 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Rhythm and Voice Conversion of Dysarthric to Healthy Speech for ASR
Jan 17, 2025Automatic speech recognition (ASR) systems are well known to perform poorly on dysarthric speech. Previous works have addressed this by speaking rate modification to reduce the mismatch with typical speech. Unfortunately, these approaches rely on transcribed speech data to estimate speaking rates and phoneme durations, which might not be available for unseen speakers. Therefore, we combine unsupervised rhythm and voice conversion methods based on self-supervised speech representations to map dysarthric to typical speech. We evaluate the outputs with a large ASR model pre-trained on healthy speech without further fine-tuning and find that the proposed rhythm conversion especially improves performance for speakers of the Torgo corpus with more severe cases of dysarthria. Code and audio samples are available at https://idiap.github.io/RnV .
SSL-TTS: Leveraging Self-Supervised Embeddings and kNN Retrieval for Zero-Shot Multi-speaker TTS
Aug 20, 2024While recent zero-shot multispeaker text-to-speech (TTS) models achieve impressive results, they typically rely on extensive transcribed speech datasets from numerous speakers and intricate training pipelines. Meanwhile, self-supervised learning (SSL) speech features have emerged as effective intermediate representations for TTS. It was also observed that SSL features from different speakers that are linearly close share phonetic information while maintaining individual speaker identity, which enables straight-forward and robust voice cloning. In this study, we introduce SSL-TTS, a lightweight and efficient zero-shot TTS framework trained on transcribed speech from a single speaker. SSL-TTS leverages SSL features and retrieval methods for simple and robust zero-shot multi-speaker synthesis. Objective and subjective evaluations show that our approach achieves performance comparable to state-of-the-art models that require significantly larger training datasets. The low training data requirements mean that SSL-TTS is well suited for the development of multi-speaker TTS systems for low-resource domains and languages. We also introduce an interpolation parameter which enables fine control over the output speech by blending voices. Demo samples are available at https://idiap.github.io/ssl-tts
Speaker Embeddings as Individuality Proxy for Voice Stress Detection
Jun 09, 2023



Since the mental states of the speaker modulate speech, stress introduced by cognitive or physical loads could be detected in the voice. The existing voice stress detection benchmark has shown that the audio embeddings extracted from the Hybrid BYOL-S self-supervised model perform well. However, the benchmark only evaluates performance separately on each dataset, but does not evaluate performance across the different types of stress and different languages. Moreover, previous studies found strong individual differences in stress susceptibility. This paper presents the design and development of voice stress detection, trained on more than 100 speakers from 9 language groups and five different types of stress. We address individual variabilities in voice stress analysis by adding speaker embeddings to the hybrid BYOL-S features. The proposed method significantly improves voice stress detection performance with an input audio length of only 3-5 seconds.
Efficient Speech Quality Assessment using Self-supervised Framewise Embeddings
Nov 12, 2022
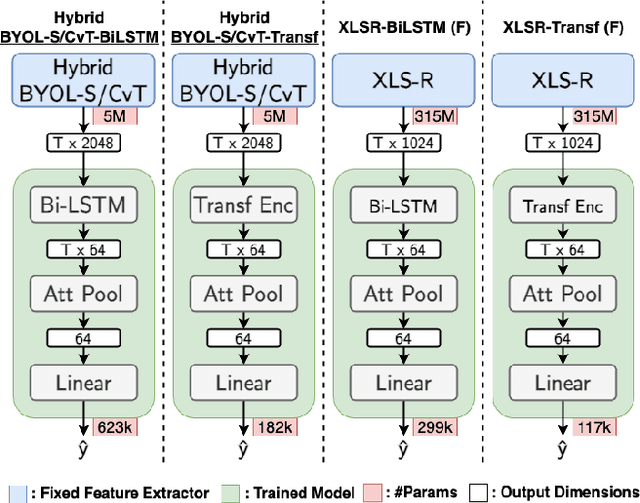
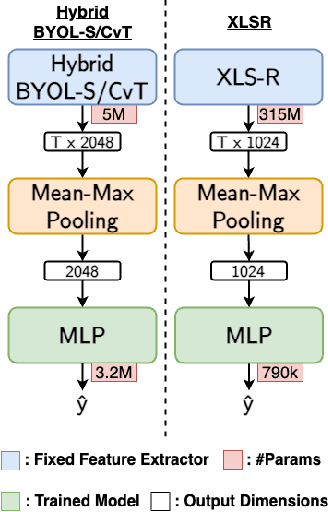
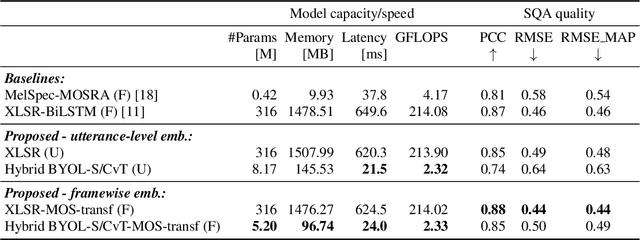
Automatic speech quality assessment is essential for audio researchers, developers, speech and language pathologists, and system quality engineers. The current state-of-the-art systems are based on framewise speech features (hand-engineered or learnable) combined with time dependency modeling. This paper proposes an efficient system with results comparable to the best performing model in the ConferencingSpeech 2022 challenge. Our proposed system is characterized by a smaller number of parameters (40-60x), fewer FLOPS (100x), lower memory consumption (10-15x), and lower latency (30x). Speech quality practitioners can therefore iterate much faster, deploy the system on resource-limited hardware, and, overall, the proposed system contributes to sustainable machine learning. The paper also concludes that framewise embeddings outperform utterance-level embeddings and that multi-task training with acoustic conditions modeling does not degrade speech quality prediction while providing better interpretation.
BYOL-S: Learning Self-supervised Speech Representations by Bootstrapping
Jun 30, 2022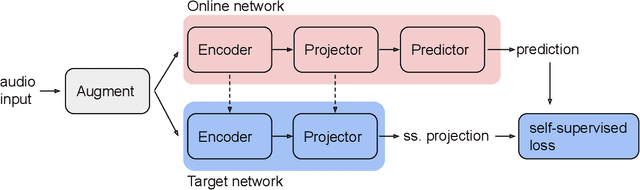



Methods for extracting audio and speech features have been studied since pioneering work on spectrum analysis decades ago. Recent efforts are guided by the ambition to develop general-purpose audio representations. For example, deep neural networks can extract optimal embeddings if they are trained on large audio datasets. This work extends existing methods based on self-supervised learning by bootstrapping, proposes various encoder architectures, and explores the effects of using different pre-training datasets. Lastly, we present a novel training framework to come up with a hybrid audio representation, which combines handcrafted and data-driven learned audio features. All the proposed representations were evaluated within the HEAR NeurIPS 2021 challenge for auditory scene classification and timestamp detection tasks. Our results indicate that the hybrid model with a convolutional transformer as the encoder yields superior performance in most HEAR challenge tasks.
MOSRA: Joint Mean Opinion Score and Room Acoustics Speech Quality Assessment
Apr 04, 2022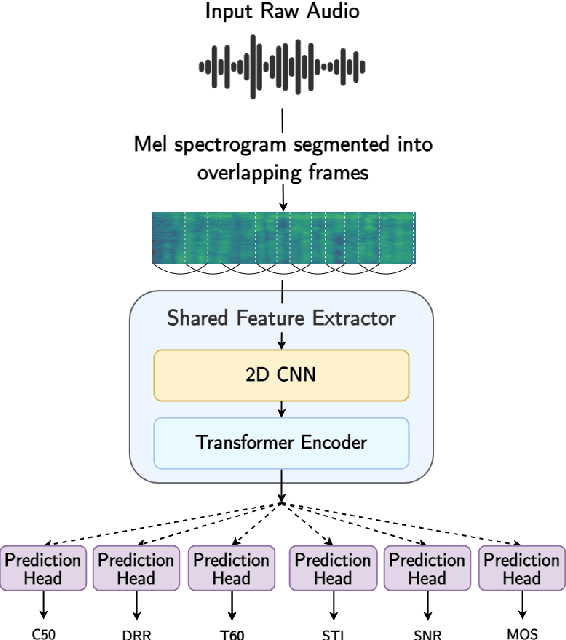
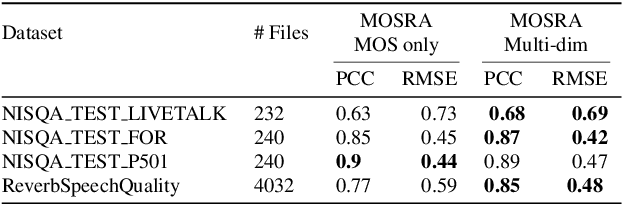
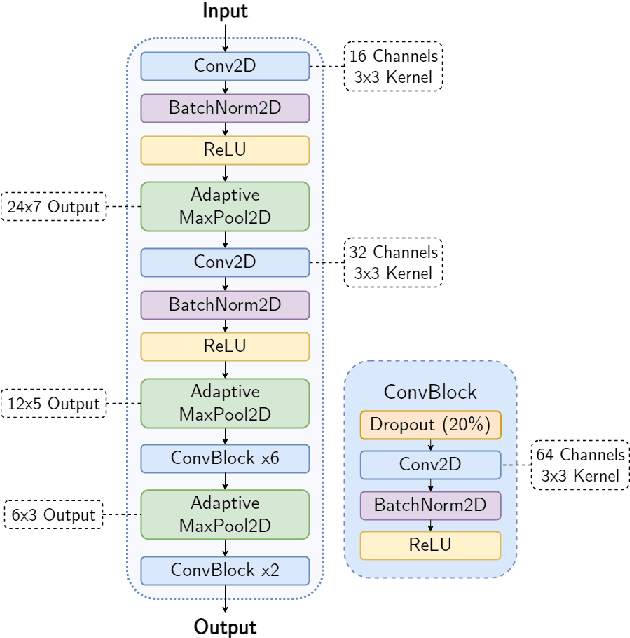
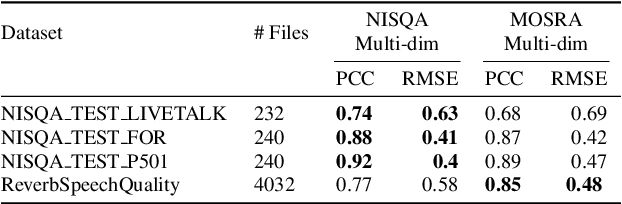
The acoustic environment can degrade speech quality during communication (e.g., video call, remote presentation, outside voice recording), and its impact is often unknown. Objective metrics for speech quality have proven challenging to develop given the multi-dimensionality of factors that affect speech quality and the difficulty of collecting labeled data. Hypothesizing the impact of acoustics on speech quality, this paper presents MOSRA: a non-intrusive multi-dimensional speech quality metric that can predict room acoustics parameters (SNR, STI, T60, DRR, and C50) alongside the overall mean opinion score (MOS) for speech quality. By explicitly optimizing the model to learn these room acoustics parameters, we can extract more informative features and improve the generalization for the MOS task when the training data is limited. Furthermore, we also show that this joint training method enhances the blind estimation of room acoustics, improving the performance of current state-of-the-art models. An additional side-effect of this joint prediction is the improvement in the explainability of the predictions, which is a valuable feature for many applications.
Neural Arabic Question Answering
Jun 12, 2019
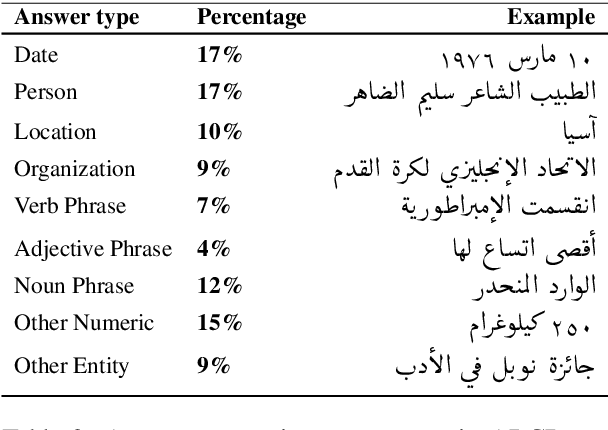
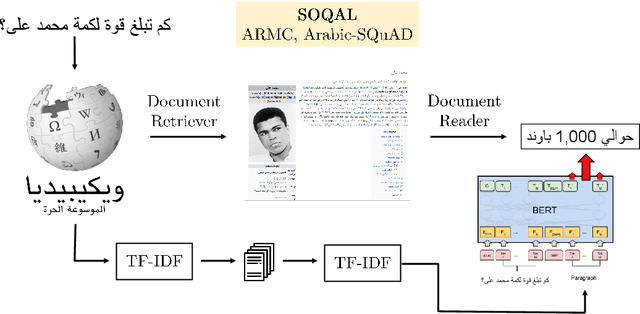
This paper tackles the problem of open domain factual Arabic question answering (QA) using Wikipedia as our knowledge source. This constrains the answer of any question to be a span of text in Wikipedia. Open domain QA for Arabic entails three challenges: annotated QA datasets in Arabic, large scale efficient information retrieval and machine reading comprehension. To deal with the lack of Arabic QA datasets we present the Arabic Reading Comprehension Dataset (ARCD) composed of 1,395 questions posed by crowdworkers on Wikipedia articles, and a machine translation of the Stanford Question Answering Dataset (Arabic-SQuAD). Our system for open domain question answering in Arabic (SOQAL) is based on two components: (1) a document retriever using a hierarchical TF-IDF approach and (2) a neural reading comprehension model using the pre-trained bi-directional transformer BERT. Our experiments on ARCD indicate the effectiveness of our approach with our BERT-based reader achieving a 61.3 F1 score, and our open domain system SOQAL achieving a 27.6 F1 score.