 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-intrusive audio evaluation: Casting non-intrusive assessment as a multi-modal text prediction task
Sep 21, 2024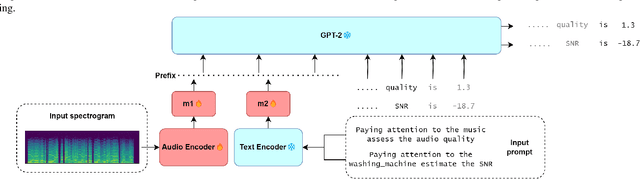


Assessment of audio by humans possesses the unique ability to attend to specific sources in a mixture of signals. Mimicking this human ability, we propose a semi-intrusive assessment where we frame the audio assessment task as a text prediction task with audio-text input. To this end we leverage instruction fine-tuning of the multi-modal PENGI model. Our experiments on MOS prediction for speech and music using both real and simulated data show that the proposed method, on average, outperforms baselines that operate on a single task. To justify the model generability, we propose a new semi-intrusive SNR estimator that is able to estimate the SNR of arbitrary signal classes in a mixture of signals with different classes.
OpenACE: An Open Benchmark for Evaluating Audio Coding Performance
Sep 12, 2024



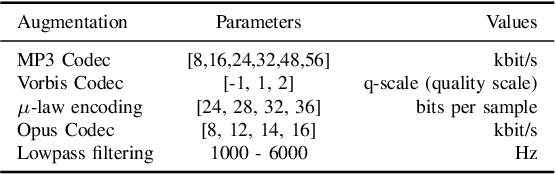
Audio and speech coding lack unified evaluation and open-source testing. Many candidate systems were evaluated on proprietary, non-reproducible, or small data, and machine learning-based codecs are often tested on datasets with similar distributions as trained on, which is unfairly compared to digital signal processing-based codecs that usually work well with unseen data. This paper presents a full-band audio and speech coding quality benchmark with more variable content types, including traditional open test vectors. An example use case of audio coding quality assessment is presented with open-source Opus, 3GPP's EVS, and recent ETSI's LC3 with LC3+ used in Bluetooth LE Audio profiles. Besides, quality variations of emotional speech encoding at 16 kbps are shown. The proposed open-source benchmark contributes to audio and speech coding democratization and is available at https://github.com/JozefColdenhoff/OpenACE.
On real-time multi-stage speech enhancement systems
Dec 19, 2023Recently, multi-stage systems have stood out among deep learning-based speech enhancement methods. However, these systems are always high in complexity, requiring millions of parameters and powerful computational resources, which limits their application for real-time processing in low-power devices. Besides, the contribution of various influencing factors to the success of multi-stage systems remains unclear, which presents challenges to reduce the size of these systems. In this paper, we extensively investigate a lightweight two-stage network with only 560k total parameters. It consists of a Mel-scale magnitude masking model in the first stage and a complex spectrum mapping model in the second stage. We first provide a consolidated view of the roles of gain power factor, post-filter, and training labels for the Mel-scale masking model. Then, we explore several training schemes for the two-stage network and provide some insights into the superiority of the two-stage network. We show that the proposed two-stage network trained by an optimal scheme achieves a performance similar to a four times larger open source model DeepFilterNet2.
Multi-Channel MOSRA: Mean Opinion Score and Room Acoustics Estimation Using Simulated Data and a Teacher Model
Sep 21, 2023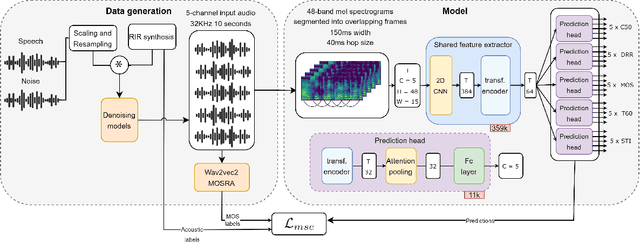

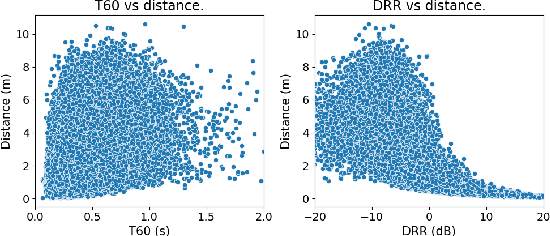

Previous methods for predicting room acoustic parameters and speech quality metrics have focused on the single-channel case, where room acoustics and Mean Opinion Score (MOS) are predicted for a single recording device. However, quality-based device selection for rooms with multiple recording devices may benefit from a multi-channel approach where the descriptive metrics are predicted for multiple devices in parallel. Following our hypothesis that a model may benefit from multi-channel training, we develop a multi-channel model for joint MOS and room acoustics prediction (MOSRA) for five channels in parallel. The lack of multi-channel audio data with ground truth labels necessitated the creation of simulated data using an acoustic simulator with room acoustic labels extracted from the generated impulse responses and labels for MOS generated in a student-teacher setup using a wav2vec2-based MOS prediction model. Our experiments show that the multi-channel model improves the prediction of the direct-to-reverberation ratio, clarity, and speech transmission index over the single-channel model with roughly 5$\times$ less computation while suffering minimal losses in the performance of the other metrics.