 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Student-LLM Interaction in a Software Engineering Project
Feb 03, 2025

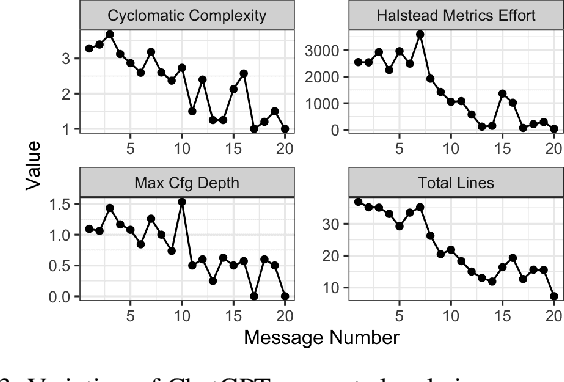

Large Language Models (LLMs) are becoming increasingly competent across various domains, educators are showing a growing interest in integrating these LLMs into the learning process. Especially in software engineering, LLMs have demonstrated qualitatively better capabilities in code summarization, code generation, and debugging. Despite various research on LLMs for software engineering tasks in practice, limited research captures the benefits of LLMs for pedagogical advancements and their impact on the student learning process. To this extent, we analyze 126 undergraduate students' interaction with an AI assistant during a 13-week semester to understand the benefits of AI for software engineering learning. We analyze the conversations, code generated, code utilized, and the human intervention levels to integrate the code into the code base. Our findings suggest that students prefer ChatGPT over CoPilot. Our analysis also finds that ChatGPT generates responses with lower computational complexity compared to CoPilot. Furthermore, conversational-based interaction helps improve the quality of the code generated compared to auto-generated code. Early adoption of LLMs in software engineering is crucial to remain competitive in the rapidly developing landscape. Hence, the next generation of software engineers must acquire the necessary skills to interact with AI to improve productivity.
An Empirical Study on Usage and Perceptions of LLMs in a Software Engineering Project
Jan 29, 2024



Large Language Models (LLMs) represent a leap in artificial intelligence, excelling in tasks using human language(s). Although the main focus of general-purpose LLMs is not code generation, they have shown promising results in the domain. However, the usefulness of LLMs in an academic software engineering project has not been fully explored yet. In this study, we explore the usefulness of LLMs for 214 students working in teams consisting of up to six members. Notably, in the academic course through which this study is conducted, students were encouraged to integrate LLMs into their development tool-chain, in contrast to most other academic courses that explicitly prohibit the use of LLMs. In this paper, we analyze the AI-generated code, prompts used for code generation, and the human intervention levels to integrate the code into the code base. We also conduct a perception study to gain insights into the perceived usefulness, influencing factors, and future outlook of LLM from a computer science student's perspective. Our findings suggest that LLMs can play a crucial role in the early stages of software development, especially in generating foundational code structures, and helping with syntax and error debugging. These insights provide us with a framework on how to effectively utilize LLMs as a tool to enhance the productivity of software engineering students, and highlight the necessity of shifting the educational focus toward preparing students for successful human-AI collaboration.
Unsupervised Pre-Training Using Masked Autoencoders for ECG Analysis
Oct 17, 2023



Unsupervised learning methods have become increasingly important in deep learning due to their demonstrated large utilization of datasets and higher accuracy in computer vision and natural language processing tasks. There is a growing trend to extend unsupervised learning methods to other domains, which helps to utilize a large amount of unlabelled data. This paper proposes an unsupervised pre-training technique based on masked autoencoder (MAE) for electrocardiogram (ECG) signals. In addition, we propose a task-specific fine-tuning to form a complete framework for ECG analysis. The framework is high-level, universal, and not individually adapted to specific model architectures or tasks. Experiments are conducted using various model architectures and large-scale datasets, resulting in an accuracy of 94.39% on the MITDB dataset for ECG arrhythmia classification task. The result shows a better performance for the classification of previously unseen data for the proposed approach compared to fully supervised methods.