 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFilterGAN: A Full-band Real-time Speech Enhancement System with GAN-based Stochastic Regeneration
May 29, 2025In this work, we propose a full-band real-time speech enhancement system with GAN-based stochastic regeneration. Predictive models focus on estimating the mean of the target distribution, whereas generative models aim to learn the full distribution. This behavior of predictive models may lead to over-suppression, i.e. the removal of speech content. In the literature, it was shown that combining a predictive model with a generative one within the stochastic regeneration framework can reduce the distortion in the output. We use this framework to obtain a real-time speech enhancement system. With 3.58M parameters and a low latency, our system is designed for real-time streaming with a lightweight architecture. Experiments show that our system improves over the first stage in terms of NISQA-MOS metric. Finally, through an ablation study, we show the importance of noisy conditioning in our system. We participated in 2025 Urgent Challenge with our model and later made further improvements.
On real-time multi-stage speech enhancement systems
Dec 19, 2023Recently, multi-stage systems have stood out among deep learning-based speech enhancement methods. However, these systems are always high in complexity, requiring millions of parameters and powerful computational resources, which limits their application for real-time processing in low-power devices. Besides, the contribution of various influencing factors to the success of multi-stage systems remains unclear, which presents challenges to reduce the size of these systems. In this paper, we extensively investigate a lightweight two-stage network with only 560k total parameters. It consists of a Mel-scale magnitude masking model in the first stage and a complex spectrum mapping model in the second stage. We first provide a consolidated view of the roles of gain power factor, post-filter, and training labels for the Mel-scale masking model. Then, we explore several training schemes for the two-stage network and provide some insights into the superiority of the two-stage network. We show that the proposed two-stage network trained by an optimal scheme achieves a performance similar to a four times larger open source model DeepFilterNet2.
Multi-Channel MOSRA: Mean Opinion Score and Room Acoustics Estimation Using Simulated Data and a Teacher Model
Sep 21, 2023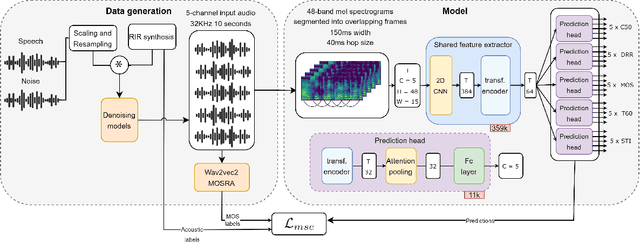

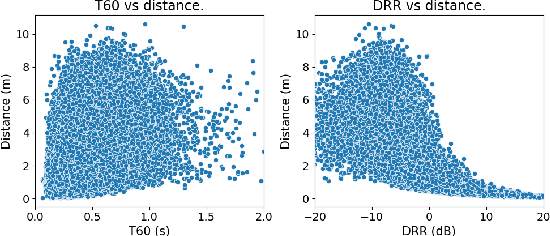

Previous methods for predicting room acoustic parameters and speech quality metrics have focused on the single-channel case, where room acoustics and Mean Opinion Score (MOS) are predicted for a single recording device. However, quality-based device selection for rooms with multiple recording devices may benefit from a multi-channel approach where the descriptive metrics are predicted for multiple devices in parallel. Following our hypothesis that a model may benefit from multi-channel training, we develop a multi-channel model for joint MOS and room acoustics prediction (MOSRA) for five channels in parallel. The lack of multi-channel audio data with ground truth labels necessitated the creation of simulated data using an acoustic simulator with room acoustic labels extracted from the generated impulse responses and labels for MOS generated in a student-teacher setup using a wav2vec2-based MOS prediction model. Our experiments show that the multi-channel model improves the prediction of the direct-to-reverberation ratio, clarity, and speech transmission index over the single-channel model with roughly 5$\times$ less computation while suffering minimal losses in the performance of the other metrics.