transformer-based model that jointly performs speech recognition and speaker identification. Our model utilizes speech embeddings from Whisper and speaker embeddings from ECAPA-TDNN, which are processed jointly to perform both tasks. We show that the joint model performs comparably to Whisper under clean conditions. Notably, the joint model outperforms Whisper in high-noise environments, such as with 8-speaker babble background noise. Furthermore, our joint model excels in handling highly augmented speech, including sine-wave and noise-vocoded speech. Overall, these results suggest that integrating voice representations with speech recognition can lead to more robust models under adversarial conditions.
Explaining Deep Learning Embeddings for Speech Emotion Recognition by Predicting Interpretable Acoustic Features
Sep 14, 2024Pre-trained deep learning embeddings have consistently shown superior performance over handcrafted acoustic features in speech emotion recognition (SER). However, unlike acoustic features with clear physical meaning, these embeddings lack clear interpretability. Explaining these embeddings is crucial for building trust in healthcare and security applications and advancing the scientific understanding of the acoustic information that is encoded in them. This paper proposes a modified probing approach to explain deep learning embeddings in the SER space. We predict interpretable acoustic features (e.g., f0, loudness) from (i) the complete set of embeddings and (ii) a subset of the embedding dimensions identified as most important for predicting each emotion. If the subset of the most important dimensions better predicts a given emotion than all dimensions and also predicts specific acoustic features more accurately, we infer those acoustic features are important for the embedding model for the given task. We conducted experiments using the WavLM embeddings and eGeMAPS acoustic features as audio representations, applying our method to the RAVDESS and SAVEE emotional speech datasets. Based on this evaluation, we demonstrate that Energy, Frequency, Spectral, and Temporal categories of acoustic features provide diminishing information to SER in that order, demonstrating the utility of the probing classifier method to relate embeddings to interpretable acoustic features.
Evaluating Speaker Identity Coding in Self-supervised Models and Humans
Jun 14, 2024Speaker identity plays a significant role in human communication and is being increasingly used in societal applications, many through advances in machine learning. Speaker identity perception is an essential cognitive phenomenon that can be broadly reduced to two main tasks: recognizing a voice or discriminating between voices. Several studies have attempted to identify acoustic correlates of identity perception to pinpoint salient parameters for such a task. Unlike other communicative social signals, most efforts have yielded inefficacious conclusions. Furthermore, current neurocognitive models of voice identity processing consider the bases of perception as acoustic dimensions such as fundamental frequency, harmonics-to-noise ratio, and formant dispersion. However, these findings do not account for naturalistic speech and within-speaker variability. Representational spaces of current self-supervised models have shown significant performance in various speech-related tasks. In this work, we demonstrate that self-supervised representations from different families (e.g., generative, contrastive, and predictive models) are significantly better for speaker identification over acoustic representations. We also show that such a speaker identification task can be used to better understand the nature of acoustic information representation in different layers of these powerful networks. By evaluating speaker identification accuracy across acoustic, phonemic, prosodic, and linguistic variants, we report similarity between model performance and human identity perception. We further examine these similarities by juxtaposing the encoding spaces of models and humans and challenging the use of distance metrics as a proxy for speaker proximity. Lastly, we show that some models can predict brain responses in Auditory and Language regions during naturalistic stimuli.
Predicting Heart Activity from Speech using Data-driven and Knowledge-based features
Jun 10, 2024Accurately predicting heart activity and other biological signals is crucial for diagnosis and monitoring. Given that speech is an outcome of multiple physiological systems, a significant body of work studied the acoustic correlates of heart activity. Recently, self-supervised models have excelled in speech-related tasks compared to traditional acoustic methods. However, the robustness of data-driven representations in predicting heart activity remained unexplored. In this study, we demonstrate that self-supervised speech models outperform acoustic features in predicting heart activity parameters. We also emphasize the impact of individual variability on model generalizability. These findings underscore the value of data-driven representations in such tasks and the need for more speech-based physiological data to mitigate speaker-related challenges.
Efficient Speech Quality Assessment using Self-supervised Framewise Embeddings
Nov 12, 2022
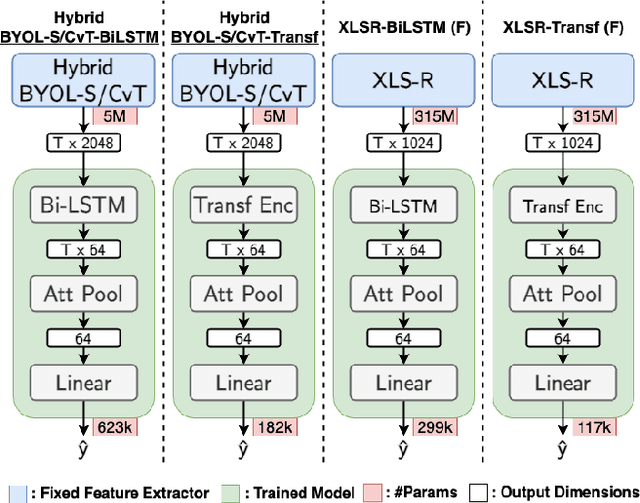
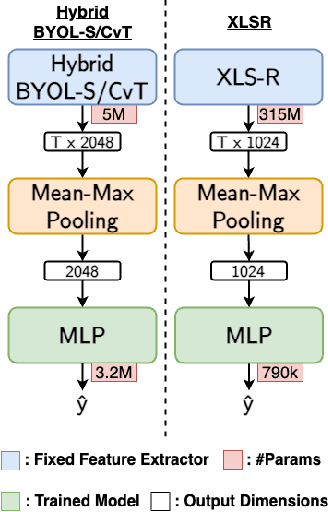
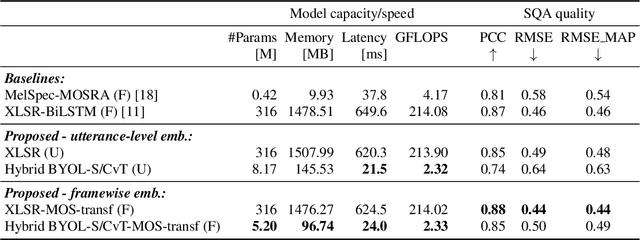
Automatic speech quality assessment is essential for audio researchers, developers, speech and language pathologists, and system quality engineers. The current state-of-the-art systems are based on framewise speech features (hand-engineered or learnable) combined with time dependency modeling. This paper proposes an efficient system with results comparable to the best performing model in the ConferencingSpeech 2022 challenge. Our proposed system is characterized by a smaller number of parameters (40-60x), fewer FLOPS (100x), lower memory consumption (10-15x), and lower latency (30x). Speech quality practitioners can therefore iterate much faster, deploy the system on resource-limited hardware, and, overall, the proposed system contributes to sustainable machine learning. The paper also concludes that framewise embeddings outperform utterance-level embeddings and that multi-task training with acoustic conditions modeling does not degrade speech quality prediction while providing better interpretation.
BYOL-S: Learning Self-supervised Speech Representations by Bootstrapping
Jun 30, 2022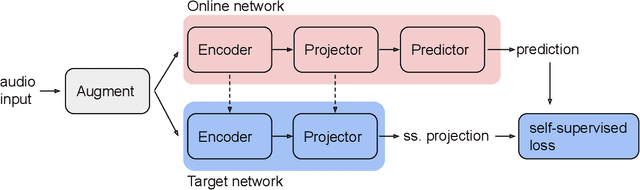



Methods for extracting audio and speech features have been studied since pioneering work on spectrum analysis decades ago. Recent efforts are guided by the ambition to develop general-purpose audio representations. For example, deep neural networks can extract optimal embeddings if they are trained on large audio datasets. This work extends existing methods based on self-supervised learning by bootstrapping, proposes various encoder architectures, and explores the effects of using different pre-training datasets. Lastly, we present a novel training framework to come up with a hybrid audio representation, which combines handcrafted and data-driven learned audio features. All the proposed representations were evaluated within the HEAR NeurIPS 2021 challenge for auditory scene classification and timestamp detection tasks. Our results indicate that the hybrid model with a convolutional transformer as the encoder yields superior performance in most HEAR challenge tasks.
Hybrid Handcrafted and Learnable Audio Representation for Analysis of Speech Under Cognitive and Physical Load
Mar 30, 2022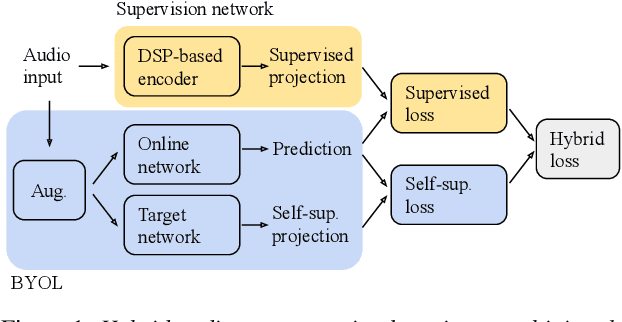

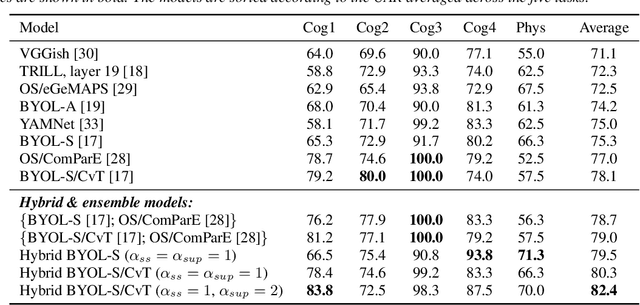
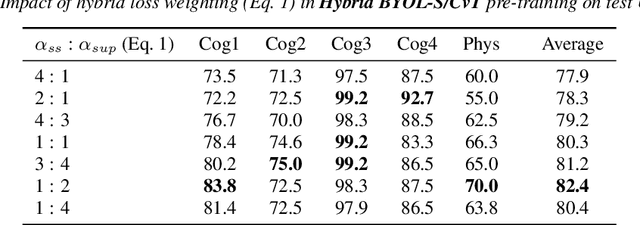
As a neurophysiological response to threat or adverse conditions, stress can affect cognition, emotion and behaviour with potentially detrimental effects on health in the case of sustained exposure. Since the affective content of speech is inherently modulated by an individual's physical and mental state, a substantial body of research has been devoted to the study of paralinguistic correlates of stress-inducing task load. Historically, voice stress analysis (VSA) has been conducted using conventional digital signal processing (DSP) techniques. Despite the development of modern methods based on deep neural networks (DNNs), accurately detecting stress in speech remains difficult due to the wide variety of stressors and considerable variability in the individual stress perception. To that end, we introduce a set of five datasets for task load detection in speech. The voice recordings were collected as either cognitive or physical stress was induced in the cohort of volunteers, with a cumulative number of more than a hundred speakers. We used the datasets to design and evaluate a novel self-supervised audio representation that leverages the effectiveness of handcrafted features (DSP-based) and the complexity of data-driven DNN representations. Notably, the proposed approach outperformed both extensive handcrafted feature sets and novel DNN-based audio representation learning approaches.