 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-based pruning techniques for audio data
Sep 21, 2023Deep learning models have become widely adopted in various domains, but their performance heavily relies on a vast amount of data. Datasets often contain a large number of irrelevant or redundant samples, which can lead to computational inefficiencies during the training. In this work, we introduce, for the first time in the context of the audio domain, the k-means clustering as a method for efficient data pruning. K-means clustering provides a way to group similar samples together, allowing the reduction of the size of the dataset while preserving its representative characteristics. As an example, we perform clustering analysis on the keyword spotting (KWS) dataset. We discuss how k-means clustering can significantly reduce the size of audio datasets while maintaining the classification performance across neural networks (NNs) with different architectures. We further comment on the role of scaling analysis in identifying the optimal pruning strategies for a large number of samples. Our studies serve as a proof-of-principle, demonstrating the potential of data selection with distance-based clustering algorithms for the audio domain and highlighting promising research avenues.
Power efficient analog features for audio recognition
Oct 07, 2021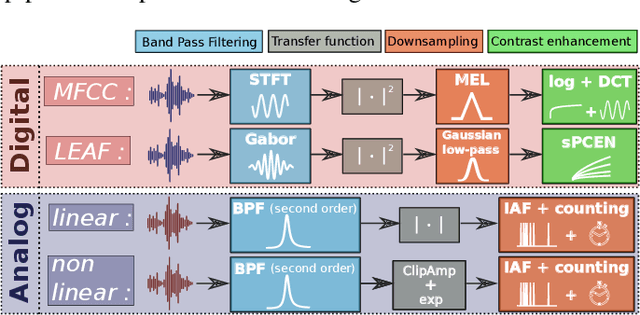
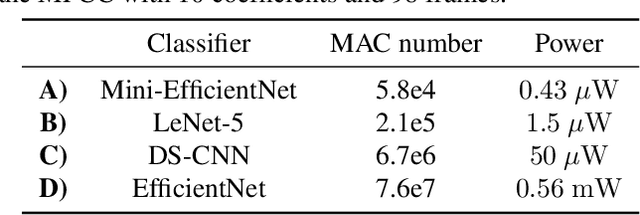

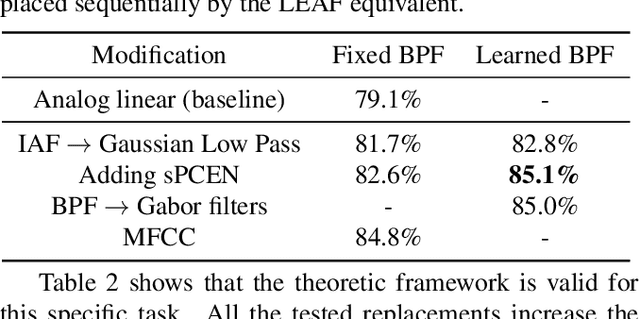
The digital signal processing-based representations like the Mel-Frequency Cepstral Coefficient are well known to be a solid basis for various audio processing tasks. Alternatively, analog feature representations, relying on analog-electronics-feasible bandpass filtering, allow much lower system power consumption compared with the digital counterpart, while parity performance on traditional tasks like voice activity detection can be achieved. This work explores the possibility of using analog features on multiple speech processing tasks that vary in time dependencies: wake word detection, keyword spotting, and speaker identification. The results of this evaluation show that the analog features are still more power-efficient and competitive on simpler tasks than digital features but yield an increasing performance drop on more complex tasks when long-time correlations are present. We also introduce a novel theoretical framework based on information theory to understand this performance drop by quantifying information flow in feature calculation which helps identify the performance bottlenecks. The theoretical claims are experimentally validated, leading to a maximum of 6% increase of keyword spotting accuracy, even surpassing the digital baseline features. The proposed analog-feature-based systems could pave the way to achieving best-in-class accuracy and power consumption simultaneously.