 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlood-LDM: Generalizable Latent Diffusion Models for rapid and accurate zero-shot High-Resolution Flood Mapping
Nov 18, 2025



Flood prediction is critical for emergency planning and response to mitigate human and economic losses. Traditional physics-based hydrodynamic models generate high-resolution flood maps using numerical methods requiring fine-grid discretization; which are computationally intensive and impractical for real-time large-scale applications. While recent studies have applied convolutional neural networks for flood map super-resolution with good accuracy and speed, they suffer from limited generalizability to unseen areas. In this paper, we propose a novel approach that leverages latent diffusion models to perform super-resolution on coarse-grid flood maps, with the objective of achieving the accuracy of fine-grid flood maps while significantly reducing inference time. Experimental results demonstrate that latent diffusion models substantially decrease the computational time required to produce high-fidelity flood maps without compromising on accuracy, enabling their use in real-time flood risk management. Moreover, diffusion models exhibit superior generalizability across different physical locations, with transfer learning further accelerating adaptation to new geographic regions. Our approach also incorporates physics-informed inputs, addressing the common limitation of black-box behavior in machine learning, thereby enhancing interpretability. Code is available at https://github.com/neosunhan/flood-diff.
Unmasking the Unknown: Facial Deepfake Detection in the Open-Set Paradigm
Mar 11, 2025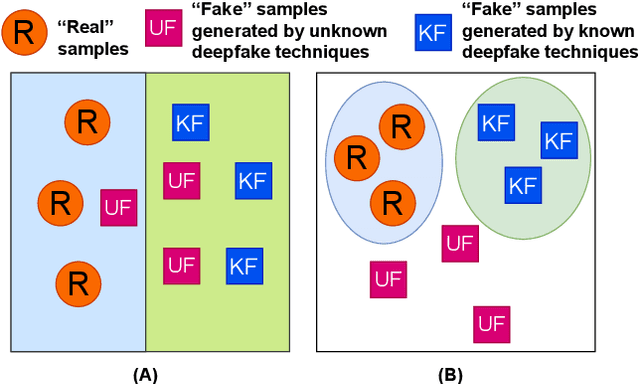
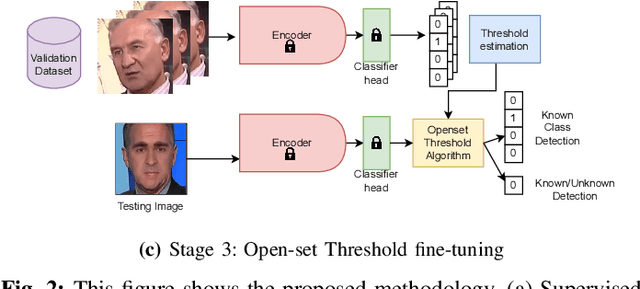
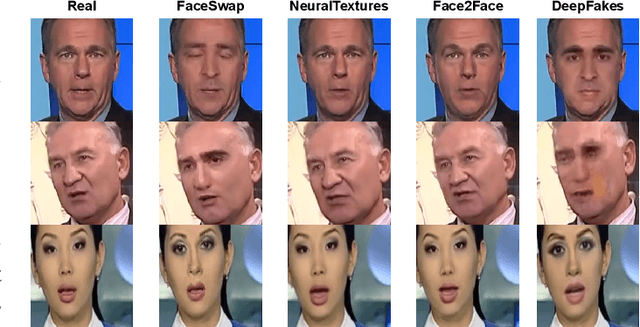
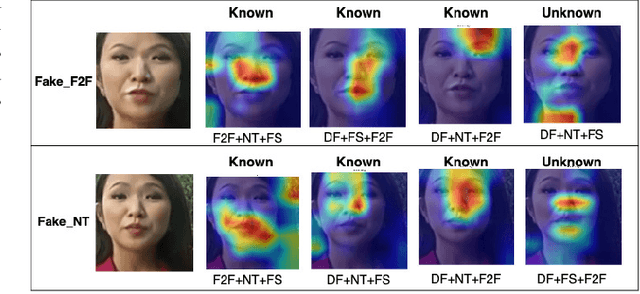
Facial forgery methods such as deepfakes can be misused for identity manipulation and spreading misinformation. They have evolved alongside advancements in generative AI, leading to new and more sophisticated forgery techniques that diverge from existing 'known' methods. Conventional deepfake detection methods use the closedset paradigm, thus limiting their applicability to detecting forgeries created using methods that are not part of the training dataset. In this paper, we propose a shift from the closed-set paradigm for deepfake detection. In the open-set paradigm, models are designed not only to identify images created by known facial forgery methods but also to identify and flag those produced by previously unknown methods as 'unknown' and not as unforged/real/unmanipulated. In this paper, we propose an open-set deepfake classification algorithm based on supervised contrastive learning. The open-set paradigm used in our model allows it to function as a more robust tool capable of handling emerging and unseen deepfake techniques, enhancing reliability and confidence, and complementing forensic analysis. In open-set paradigm, we identify three groups including the "unknown group that is neither considered known deepfake nor real. We investigate deepfake open-set classification across three scenarios, classifying deepfakes from unknown methods not as real, distinguishing real images from deepfakes, and classifying deepfakes from known methods, using the FaceForensics++ dataset as a benchmark. Our method achieves state of the art results in the first two tasks and competitive results in the third task.
Analysis of Student-LLM Interaction in a Software Engineering Project
Feb 03, 2025

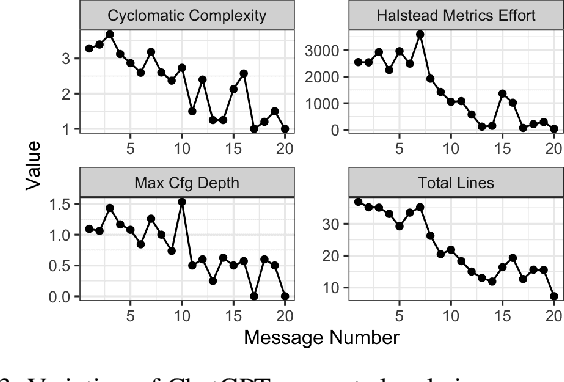

Large Language Models (LLMs) are becoming increasingly competent across various domains, educators are showing a growing interest in integrating these LLMs into the learning process. Especially in software engineering, LLMs have demonstrated qualitatively better capabilities in code summarization, code generation, and debugging. Despite various research on LLMs for software engineering tasks in practice, limited research captures the benefits of LLMs for pedagogical advancements and their impact on the student learning process. To this extent, we analyze 126 undergraduate students' interaction with an AI assistant during a 13-week semester to understand the benefits of AI for software engineering learning. We analyze the conversations, code generated, code utilized, and the human intervention levels to integrate the code into the code base. Our findings suggest that students prefer ChatGPT over CoPilot. Our analysis also finds that ChatGPT generates responses with lower computational complexity compared to CoPilot. Furthermore, conversational-based interaction helps improve the quality of the code generated compared to auto-generated code. Early adoption of LLMs in software engineering is crucial to remain competitive in the rapidly developing landscape. Hence, the next generation of software engineers must acquire the necessary skills to interact with AI to improve productivity.
KVC-onGoing: Keystroke Verification Challenge
Dec 29, 2024



This article presents the Keystroke Verification Challenge - onGoing (KVC-onGoing), on which researchers can easily benchmark their systems in a common platform using large-scale public databases, the Aalto University Keystroke databases, and a standard experimental protocol. The keystroke data consist of tweet-long sequences of variable transcript text from over 185,000 subjects, acquired through desktop and mobile keyboards simulating real-life conditions. The results on the evaluation set of KVC-onGoing have proved the high discriminative power of keystroke dynamics, reaching values as low as 3.33% of Equal Error Rate (EER) and 11.96% of False Non-Match Rate (FNMR) @1% False Match Rate (FMR) in the desktop scenario, and 3.61% of EER and 17.44% of FNMR @1% at FMR in the mobile scenario, significantly improving previous state-of-the-art results. Concerning demographic fairness, the analyzed scores reflect the subjects' age and gender to various extents, not negligible in a few cases. The framework runs on CodaLab.
AniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Jun 19, 2024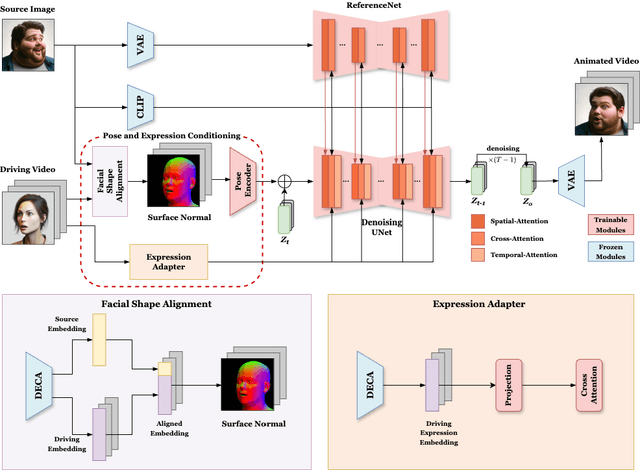
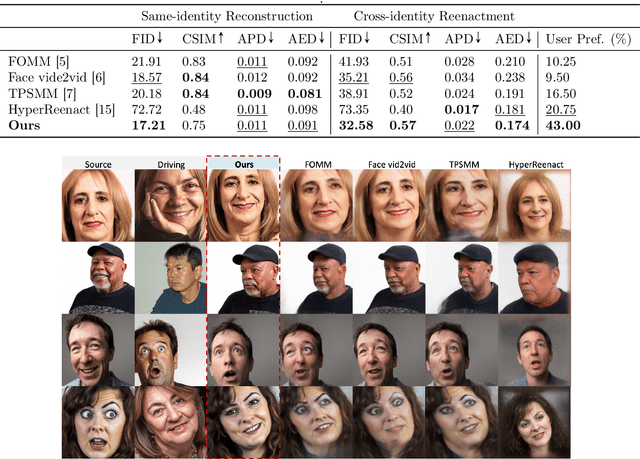
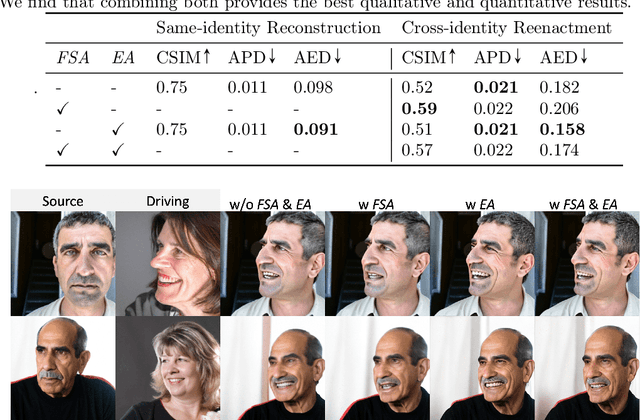

Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.
IEEE BigData 2023 Keystroke Verification Challenge (KVC)
Jan 29, 2024This paper describes the results of the IEEE BigData 2023 Keystroke Verification Challenge (KVC), that considers the biometric verification performance of Keystroke Dynamics (KD), captured as tweet-long sequences of variable transcript text from over 185,000 subjects. The data are obtained from two of the largest public databases of KD up to date, the Aalto Desktop and Mobile Keystroke Databases, guaranteeing a minimum amount of data per subject, age and gender annotations, absence of corrupted data, and avoiding excessively unbalanced subject distributions with respect to the considered demographic attributes. Several neural architectures were proposed by the participants, leading to global Equal Error Rates (EERs) as low as 3.33% and 3.61% achieved by the best team respectively in the desktop and mobile scenario, outperforming the current state of the art biometric verification performance for KD. Hosted on CodaLab, the KVC will be made ongoing to represent a useful tool for the research community to compare different approaches under the same experimental conditions and to deepen the knowledge of the field.
An Empirical Study on Usage and Perceptions of LLMs in a Software Engineering Project
Jan 29, 2024



Large Language Models (LLMs) represent a leap in artificial intelligence, excelling in tasks using human language(s). Although the main focus of general-purpose LLMs is not code generation, they have shown promising results in the domain. However, the usefulness of LLMs in an academic software engineering project has not been fully explored yet. In this study, we explore the usefulness of LLMs for 214 students working in teams consisting of up to six members. Notably, in the academic course through which this study is conducted, students were encouraged to integrate LLMs into their development tool-chain, in contrast to most other academic courses that explicitly prohibit the use of LLMs. In this paper, we analyze the AI-generated code, prompts used for code generation, and the human intervention levels to integrate the code into the code base. We also conduct a perception study to gain insights into the perceived usefulness, influencing factors, and future outlook of LLM from a computer science student's perspective. Our findings suggest that LLMs can play a crucial role in the early stages of software development, especially in generating foundational code structures, and helping with syntax and error debugging. These insights provide us with a framework on how to effectively utilize LLMs as a tool to enhance the productivity of software engineering students, and highlight the necessity of shifting the educational focus toward preparing students for successful human-AI collaboration.
Undercover Deepfakes: Detecting Fake Segments in Videos
May 16, 2023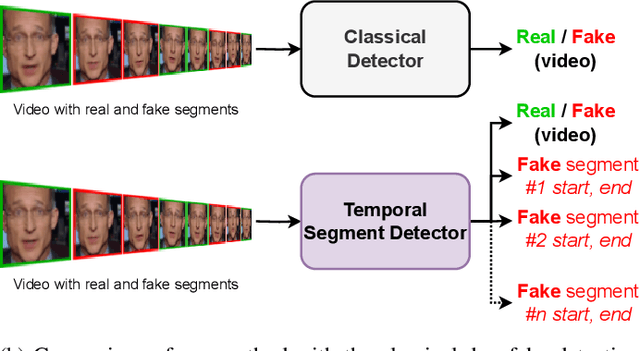
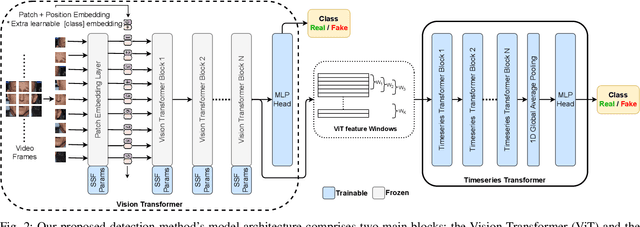

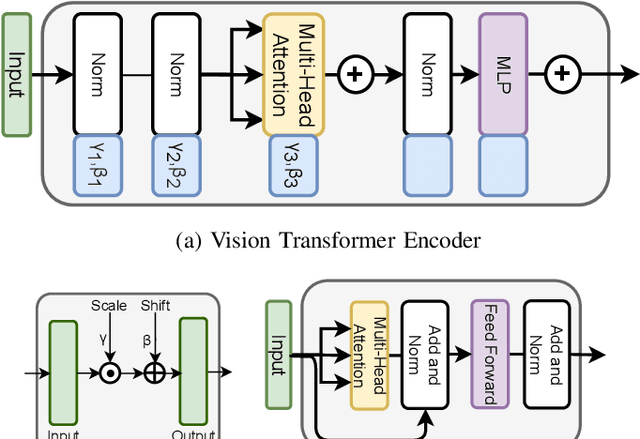
The recent renaissance in generative models, driven primarily by the advent of diffusion models and iterative improvement in GAN methods, has enabled many creative applications. However, each advancement is also accompanied by a rise in the potential for misuse. In the arena of deepfake generation this is a key societal issue. In particular, the ability to modify segments of videos using such generative techniques creates a new paradigm of deepfakes which are mostly real videos altered slightly to distort the truth. Current deepfake detection methods in the academic literature are not evaluated on this paradigm. In this paper, we present a deepfake detection method able to address this issue by performing both frame and video level deepfake prediction. To facilitate testing our method we create a new benchmark dataset where videos have both real and fake frame sequences. Our method utilizes the Vision Transformer, Scaling and Shifting pretraining and Timeseries Transformer to temporally segment videos to help facilitate the interpretation of possible deepfakes. Extensive experiments on a variety of deepfake generation methods show excellent results on temporal segmentation and classical video level predictions as well. In particular, the paradigm we introduce will form a powerful tool for the moderation of deepfakes, where human oversight can be better targeted to the parts of videos suspected of being deepfakes. All experiments can be reproduced at: https://github.com/sanjaysaha1311/temporal-deepfake-segmentation.
IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C)
Oct 06, 2022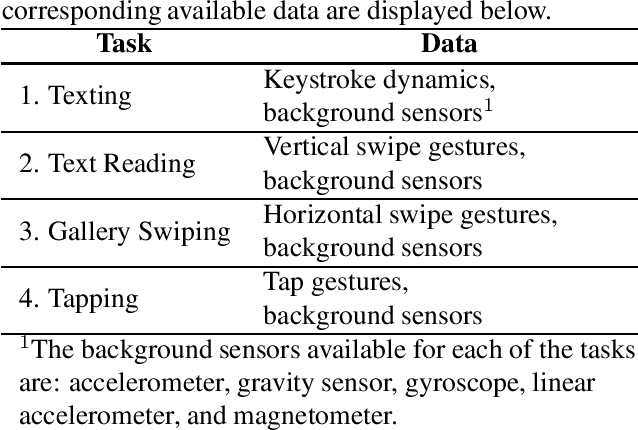
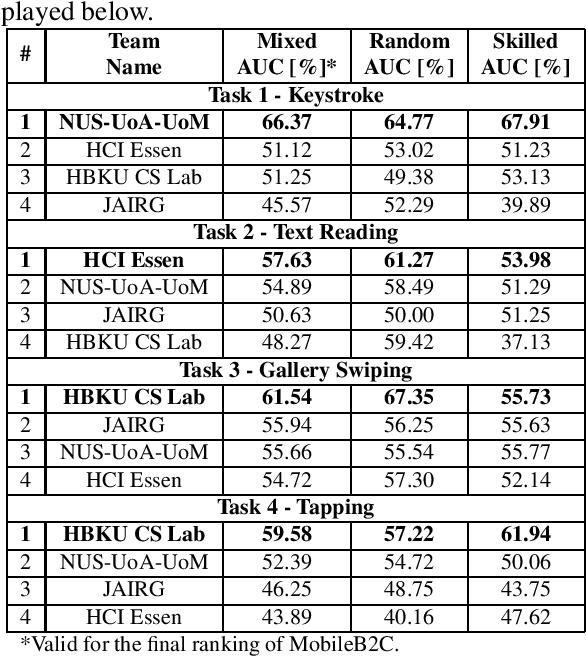
This paper describes the experimental framework and results of the IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C). The aim of MobileB2C is benchmarking mobile user authentication systems based on behavioral biometric traits transparently acquired by mobile devices during ordinary Human-Computer Interaction (HCI), using a novel public database, BehavePassDB, and a standard experimental protocol. The competition is divided into four tasks corresponding to typical user activities: keystroke, text reading, gallery swiping, and tapping. The data are composed of touchscreen data and several background sensor data simultaneously acquired. "Random" (different users with different devices) and "skilled" (different user on the same device attempting to imitate the legitimate one) impostor scenarios are considered. The results achieved by the participants show the feasibility of user authentication through behavioral biometrics, although this proves to be a non-trivial challenge. MobileB2C will be established as an on-going competition.
Self-Supervised Vision Transformers for Malware Detection
Aug 15, 2022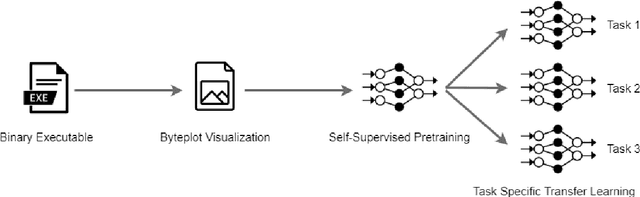
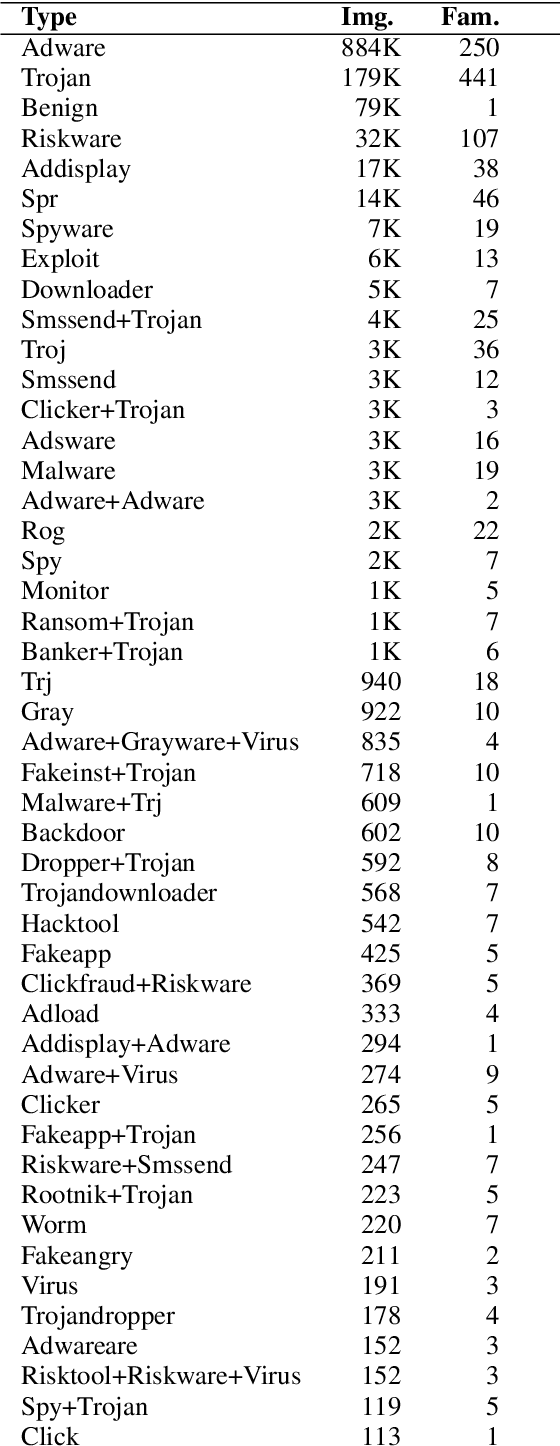
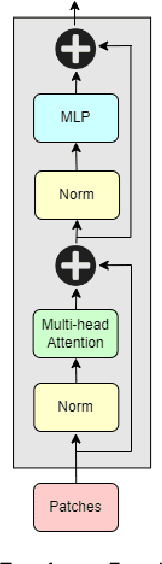

Malware detection plays a crucial role in cyber-security with the increase in malware growth and advancements in cyber-attacks. Previously unseen malware which is not determined by security vendors are often used in these attacks and it is becoming inevitable to find a solution that can self-learn from unlabeled sample data. This paper presents SHERLOCK, a self-supervision based deep learning model to detect malware based on the Vision Transformer (ViT) architecture. SHERLOCK is a novel malware detection method which learns unique features to differentiate malware from benign programs with the use of image-based binary representation. Experimental results using 1.2 million Android applications across a hierarchy of 47 types and 696 families, shows that self-supervised learning can achieve an accuracy of 97% for the binary classification of malware which is higher than existing state-of-the-art techniques. Our proposed model is also able to outperform state-of-the-art techniques for multi-class malware classification of types and family with macro-F1 score of .497 and .491 respectively.