 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
TinyDrop: Tiny Model Guided Token Dropping for Vision Transformers
Sep 03, 2025Vision Transformers (ViTs) achieve strong performance in image classification but incur high computational costs from processing all image tokens. To reduce inference costs in large ViTs without compromising accuracy, we propose TinyDrop, a training-free token dropping framework guided by a lightweight vision model. The guidance model estimates the importance of tokens while performing inference, thereby selectively discarding low-importance tokens if large vit models need to perform attention calculations. The framework operates plug-and-play, requires no architectural modifications, and is compatible with diverse ViT architectures. Evaluations on standard image classification benchmarks demonstrate that our framework reduces FLOPs by up to 80% for ViTs with minimal accuracy degradation, highlighting its generalization capability and practical utility for efficient ViT-based classification.
Optimal Brain Connection: Towards Efficient Structural Pruning
Aug 07, 2025Structural pruning has been widely studied for its effectiveness in compressing neural networks. However, existing methods often neglect the interconnections among parameters. To address this limitation, this paper proposes a structural pruning framework termed Optimal Brain Connection. First, we introduce the Jacobian Criterion, a first-order metric for evaluating the saliency of structural parameters. Unlike existing first-order methods that assess parameters in isolation, our criterion explicitly captures both intra-component interactions and inter-layer dependencies. Second, we propose the Equivalent Pruning mechanism, which utilizes autoencoders to retain the contributions of all original connection--including pruned ones--during fine-tuning. Experimental results demonstrate that the Jacobian Criterion outperforms several popular metrics in preserving model performance, while the Equivalent Pruning mechanism effectively mitigates performance degradation after fine-tuning. Code: https://github.com/ShaowuChen/Optimal_Brain_Connection
ORXE: Orchestrating Experts for Dynamically Configurable Efficiency
May 07, 2025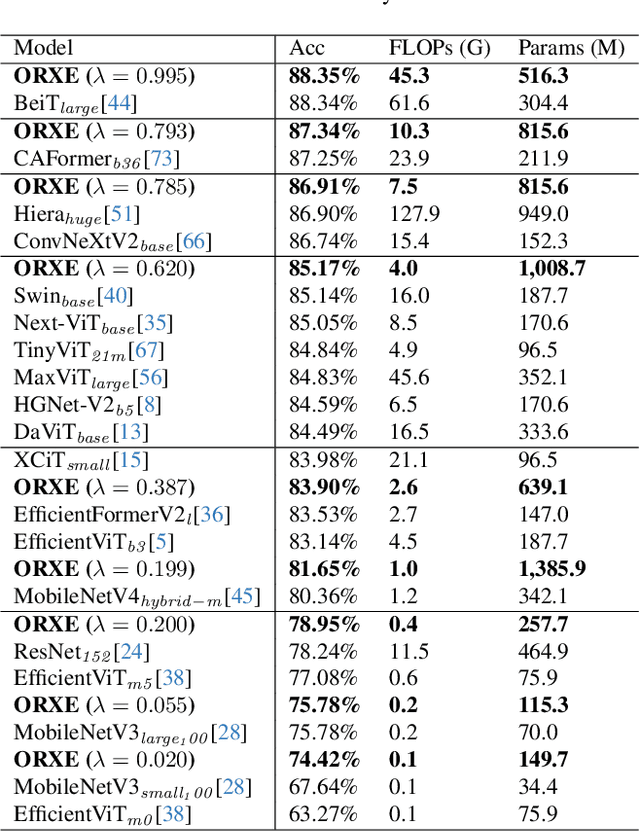
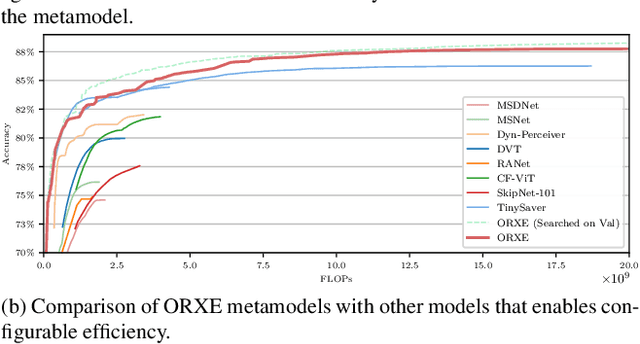
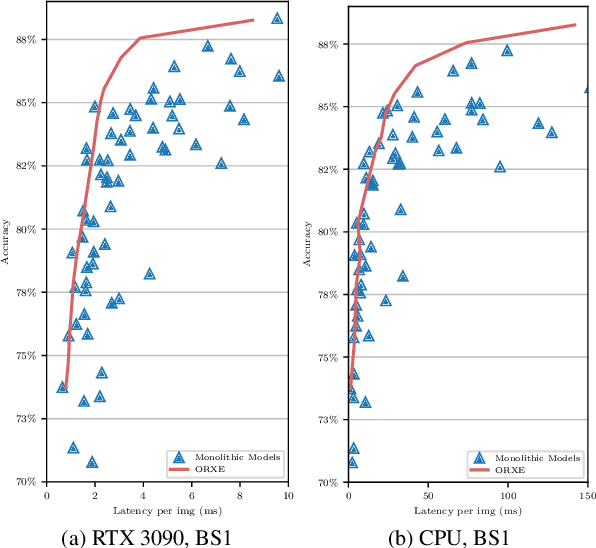
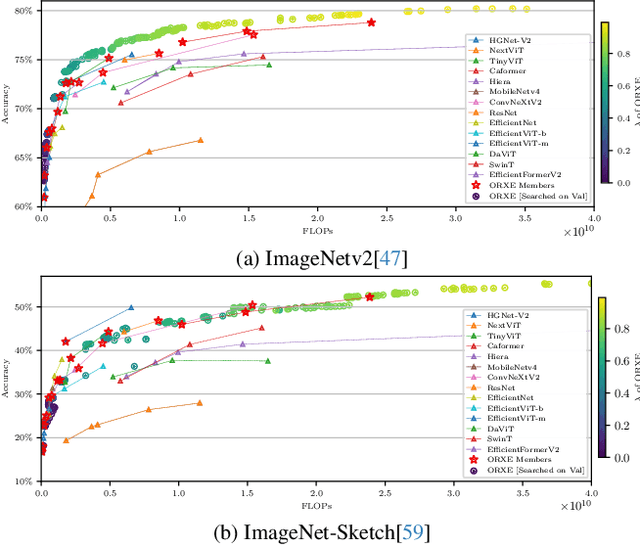
This paper presents ORXE, a modular and adaptable framework for achieving real-time configurable efficiency in AI models. By leveraging a collection of pre-trained experts with diverse computational costs and performance levels, ORXE dynamically adjusts inference pathways based on the complexity of input samples. Unlike conventional approaches that require complex metamodel training, ORXE achieves high efficiency and flexibility without complicating the development process. The proposed system utilizes a confidence-based gating mechanism to allocate appropriate computational resources for each input. ORXE also supports adjustments to the preference between inference cost and prediction performance across a wide range during runtime. We implemented a training-free ORXE system for image classification tasks, evaluating its efficiency and accuracy across various devices. The results demonstrate that ORXE achieves superior performance compared to individual experts and other dynamic models in most cases. This approach can be extended to other applications, providing a scalable solution for diverse real-world deployment scenarios.
SCFlow2: Plug-and-Play Object Pose Refiner with Shape-Constraint Scene Flow
Apr 12, 2025We introduce SCFlow2, a plug-and-play refinement framework for 6D object pose estimation. Most recent 6D object pose methods rely on refinement to get accurate results. However, most existing refinement methods either suffer from noises in establishing correspondences, or rely on retraining for novel objects. SCFlow2 is based on the SCFlow model designed for refinement with shape constraint, but formulates the additional depth as a regularization in the iteration via 3D scene flow for RGBD frames. The key design of SCFlow2 is an introduction of geometry constraints into the training of recurrent matching network, by combining the rigid-motion embeddings in 3D scene flow and 3D shape prior of the target. We train SCFlow2 on a combination of dataset Objaverse, GSO and ShapeNet, and evaluate on BOP datasets with novel objects. After using our method as a post-processing, most state-of-the-art methods produce significantly better results, without any retraining or fine-tuning. The source code is available at https://scflow2.github.io.
Tiny Models are the Computational Saver for Large Models
Mar 26, 2024This paper introduces TinySaver, an early-exit-like dynamic model compression approach which employs tiny models to substitute large models adaptively. Distinct from traditional compression techniques, dynamic methods like TinySaver can leverage the difficulty differences to allow certain inputs to complete their inference processes early, thereby conserving computational resources. Most existing early exit designs are implemented by attaching additional network branches to the model's backbone. Our study, however, reveals that completely independent tiny models can replace a substantial portion of the larger models' job with minimal impact on performance. Employing them as the first exit can remarkably enhance computational efficiency. By searching and employing the most appropriate tiny model as the computational saver for a given large model, the proposed approaches work as a novel and generic method to model compression. This finding will help the research community in exploring new compression methods to address the escalating computational demands posed by rapidly evolving AI models. Our evaluation of this approach in ImageNet-1k classification demonstrates its potential to reduce the number of compute operations by up to 90%, with only negligible losses in performance, across various modern vision models. The code of this work will be available.
DyCE: Dynamic Configurable Exiting for Deep Learning Compression and Scaling
Mar 04, 2024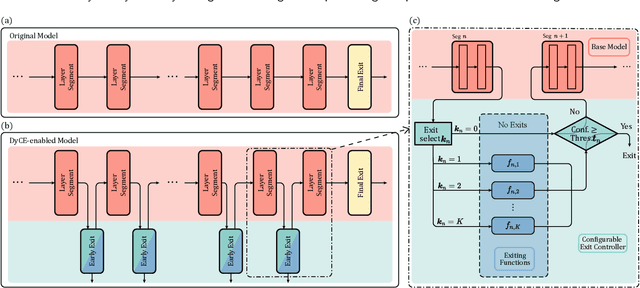
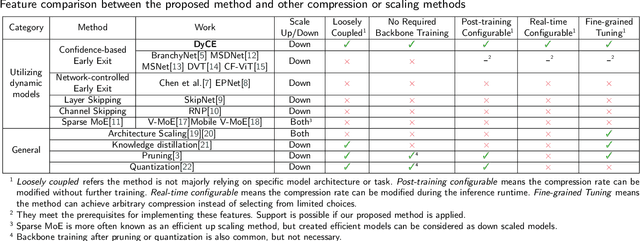
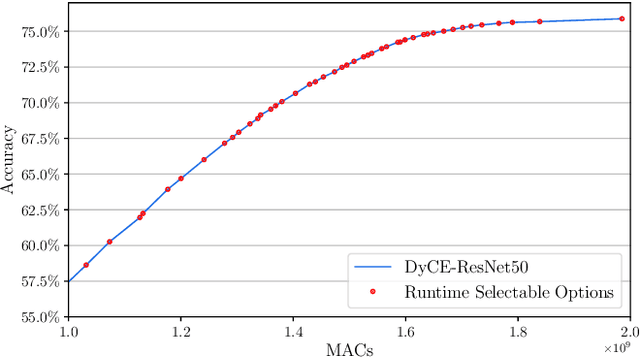
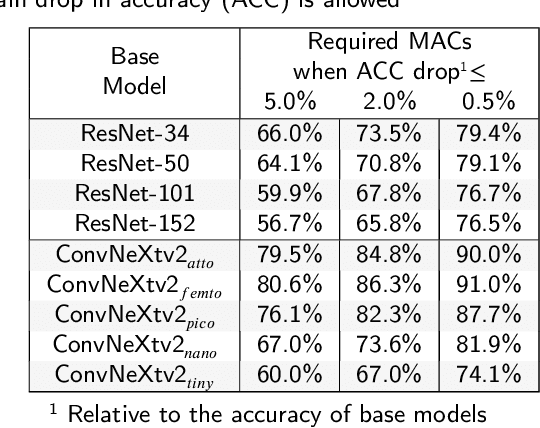
Modern deep learning (DL) models necessitate the employment of scaling and compression techniques for effective deployment in resource-constrained environments. Most existing techniques, such as pruning and quantization are generally static. On the other hand, dynamic compression methods, such as early exits, reduce complexity by recognizing the difficulty of input samples and allocating computation as needed. Dynamic methods, despite their superior flexibility and potential for co-existing with static methods, pose significant challenges in terms of implementation due to any changes in dynamic parts will influence subsequent processes. Moreover, most current dynamic compression designs are monolithic and tightly integrated with base models, thereby complicating the adaptation to novel base models. This paper introduces DyCE, an dynamic configurable early-exit framework that decouples design considerations from each other and from the base model. Utilizing this framework, various types and positions of exits can be organized according to predefined configurations, which can be dynamically switched in real-time to accommodate evolving performance-complexity requirements. We also propose techniques for generating optimized configurations based on any desired trade-off between performance and computational complexity. This empowers future researchers to focus on the improvement of individual exits without latent compromise of overall system performance. The efficacy of this approach is demonstrated through image classification tasks with deep CNNs. DyCE significantly reduces the computational complexity by 23.5% of ResNet152 and 25.9% of ConvNextv2-tiny on ImageNet, with accuracy reductions of less than 0.5%. Furthermore, DyCE offers advantages over existing dynamic methods in terms of real-time configuration and fine-grained performance tuning.
Unsupervised Pre-Training Using Masked Autoencoders for ECG Analysis
Oct 17, 2023



Unsupervised learning methods have become increasingly important in deep learning due to their demonstrated large utilization of datasets and higher accuracy in computer vision and natural language processing tasks. There is a growing trend to extend unsupervised learning methods to other domains, which helps to utilize a large amount of unlabelled data. This paper proposes an unsupervised pre-training technique based on masked autoencoder (MAE) for electrocardiogram (ECG) signals. In addition, we propose a task-specific fine-tuning to form a complete framework for ECG analysis. The framework is high-level, universal, and not individually adapted to specific model architectures or tasks. Experiments are conducted using various model architectures and large-scale datasets, resulting in an accuracy of 94.39% on the MITDB dataset for ECG arrhythmia classification task. The result shows a better performance for the classification of previously unseen data for the proposed approach compared to fully supervised methods.
P-ROCKET: Pruning Random Convolution Kernels for Time Series Classification
Sep 15, 2023In recent years, two time series classification models, ROCKET and MINIROCKET, have attracted much attention for their low training cost and state-of-the-art accuracy. Utilizing random 1-D convolutional kernels without training, ROCKET and MINIROCKET can rapidly extract features from time series data, allowing for the efficient fitting of linear classifiers. However, to comprehensively capture useful features, a large number of random kernels are required, which is incompatible for resource-constrained devices. Therefore, a heuristic evolutionary algorithm named S-ROCKET is devised to recognize and prune redundant kernels. Nevertheless, the inherent nature of evolutionary algorithms renders the evaluation of kernels within S-ROCKET an unacceptable time-consuming process. In this paper, diverging from S-ROCKET, which directly evaluates random kernels with nonsignificant differences, we remove kernels from a feature selection perspective by eliminating associating connections in the sequential classification layer. To this end, we start by formulating the pruning challenge as a Group Elastic Net classification problem and employ the ADMM method to arrive at a solution. Sequentially, we accelerate the aforementioned time-consuming solving process by bifurcating the $l_{2,1}$ and $l_2$ regularizations into two sequential stages and solve them separately, which ultimately forms our core algorithm, named P-ROCKET. Stage 1 of P-ROCKET employs group-wise regularization similarly to our initial ADMM-based Algorithm, but introduces dynamically varying penalties to greatly accelerate the process. To mitigate overfitting, Stage 2 of P-ROCKET implements element-wise regularization to refit a linear classifier, utilizing the retained features.