 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriFT: Prior-Support Guided Supervised Fine-Tuning
Jun 08, 2026Supervised fine-tuning (SFT) is an efficient approach for downstream task adaptation and often serves as the initialization stage for reinforcement learning (RL), but it can show weaker generalization than RL. A key limitation is its off-policy objective: SFT fits fixed demonstrations token by token, including targets poorly aligned with the model's pretrained distribution, which can lead to overfitting. A recent line of work addresses this issue by assigning larger training weights to tokens better aligned with the current model's predictive distribution, with the intuition that fitting these tokens are less distortive to the model's pretrained knowledge and representations. However, computing the token weights from the model that is currently fine-tuned entangles token weights with the optimization trajectory, inducing a self-reinforcing dynamics as the distribution rapidly departs from the pretrained model. To address this, we propose PriFT (Prior-support guided Fine-Tuning), which derives token weights from a frozen pretrained reference to obtain a stable reweighting signal unaffected by fine-tuning. This signal estimates prior support: the extent to which each target token is supported by the pretrained distribution. Across multiple existing token-reweighting rules, replacing the reweighting signal from the online model to pretrained model consistently improves performance. We introduce two instantiations: PriFT-prob uses pretrained token probability, while PriFT-mass selects tokens by cumulative probability mass under the pretrained distribution. Extensive experiments on mathematical reasoning, code generation, and medical question answering show that PriFT achieves state-of-the-art results among SFT baselines and provides a better initialization for subsequent RL training.
OffQ: Taming Structured Outliers in LLM Quantization by Offsetting
Jun 05, 2026Low-bit quantization has been widely adopted to accelerate the inference of large language models (LLMs) by significantly reducing computational cost and memory usage. However, activation outliers pose a major challenge to effective quantization, often leading to notable performance degradation. In this paper, we introduce OffQ, a method designed to mitigate activation outliers in low-bit quantization through a novel offsetting mechanism. Specifically, OffQ first identifies a low-dimensional outlier subspace in the activations using a proposed top-1 PCA, and then concentrates high-magnitude activations into 1 channel via rotation. OffQ then absorbs this concentrated outlier channel by converting its magnitude into a shared offset, thereby reducing the standard deviation of the activations. This offsetting strategy enables effective W4A4KV4 quantization of LLMs using deployment-friendly uniform-grid and uniform-precision quantization. Extensive experiments across diverse LLM architectures and benchmarks demonstrate that OffQ outperforms state-of-the-art baselines, consistently improving model accuracy while preserving low-bit efficiency.
LoRaQ: Optimized Low Rank Approximation for 4-bit Quantization
Apr 20, 2026Post-training quantization (PTQ) is essential for deploying large diffusion transformers on resource-constrained hardware, but aggressive 4-bit quantization significantly degrades generative performance. Low-rank approximation methods have emerged as a promising solution by appending auxiliary linear branches to restore performance. However, current state-of-the-art approaches assume these branches must retain high precision (W16A16) and rely on heavy, data-dependent calibration for initialization. We challenge both limitations with LoRaQ (Low-Rank Approximated Quantization), a simple, data-free calibration approach that optimizes quantization error compensation. By overcoming the need for high-precision branches, LoRaQ enables the first fully sub-16 bit pipeline, allowing the low-rank branch itself to be quantized. We demonstrate that, at equal memory overhead, LoRaQ outperforms the state-of-the-art methods in their native implementations on Pixart-$Σ$ and SANA. We also analyze mixed-precision configurations, showing that setups such as W8A8, W6A6, and W4A8 for the low-rank branch, alongside a W4 main layer, yield superior results while maintaining a fully quantized architecture compatible with modern mixed-precision hardware.
Q-Drift: Quantization-Aware Drift Correction for Diffusion Model Sampling
Mar 18, 2026Post-training quantization (PTQ) is a practical path to deploy large diffusion models, but quantization noise can accumulate over the denoising trajectory and degrade generation quality. We propose Q-Drift, a principled sampler-side correction that treats quantization error as an implicit stochastic perturbation on each denoising step and derives a marginal-distribution-preserving drift adjustment. Q-Drift estimates a timestep-wise variance statistic from calibration, in practice requiring as few as 5 paired full-precision/quantized calibration runs. The resulting sampler correction is plug-and-play with common samplers, diffusion models, and PTQ methods, while incurring negligible overhead at inference. Across six diverse text-to-image models (spanning DiT and U-Net), three samplers (Euler, flow-matching, DPM-Solver++), and two PTQ methods (SVDQuant, MixDQ), Q-Drift improves FID over the corresponding quantized baseline in most settings, with up to 4.59 FID reduction on PixArt-Sigma (SVDQuant W3A4), while preserving CLIP scores.
Calibration-Reasoning Framework for Descriptive Speech Quality Assessment
Mar 10, 2026Explainable speech quality assessment requires moving beyond Mean Opinion Scores (MOS) to analyze underlying perceptual dimensions. To address this, we introduce a novel post-training method that tailors the foundational Audio Large Language Model for multidimensional reasoning, detection and classification of audio artifacts. First, a calibration stage aligns the model to predict predefined perceptual dimensions. Second, a reinforcement learning stage leverages Group Relative Policy Optimization (GRPO) with dimension-specific rewards to heavily enhance accuracy of descriptions and temporal localization of quality issues. With this approach we reach state-of-the-art results of 0.71 mean PCC score on the multidimensional QualiSpeech benchmark and 13% improvement in MOS prediction driven by RL-based reasoning. Furthermore, our fine-grained GRPO rewards substantially advance the model's ability to pinpoint and classify audio artifacts in time.
Subtractive Modulative Network with Learnable Periodic Activations
Feb 18, 2026We propose the Subtractive Modulative Network (SMN), a novel, parameter-efficient Implicit Neural Representation (INR) architecture inspired by classical subtractive synthesis. The SMN is designed as a principled signal processing pipeline, featuring a learnable periodic activation layer (Oscillator) that generates a multi-frequency basis, and a series of modulative mask modules (Filters) that actively generate high-order harmonics. We provide both theoretical analysis and empirical validation for our design. Our SMN achieves a PSNR of $40+$ dB on two image datasets, comparing favorably against state-of-the-art methods in terms of both reconstruction accuracy and parameter efficiency. Furthermore, consistent advantage is observed on the challenging 3D NeRF novel view synthesis task. Supplementary materials are available at https://inrainbws.github.io/smn/.
* 4 pages, 3 figures, 3 tables
LoRIF: Low-Rank Influence Functions for Scalable Training Data Attribution
Jan 29, 2026Training data attribution (TDA) identifies which training examples most influenced a model's prediction. The best-performing TDA methods exploits gradients to define an influence function. To overcome the scalability challenge arising from gradient computation, the most popular strategy is random projection (e.g., TRAK, LoGRA). However, this still faces two bottlenecks when scaling to large training sets and high-quality attribution: \emph{(i)} storing and loading projected per-example gradients for all $N$ training examples, where query latency is dominated by I/O; and \emph{(ii)} forming the $D \times D$ inverse Hessian approximation, which costs $O(D^2)$ memory. Both bottlenecks scale with the projection dimension $D$, yet increasing $D$ is necessary for attribution quality -- creating a quality-scalability tradeoff. We introduce \textbf{LoRIF (Low-Rank Influence Functions)}, which exploits low-rank structures of gradient to address both bottlenecks. First, we store rank-$c$ factors of the projected per-example gradients rather than full matrices, reducing storage and query-time I/O from $O(D)$ to $O(c\sqrt{D})$ per layer per sample. Second, we use truncated SVD with the Woodbury identity to approximate the Hessian term in an $r$-dimensional subspace, reducing memory from $O(D^2)$ to $O(Dr)$. On models from 0.1B to 70B parameters trained on datasets with millions of examples, LoRIF achieves up to 20$\times$ storage reduction and query-time speedup compared to LoGRA, while matching or exceeding its attribution quality. LoRIF makes gradient-based TDA practical at frontier scale.
FastPose-ViT: A Vision Transformer for Real-Time Spacecraft Pose Estimation
Dec 10, 2025Estimating the 6-degrees-of-freedom (6DoF) pose of a spacecraft from a single image is critical for autonomous operations like in-orbit servicing and space debris removal. Existing state-of-the-art methods often rely on iterative Perspective-n-Point (PnP)-based algorithms, which are computationally intensive and ill-suited for real-time deployment on resource-constrained edge devices. To overcome these limitations, we propose FastPose-ViT, a Vision Transformer (ViT)-based architecture that directly regresses the 6DoF pose. Our approach processes cropped images from object bounding boxes and introduces a novel mathematical formalism to map these localized predictions back to the full-image scale. This formalism is derived from the principles of projective geometry and the concept of "apparent rotation", where the model predicts an apparent rotation matrix that is then corrected to find the true orientation. We demonstrate that our method outperforms other non-PnP strategies and achieves performance competitive with state-of-the-art PnP-based techniques on the SPEED dataset. Furthermore, we validate our model's suitability for real-world space missions by quantizing it and deploying it on power-constrained edge hardware. On the NVIDIA Jetson Orin Nano, our end-to-end pipeline achieves a latency of ~75 ms per frame under sequential execution, and a non-blocking throughput of up to 33 FPS when stages are scheduled concurrently.
Learning to Weight Parameters for Data Attribution
Jun 06, 2025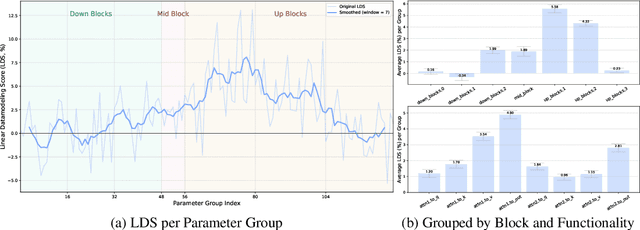

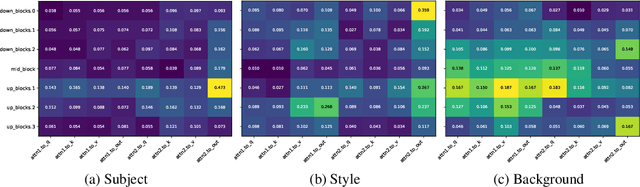
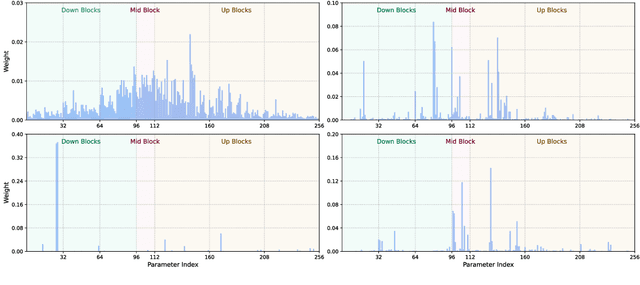
We study data attribution in generative models, aiming to identify which training examples most influence a given output. Existing methods achieve this by tracing gradients back to training data. However, they typically treat all network parameters uniformly, ignoring the fact that different layers encode different types of information and may thus draw information differently from the training set. We propose a method that models this by learning parameter importance weights tailored for attribution, without requiring labeled data. This allows the attribution process to adapt to the structure of the model, capturing which training examples contribute to specific semantic aspects of an output, such as subject, style, or background. Our method improves attribution accuracy across diffusion models and enables fine-grained insights into how outputs borrow from training data.
Demystifying Singular Defects in Large Language Models
Feb 10, 2025Large transformer models are known to produce high-norm tokens. In vision transformers (ViTs), such tokens have been mathematically modeled through the singular vectors of the linear approximations of layers. However, in large language models (LLMs), the underlying causes of high-norm tokens remain largely unexplored, and their different properties from those of ViTs require a new analysis framework. In this paper, we provide both theoretical insights and empirical validation across a range of recent models, leading to the following observations: i) The layer-wise singular direction predicts the abrupt explosion of token norms in LLMs. ii) The negative eigenvalues of a layer explain its sudden decay. iii) The computational pathways leading to high-norm tokens differ between initial and noninitial tokens. iv) High-norm tokens are triggered by the right leading singular vector of the matrix approximating the corresponding modules. We showcase two practical applications of these findings: the improvement of quantization schemes and the design of LLM signatures. Our findings not only advance the understanding of singular defects in LLMs but also open new avenues for their application. We expect that this work will stimulate further research into the internal mechanisms of LLMs and will therefore publicly release our code.