Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-intrusive audio evaluation: Casting non-intrusive assessment as a multi-modal text prediction task
Paper and Code
Sep 21, 2024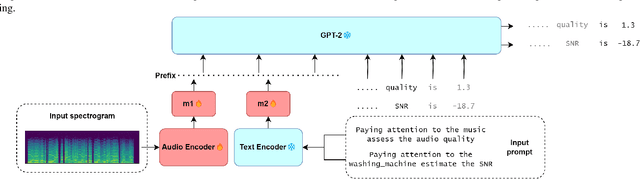


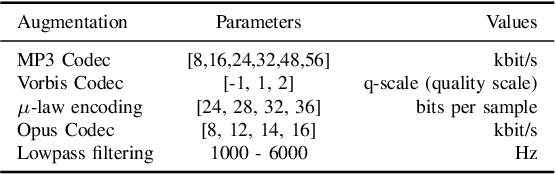
Assessment of audio by humans possesses the unique ability to attend to specific sources in a mixture of signals. Mimicking this human ability, we propose a semi-intrusive assessment where we frame the audio assessment task as a text prediction task with audio-text input. To this end we leverage instruction fine-tuning of the multi-modal PENGI model. Our experiments on MOS prediction for speech and music using both real and simulated data show that the proposed method, on average, outperforms baselines that operate on a single task. To justify the model generability, we propose a new semi-intrusive SNR estimator that is able to estimate the SNR of arbitrary signal classes in a mixture of signals with different classes.
View paper on