 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCFlow2: Plug-and-Play Object Pose Refiner with Shape-Constraint Scene Flow
Apr 12, 2025We introduce SCFlow2, a plug-and-play refinement framework for 6D object pose estimation. Most recent 6D object pose methods rely on refinement to get accurate results. However, most existing refinement methods either suffer from noises in establishing correspondences, or rely on retraining for novel objects. SCFlow2 is based on the SCFlow model designed for refinement with shape constraint, but formulates the additional depth as a regularization in the iteration via 3D scene flow for RGBD frames. The key design of SCFlow2 is an introduction of geometry constraints into the training of recurrent matching network, by combining the rigid-motion embeddings in 3D scene flow and 3D shape prior of the target. We train SCFlow2 on a combination of dataset Objaverse, GSO and ShapeNet, and evaluate on BOP datasets with novel objects. After using our method as a post-processing, most state-of-the-art methods produce significantly better results, without any retraining or fine-tuning. The source code is available at https://scflow2.github.io.
Hierarchical Flow Diffusion for Efficient Frame Interpolation
Apr 01, 2025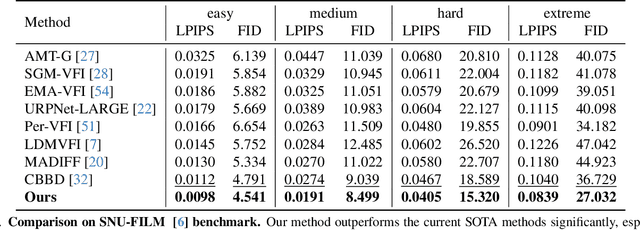



Most recent diffusion-based methods still show a large gap compared to non-diffusion methods for video frame interpolation, in both accuracy and efficiency. Most of them formulate the problem as a denoising procedure in latent space directly, which is less effective caused by the large latent space. We propose to model bilateral optical flow explicitly by hierarchical diffusion models, which has much smaller search space in the denoising procedure. Based on the flow diffusion model, we then use a flow-guided images synthesizer to produce the final result. We train the flow diffusion model and the image synthesizer end to end. Our method achieves state of the art in accuracy, and 10+ times faster than other diffusion-based methods. The project page is at: https://hfd-interpolation.github.io.
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
May 10, 2024



We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation
Aug 19, 2023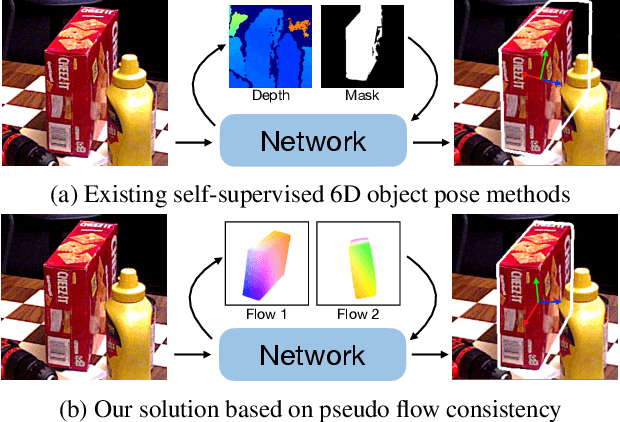
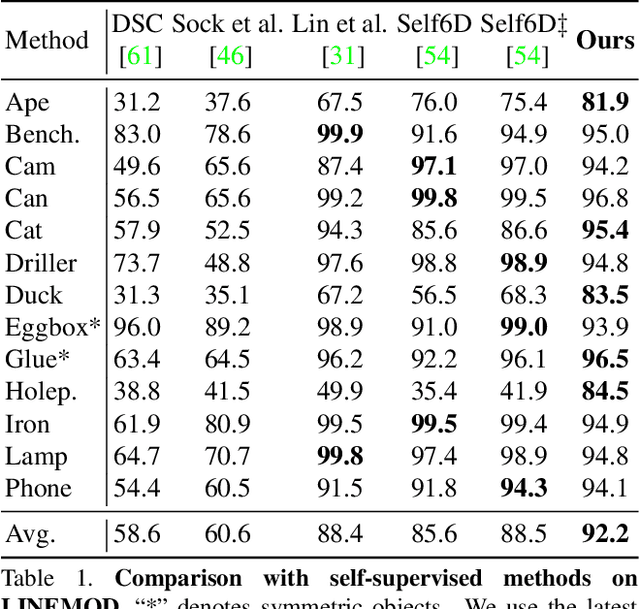
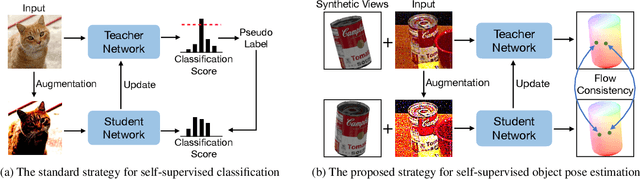
Most self-supervised 6D object pose estimation methods can only work with additional depth information or rely on the accurate annotation of 2D segmentation masks, limiting their application range. In this paper, we propose a 6D object pose estimation method that can be trained with pure RGB images without any auxiliary information. We first obtain a rough pose initialization from networks trained on synthetic images rendered from the target's 3D mesh. Then, we introduce a refinement strategy leveraging the geometry constraint in synthetic-to-real image pairs from multiple different views. We formulate this geometry constraint as pixel-level flow consistency between the training images with dynamically generated pseudo labels. We evaluate our method on three challenging datasets and demonstrate that it outperforms state-of-the-art self-supervised methods significantly, with neither 2D annotations nor additional depth images.
Shape-Constraint Recurrent Flow for 6D Object Pose Estimation
Jun 23, 2023Most recent 6D object pose methods use 2D optical flow to refine their results. However, the general optical flow methods typically do not consider the target's 3D shape information during matching, making them less effective in 6D object pose estimation. In this work, we propose a shape-constraint recurrent matching framework for 6D object pose estimation. We first compute a pose-induced flow based on the displacement of 2D reprojection between the initial pose and the currently estimated pose, which embeds the target's 3D shape implicitly. Then we use this pose-induced flow to construct the correlation map for the following matching iterations, which reduces the matching space significantly and is much easier to learn. Furthermore, we use networks to learn the object pose based on the current estimated flow, which facilitates the computation of the pose-induced flow for the next iteration and yields an end-to-end system for object pose. Finally, we optimize the optical flow and object pose simultaneously in a recurrent manner. We evaluate our method on three challenging 6D object pose datasets and show that it outperforms the state of the art significantly in both accuracy and efficiency.
NOPE: Novel Object Pose Estimation from a Single Image
Mar 23, 2023The practicality of 3D object pose estimation remains limited for many applications due to the need for prior knowledge of a 3D model and a training period for new objects. To address this limitation, we propose an approach that takes a single image of a new object as input and predicts the relative pose of this object in new images without prior knowledge of the object's 3D model and without requiring training time for new objects and categories. We achieve this by training a model to directly predict discriminative embeddings for viewpoints surrounding the object. This prediction is done using a simple U-Net architecture with attention and conditioned on the desired pose, which yields extremely fast inference. We compare our approach to state-of-the-art methods and show it outperforms them both in terms of accuracy and robustness. Our source code is publicly available at https://github.com/nv-nguyen/nope
Rigidity-Aware Detection for 6D Object Pose Estimation
Mar 22, 2023Most recent 6D object pose estimation methods first use object detection to obtain 2D bounding boxes before actually regressing the pose. However, the general object detection methods they use are ill-suited to handle cluttered scenes, thus producing poor initialization to the subsequent pose network. To address this, we propose a rigidity-aware detection method exploiting the fact that, in 6D pose estimation, the target objects are rigid. This lets us introduce an approach to sampling positive object regions from the entire visible object area during training, instead of naively drawing samples from the bounding box center where the object might be occluded. As such, every visible object part can contribute to the final bounding box prediction, yielding better detection robustness. Key to the success of our approach is a visibility map, which we propose to build using a minimum barrier distance between every pixel in the bounding box and the box boundary. Our results on seven challenging 6D pose estimation datasets evidence that our method outperforms general detection frameworks by a large margin. Furthermore, combined with a pose regression network, we obtain state-of-the-art pose estimation results on the challenging BOP benchmark.
Linear-Covariance Loss for End-to-End Learning of 6D Pose Estimation
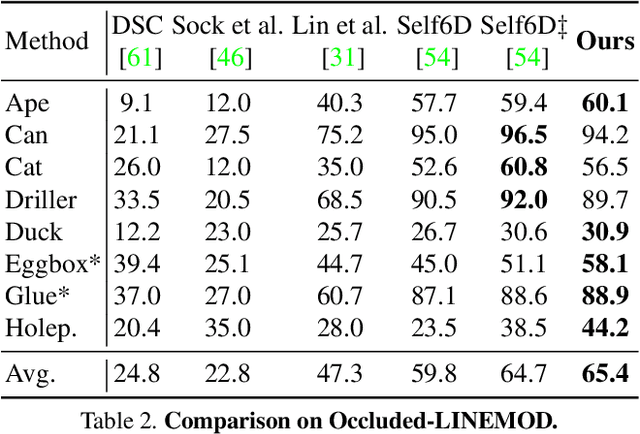
Mar 21, 2023Most modern image-based 6D object pose estimation methods learn to predict 2D-3D correspondences, from which the pose can be obtained using a PnP solver. Because of the non-differentiable nature of common PnP solvers, these methods are supervised via the individual correspondences. To address this, several methods have designed differentiable PnP strategies, thus imposing supervision on the pose obtained after the PnP step. Here, we argue that this conflicts with the averaging nature of the PnP problem, leading to gradients that may encourage the network to degrade the accuracy of individual correspondences. To address this, we derive a loss function that exploits the ground truth pose before solving the PnP problem. Specifically, we linearize the PnP solver around the ground-truth pose and compute the covariance of the resulting pose distribution. We then define our loss based on the diagonal covariance elements, which entails considering the final pose estimate yet not suffering from the PnP averaging issue. Our experiments show that our loss consistently improves the pose estimation accuracy for both dense and sparse correspondence based methods, achieving state-of-the-art results on both Linemod-Occluded and YCB-Video.
Module-Wise Network Quantization for 6D Object Pose Estimation
Mar 12, 2023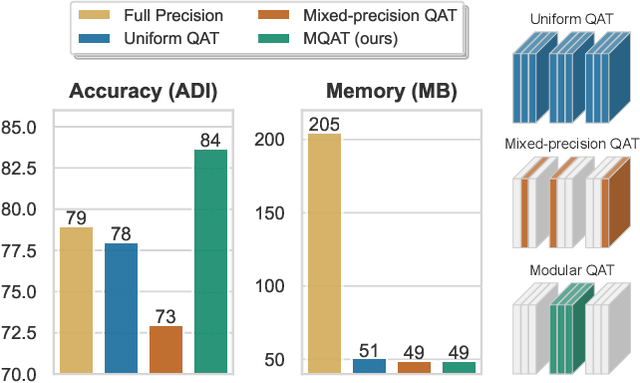

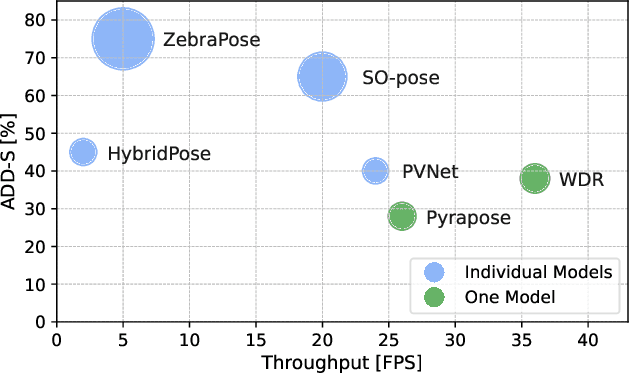
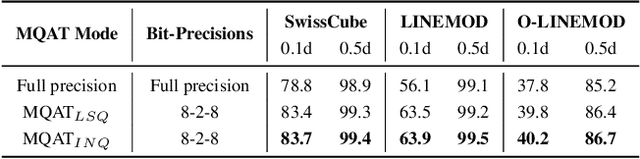
Many edge applications, such as collaborative robotics and spacecraft rendezvous, can benefit from 6D object pose estimation, but must do so on embedded platforms. Unfortunately, existing 6D pose estimation networks are typically too large for deployment in such situations and must therefore be compressed, while maintaining reliable performance. In this work, we present an approach to doing so by quantizing such networks. More precisely, we introduce a module-wise quantization strategy that, in contrast to uniform and mixed-precision quantization, accounts for the modular structure of typical 6D pose estimation frameworks. We demonstrate that uniquely compressing these modules outperforms uniform and mixed-precision quantization techniques. Moreover, our experiments evidence that module-wise quantization can lead to a significant accuracy boost. We showcase the generality of our approach using different datasets, quantization methodologies, and network architectures, including the recent ZebraPose.
Finer-Grained Correlations: Location Priors for Unseen Object Pose Estimation
Nov 29, 2022



We present a new method which provides object location priors for previously unseen object 6D pose estimation. Existing approaches build upon a template matching strategy and convolve a set of reference images with the query. Unfortunately, their performance is affected by the object scale mismatches between the references and the query. To address this issue, we present a finer-grained correlation estimation module, which handles the object scale mismatches by computing correlations with adjustable receptive fields. We also propose to decouple the correlations into scale-robust and scale-aware representations to estimate the object location and size, respectively. Our method achieves state-of-the-art unseen object localization and 6D pose estimation results on LINEMOD and GenMOP. We further construct a challenging synthetic dataset, where the results highlight the better robustness of our method to varying backgrounds, illuminations, and object sizes, as well as to the reference-query domain gap.