 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastPose-ViT: A Vision Transformer for Real-Time Spacecraft Pose Estimation
Dec 10, 2025Estimating the 6-degrees-of-freedom (6DoF) pose of a spacecraft from a single image is critical for autonomous operations like in-orbit servicing and space debris removal. Existing state-of-the-art methods often rely on iterative Perspective-n-Point (PnP)-based algorithms, which are computationally intensive and ill-suited for real-time deployment on resource-constrained edge devices. To overcome these limitations, we propose FastPose-ViT, a Vision Transformer (ViT)-based architecture that directly regresses the 6DoF pose. Our approach processes cropped images from object bounding boxes and introduces a novel mathematical formalism to map these localized predictions back to the full-image scale. This formalism is derived from the principles of projective geometry and the concept of "apparent rotation", where the model predicts an apparent rotation matrix that is then corrected to find the true orientation. We demonstrate that our method outperforms other non-PnP strategies and achieves performance competitive with state-of-the-art PnP-based techniques on the SPEED dataset. Furthermore, we validate our model's suitability for real-world space missions by quantizing it and deploying it on power-constrained edge hardware. On the NVIDIA Jetson Orin Nano, our end-to-end pipeline achieves a latency of ~75 ms per frame under sequential execution, and a non-blocking throughput of up to 33 FPS when stages are scheduled concurrently.
Module-Wise Network Quantization for 6D Object Pose Estimation
Mar 12, 2023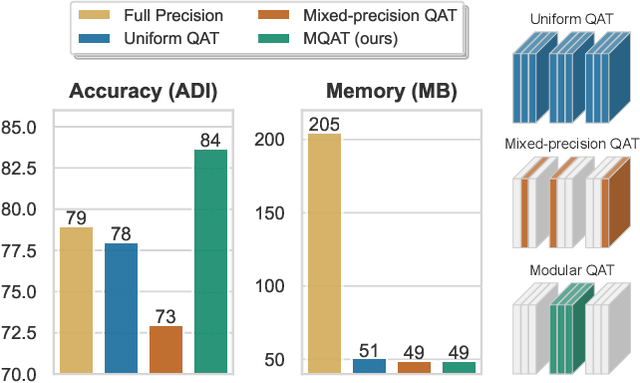

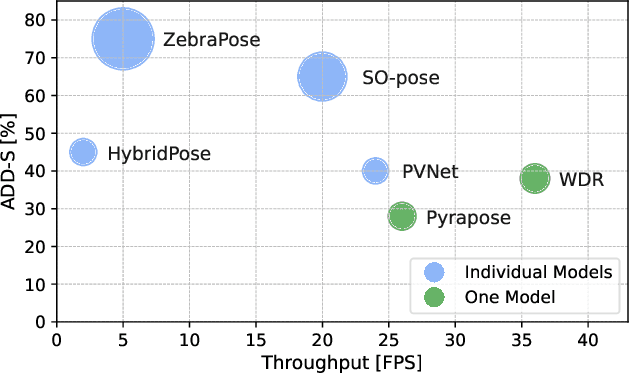
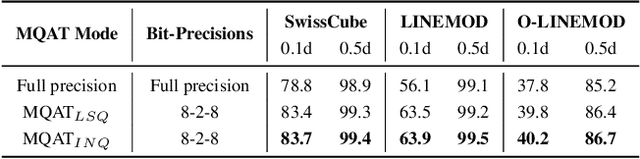
Many edge applications, such as collaborative robotics and spacecraft rendezvous, can benefit from 6D object pose estimation, but must do so on embedded platforms. Unfortunately, existing 6D pose estimation networks are typically too large for deployment in such situations and must therefore be compressed, while maintaining reliable performance. In this work, we present an approach to doing so by quantizing such networks. More precisely, we introduce a module-wise quantization strategy that, in contrast to uniform and mixed-precision quantization, accounts for the modular structure of typical 6D pose estimation frameworks. We demonstrate that uniquely compressing these modules outperforms uniform and mixed-precision quantization techniques. Moreover, our experiments evidence that module-wise quantization can lead to a significant accuracy boost. We showcase the generality of our approach using different datasets, quantization methodologies, and network architectures, including the recent ZebraPose.
Fusing RGBD Tracking and Segmentation Tree Sampling for Multi-Hypothesis Volumetric Segmentation
Apr 01, 2021



Despite rapid progress in scene segmentation in recent years, 3D segmentation methods are still limited when there is severe occlusion. The key challenge is estimating the segment boundaries of (partially) occluded objects, which are inherently ambiguous when considering only a single frame. In this work, we propose Multihypothesis Segmentation Tracking (MST), a novel method for volumetric segmentation in changing scenes, which allows scene ambiguity to be tracked and our estimates to be adjusted over time as we interact with the scene. Two main innovations allow us to tackle this difficult problem: 1) A novel way to sample possible segmentations from a segmentation tree; and 2) A novel approach to fusing tracking results with multiple segmentation estimates. These methods allow MST to track the segmentation state over time and incorporate new information, such as new objects being revealed. We evaluate our method on several cluttered tabletop environments in simulation and reality. Our results show that MST outperforms baselines in all tested scenes.
Inferring Occluded Geometry Improves Performance when Retrieving an Object from Dense Clutter
Sep 04, 2019


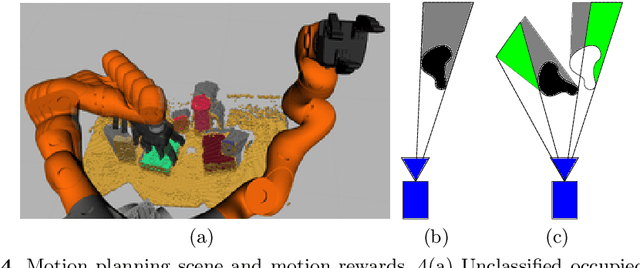
Object search -- the problem of finding a target object in a cluttered scene -- is essential to solve for many robotics applications in warehouse and household environments. However, cluttered environments entail that objects often occlude one another, making it difficult to segment objects and infer their shapes and properties. Instead of relying on the availability of CAD or other explicit models of scene objects, we augment a manipulation planner for cluttered environments with a state-of-the-art deep neural network for shape completion as well as a volumetric memory system, allowing the robot to reason about what may be contained in occluded areas. We test the system in a variety of tabletop manipulation scenes composed of household items, highlighting its applicability to realistic domains. Our results suggest that incorporating both components into a manipulation planning framework significantly reduces the number of actions needed to find a hidden object in dense clutter.