 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamMark: A Deep Learning-Based Semi-Fragile Audio Watermarking for Proactive Deepfake Detection
Apr 13, 2026The rapid advancement of generative AI has made it increasingly challenging to distinguish between deepfake audio and authentic human speech. To overcome the limitations of passive detection methods, we propose StreamMark, a novel deep learning-based, semi-fragile audio watermarking system. StreamMark is designed to be robust against benign audio conversions that preserve semantic meaning (e.g., compression, noise) while remaining fragile to malicious, semantics-altering manipulations (e.g., voice conversion, speech editing). Our method introduces a complex-domain embedding technique within a unique Encoder-Distortion-Decoder architecture, trained explicitly to differentiate between these two classes of transformations. Comprehensive benchmarks demonstrate that StreamMark achieves high imperceptibility (SNR 24.16 dB, PESQ 4.20), is resilient to real-world distortions like Opus encoding, and exhibits principled fragility against a suite of deepfake attacks, with message recovery accuracy dropping to chance levels (~50%), while remaining robust to benign AI-based style transfers (ACC >98%).
Calibration-Reasoning Framework for Descriptive Speech Quality Assessment
Mar 10, 2026Explainable speech quality assessment requires moving beyond Mean Opinion Scores (MOS) to analyze underlying perceptual dimensions. To address this, we introduce a novel post-training method that tailors the foundational Audio Large Language Model for multidimensional reasoning, detection and classification of audio artifacts. First, a calibration stage aligns the model to predict predefined perceptual dimensions. Second, a reinforcement learning stage leverages Group Relative Policy Optimization (GRPO) with dimension-specific rewards to heavily enhance accuracy of descriptions and temporal localization of quality issues. With this approach we reach state-of-the-art results of 0.71 mean PCC score on the multidimensional QualiSpeech benchmark and 13% improvement in MOS prediction driven by RL-based reasoning. Furthermore, our fine-grained GRPO rewards substantially advance the model's ability to pinpoint and classify audio artifacts in time.
Differentiable Time-Varying IIR Filtering for Real-Time Speech Denoising
Mar 03, 2026We present TVF (Time-Varying Filtering), a low-latency speech enhancement model with 1 million parameters. Combining the interpretability of Digital Signal Processing (DSP) with the adaptability of deep learning, TVF bridges the gap between traditional filtering and modern neural speech modeling. The model utilizes a lightweight neural network backbone to predict the coefficients of a differentiable 35-band IIR filter cascade in real time, allowing it to adapt dynamically to non-stationary noise. Unlike ``black-box'' deep learning approaches, TVF offers a completely interpretable processing chain, where spectral modifications are explicit and adjustable. We demonstrate the efficacy of this approach on a speech denoising task using the Valentini-Botinhao dataset and compare the results to a static DDSP approach and a fully deep-learning-based solution, showing that TVF achieves effective adaptation to changing noise conditions.
DeepFilterGAN: A Full-band Real-time Speech Enhancement System with GAN-based Stochastic Regeneration
May 29, 2025In this work, we propose a full-band real-time speech enhancement system with GAN-based stochastic regeneration. Predictive models focus on estimating the mean of the target distribution, whereas generative models aim to learn the full distribution. This behavior of predictive models may lead to over-suppression, i.e. the removal of speech content. In the literature, it was shown that combining a predictive model with a generative one within the stochastic regeneration framework can reduce the distortion in the output. We use this framework to obtain a real-time speech enhancement system. With 3.58M parameters and a low latency, our system is designed for real-time streaming with a lightweight architecture. Experiments show that our system improves over the first stage in terms of NISQA-MOS metric. Finally, through an ablation study, we show the importance of noisy conditioning in our system. We participated in 2025 Urgent Challenge with our model and later made further improvements.
Model as Loss: A Self-Consistent Training Paradigm
May 27, 2025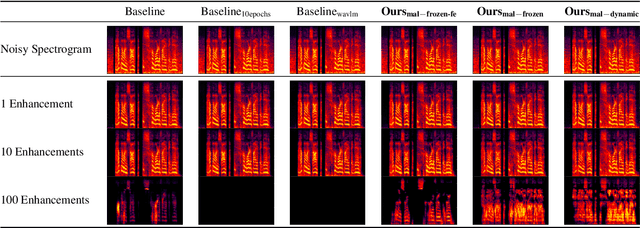
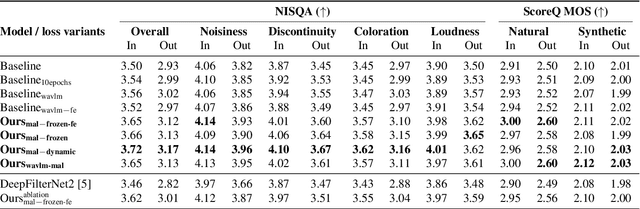
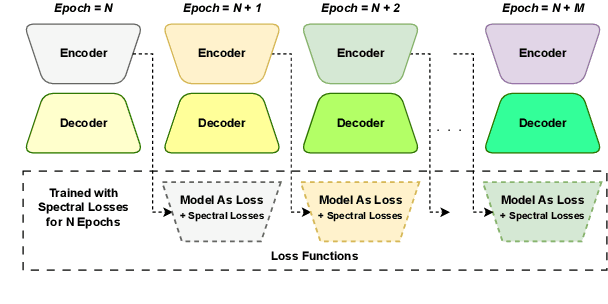
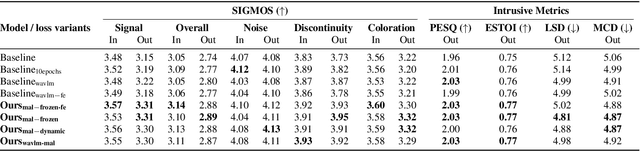
Conventional methods for speech enhancement rely on handcrafted loss functions (e.g., time or frequency domain losses) or deep feature losses (e.g., using WavLM or wav2vec), which often fail to capture subtle signal properties essential for optimal performance. To address this, we propose Model as Loss, a novel training paradigm that utilizes the encoder from the same model as a loss function to guide the training. The Model as Loss paradigm leverages the encoder's task-specific feature space, optimizing the decoder to produce output consistent with perceptual and task-relevant characteristics of the clean signal. By using the encoder's learned features as a loss function, this framework enforces self-consistency between the clean reference speech and the enhanced model output. Our approach outperforms pre-trained deep feature losses on standard speech enhancement benchmarks, offering better perceptual quality and robust generalization to both in-domain and out-of-domain datasets.
Semi-intrusive audio evaluation: Casting non-intrusive assessment as a multi-modal text prediction task
Sep 21, 2024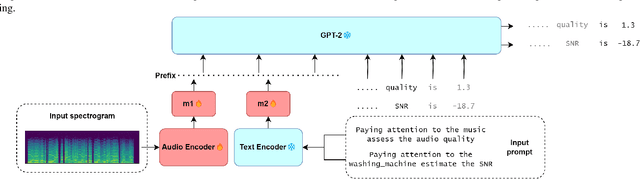


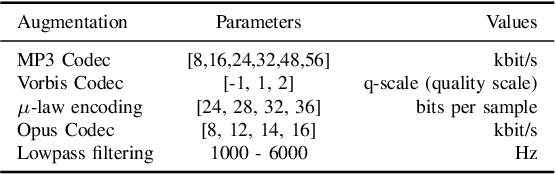
Assessment of audio by humans possesses the unique ability to attend to specific sources in a mixture of signals. Mimicking this human ability, we propose a semi-intrusive assessment where we frame the audio assessment task as a text prediction task with audio-text input. To this end we leverage instruction fine-tuning of the multi-modal PENGI model. Our experiments on MOS prediction for speech and music using both real and simulated data show that the proposed method, on average, outperforms baselines that operate on a single task. To justify the model generability, we propose a new semi-intrusive SNR estimator that is able to estimate the SNR of arbitrary signal classes in a mixture of signals with different classes.
OpenACE: An Open Benchmark for Evaluating Audio Coding Performance
Sep 12, 2024



Audio and speech coding lack unified evaluation and open-source testing. Many candidate systems were evaluated on proprietary, non-reproducible, or small data, and machine learning-based codecs are often tested on datasets with similar distributions as trained on, which is unfairly compared to digital signal processing-based codecs that usually work well with unseen data. This paper presents a full-band audio and speech coding quality benchmark with more variable content types, including traditional open test vectors. An example use case of audio coding quality assessment is presented with open-source Opus, 3GPP's EVS, and recent ETSI's LC3 with LC3+ used in Bluetooth LE Audio profiles. Besides, quality variations of emotional speech encoding at 16 kbps are shown. The proposed open-source benchmark contributes to audio and speech coding democratization and is available at https://github.com/JozefColdenhoff/OpenACE.
Diffusion-based Speech Enhancement with Schrödinger Bridge and Symmetric Noise Schedule
Sep 08, 2024Recently, diffusion-based generative models have demonstrated remarkable performance in speech enhancement tasks. However, these methods still encounter challenges, including the lack of structural information and poor performance in low Signal-to-Noise Ratio (SNR) scenarios. To overcome these challenges, we propose the Schr\"oodinger Bridge-based Speech Enhancement (SBSE) method, which learns the diffusion processes directly between the noisy input and the clean distribution, unlike conventional diffusion-based speech enhancement systems that learn data to Gaussian distributions. To enhance performance in extremely noisy conditions, we introduce a two-stage system incorporating ratio mask information into the diffusion-based generative model. Our experimental results show that our proposed SBSE method outperforms all the baseline models and achieves state-of-the-art performance, especially in low SNR conditions. Importantly, only a few inference steps are required to achieve the best result.
On real-time multi-stage speech enhancement systems
Dec 19, 2023Recently, multi-stage systems have stood out among deep learning-based speech enhancement methods. However, these systems are always high in complexity, requiring millions of parameters and powerful computational resources, which limits their application for real-time processing in low-power devices. Besides, the contribution of various influencing factors to the success of multi-stage systems remains unclear, which presents challenges to reduce the size of these systems. In this paper, we extensively investigate a lightweight two-stage network with only 560k total parameters. It consists of a Mel-scale magnitude masking model in the first stage and a complex spectrum mapping model in the second stage. We first provide a consolidated view of the roles of gain power factor, post-filter, and training labels for the Mel-scale masking model. Then, we explore several training schemes for the two-stage network and provide some insights into the superiority of the two-stage network. We show that the proposed two-stage network trained by an optimal scheme achieves a performance similar to a four times larger open source model DeepFilterNet2.
Cluster-based pruning techniques for audio data
Sep 21, 2023Deep learning models have become widely adopted in various domains, but their performance heavily relies on a vast amount of data. Datasets often contain a large number of irrelevant or redundant samples, which can lead to computational inefficiencies during the training. In this work, we introduce, for the first time in the context of the audio domain, the k-means clustering as a method for efficient data pruning. K-means clustering provides a way to group similar samples together, allowing the reduction of the size of the dataset while preserving its representative characteristics. As an example, we perform clustering analysis on the keyword spotting (KWS) dataset. We discuss how k-means clustering can significantly reduce the size of audio datasets while maintaining the classification performance across neural networks (NNs) with different architectures. We further comment on the role of scaling analysis in identifying the optimal pruning strategies for a large number of samples. Our studies serve as a proof-of-principle, demonstrating the potential of data selection with distance-based clustering algorithms for the audio domain and highlighting promising research avenues.