 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Drift: Quantization-Aware Drift Correction for Diffusion Model Sampling
Mar 18, 2026Post-training quantization (PTQ) is a practical path to deploy large diffusion models, but quantization noise can accumulate over the denoising trajectory and degrade generation quality. We propose Q-Drift, a principled sampler-side correction that treats quantization error as an implicit stochastic perturbation on each denoising step and derives a marginal-distribution-preserving drift adjustment. Q-Drift estimates a timestep-wise variance statistic from calibration, in practice requiring as few as 5 paired full-precision/quantized calibration runs. The resulting sampler correction is plug-and-play with common samplers, diffusion models, and PTQ methods, while incurring negligible overhead at inference. Across six diverse text-to-image models (spanning DiT and U-Net), three samplers (Euler, flow-matching, DPM-Solver++), and two PTQ methods (SVDQuant, MixDQ), Q-Drift improves FID over the corresponding quantized baseline in most settings, with up to 4.59 FID reduction on PixArt-Sigma (SVDQuant W3A4), while preserving CLIP scores.
FastPose-ViT: A Vision Transformer for Real-Time Spacecraft Pose Estimation
Dec 10, 2025Estimating the 6-degrees-of-freedom (6DoF) pose of a spacecraft from a single image is critical for autonomous operations like in-orbit servicing and space debris removal. Existing state-of-the-art methods often rely on iterative Perspective-n-Point (PnP)-based algorithms, which are computationally intensive and ill-suited for real-time deployment on resource-constrained edge devices. To overcome these limitations, we propose FastPose-ViT, a Vision Transformer (ViT)-based architecture that directly regresses the 6DoF pose. Our approach processes cropped images from object bounding boxes and introduces a novel mathematical formalism to map these localized predictions back to the full-image scale. This formalism is derived from the principles of projective geometry and the concept of "apparent rotation", where the model predicts an apparent rotation matrix that is then corrected to find the true orientation. We demonstrate that our method outperforms other non-PnP strategies and achieves performance competitive with state-of-the-art PnP-based techniques on the SPEED dataset. Furthermore, we validate our model's suitability for real-world space missions by quantizing it and deploying it on power-constrained edge hardware. On the NVIDIA Jetson Orin Nano, our end-to-end pipeline achieves a latency of ~75 ms per frame under sequential execution, and a non-blocking throughput of up to 33 FPS when stages are scheduled concurrently.
Temporally Compressed 3D Gaussian Splatting for Dynamic Scenes
Dec 07, 2024Recent advancements in high-fidelity dynamic scene reconstruction have leveraged dynamic 3D Gaussians and 4D Gaussian Splatting for realistic scene representation. However, to make these methods viable for real-time applications such as AR/VR, gaming, and rendering on low-power devices, substantial reductions in memory usage and improvements in rendering efficiency are required. While many state-of-the-art methods prioritize lightweight implementations, they struggle in handling scenes with complex motions or long sequences. In this work, we introduce Temporally Compressed 3D Gaussian Splatting (TC3DGS), a novel technique designed specifically to effectively compress dynamic 3D Gaussian representations. TC3DGS selectively prunes Gaussians based on their temporal relevance and employs gradient-aware mixed-precision quantization to dynamically compress Gaussian parameters. It additionally relies on a variation of the Ramer-Douglas-Peucker algorithm in a post-processing step to further reduce storage by interpolating Gaussian trajectories across frames. Our experiments across multiple datasets demonstrate that TC3DGS achieves up to 67$\times$ compression with minimal or no degradation in visual quality.
Self-Ensembling Gaussian Splatting for Few-shot Novel View Synthesis
Oct 31, 2024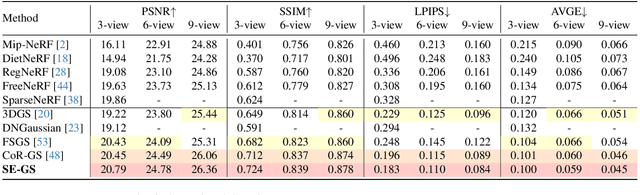

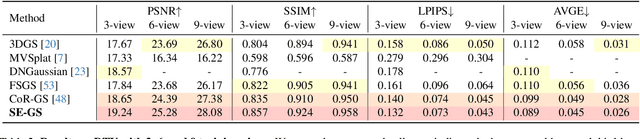

3D Gaussian Splatting (3DGS) has demonstrated remarkable effectiveness for novel view synthesis (NVS). However, the 3DGS model tends to overfit when trained with sparse posed views, limiting its generalization capacity for broader pose variations. In this paper, we alleviate the overfitting problem by introducing a self-ensembling Gaussian Splatting (SE-GS) approach. We present two Gaussian Splatting models named the $\mathbf{\Sigma}$-model and the $\mathbf{\Delta}$-model. The $\mathbf{\Sigma}$-model serves as the primary model that generates novel-view images during inference. At the training stage, the $\mathbf{\Sigma}$-model is guided away from specific local optima by an uncertainty-aware perturbing strategy. We dynamically perturb the $\mathbf{\Delta}$-model based on the uncertainties of novel-view renderings across different training steps, resulting in diverse temporal models sampled from the Gaussian parameter space without additional training costs. The geometry of the $\mathbf{\Sigma}$-model is regularized by penalizing discrepancies between the $\mathbf{\Sigma}$-model and the temporal samples. Therefore, our SE-GS conducts an effective and efficient regularization across a large number of Gaussian Splatting models, resulting in a robust ensemble, the $\mathbf{\Sigma}$-model. Experimental results on the LLFF, Mip-NeRF360, DTU, and MVImgNet datasets show that our approach improves NVS quality with few-shot training views, outperforming existing state-of-the-art methods. The code is released at https://github.com/sailor-z/SE-GS.
QT-DoG: Quantization-aware Training for Domain Generalization
Oct 08, 2024



Domain Generalization (DG) aims to train models that perform well not only on the training (source) domains but also on novel, unseen target data distributions. A key challenge in DG is preventing overfitting to source domains, which can be mitigated by finding flatter minima in the loss landscape. In this work, we propose Quantization-aware Training for Domain Generalization (QT-DoG) and demonstrate that weight quantization effectively leads to flatter minima in the loss landscape, thereby enhancing domain generalization. Unlike traditional quantization methods focused on model compression, QT-DoG exploits quantization as an implicit regularizer by inducing noise in model weights, guiding the optimization process toward flatter minima that are less sensitive to perturbations and overfitting. We provide both theoretical insights and empirical evidence demonstrating that quantization inherently encourages flatter minima, leading to better generalization across domains. Moreover, with the benefit of reducing the model size through quantization, we demonstrate that an ensemble of multiple quantized models further yields superior accuracy than the state-of-the-art DG approaches with no computational or memory overheads. Our extensive experiments demonstrate that QT-DoG generalizes across various datasets, architectures, and quantization algorithms, and can be combined with other DG methods, establishing its versatility and robustness.
Module-Wise Network Quantization for 6D Object Pose Estimation
Mar 12, 2023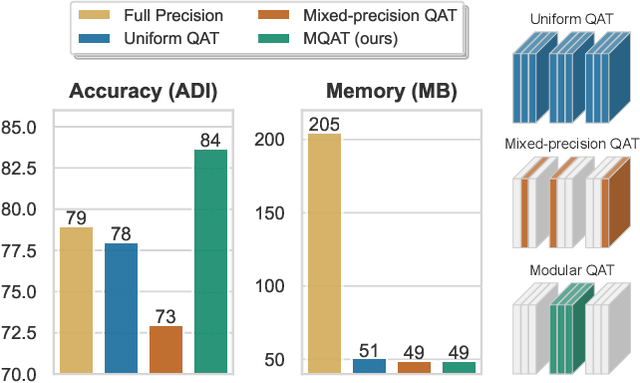

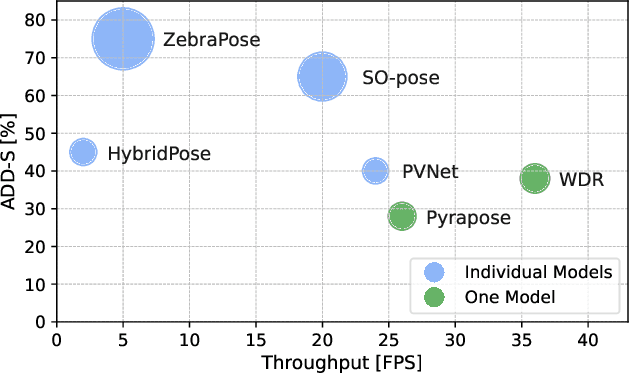
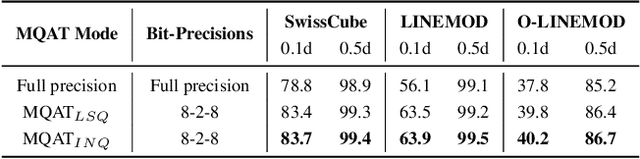
Many edge applications, such as collaborative robotics and spacecraft rendezvous, can benefit from 6D object pose estimation, but must do so on embedded platforms. Unfortunately, existing 6D pose estimation networks are typically too large for deployment in such situations and must therefore be compressed, while maintaining reliable performance. In this work, we present an approach to doing so by quantizing such networks. More precisely, we introduce a module-wise quantization strategy that, in contrast to uniform and mixed-precision quantization, accounts for the modular structure of typical 6D pose estimation frameworks. We demonstrate that uniquely compressing these modules outperforms uniform and mixed-precision quantization techniques. Moreover, our experiments evidence that module-wise quantization can lead to a significant accuracy boost. We showcase the generality of our approach using different datasets, quantization methodologies, and network architectures, including the recent ZebraPose.