 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Test: Auditing Training Data in Object Classification Models
Jan 19, 2026In this research, we analyze the performance of Membership Inference Tests (MINT), focusing on determining whether given data were utilized during the training phase, specifically in the domain of object recognition. Within the area of object recognition, we propose and develop architectures tailored for MINT models. These architectures aim to optimize performance and efficiency in data utilization, offering a tailored solution to tackle the complexities inherent in the object recognition domain. We conducted experiments involving an object detection model, an embedding extractor, and a MINT module. These experiments were performed in three public databases, totaling over 174K images. The proposed architecture leverages convolutional layers to capture and model the activation patterns present in the data during the training process. Through our analysis, we are able to identify given data used for testing and training, achieving precision rates ranging between 70% and 80%, contingent upon the depth of the detection module layer chosen for input to the MINT module. Additionally, our studies entail an analysis of the factors influencing the MINT Module, delving into the contributing elements behind more transparent training processes.
Active Membership Inference Test (aMINT): Enhancing Model Auditability with Multi-Task Learning
Sep 09, 2025Active Membership Inference Test (aMINT) is a method designed to detect whether given data were used during the training of machine learning models. In Active MINT, we propose a novel multitask learning process that involves training simultaneously two models: the original or Audited Model, and a secondary model, referred to as the MINT Model, responsible for identifying the data used for training the Audited Model. This novel multi-task learning approach has been designed to incorporate the auditability of the model as an optimization objective during the training process of neural networks. The proposed approach incorporates intermediate activation maps as inputs to the MINT layers, which are trained to enhance the detection of training data. We present results using a wide range of neural networks, from lighter architectures such as MobileNet to more complex ones such as Vision Transformers, evaluated in 5 public benchmarks. Our proposed Active MINT achieves over 80% accuracy in detecting if given data was used for training, significantly outperforming previous approaches in the literature. Our aMINT and related methodological developments contribute to increasing transparency in AI models, facilitating stronger safeguards in AI deployments to achieve proper security, privacy, and copyright protection.
Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos
Aug 01, 2025



Photorealistic talking-head avatars are becoming increasingly common in virtual meetings, gaming, and social platforms. These avatars allow for more immersive communication, but they also introduce serious security risks. One emerging threat is impersonation: an attacker can steal a user's avatar-preserving their appearance and voice-making it nearly impossible to detect its fraudulent usage by sight or sound alone. In this paper, we explore the challenge of biometric verification in such avatar-mediated scenarios. Our main question is whether an individual's facial motion patterns can serve as reliable behavioral biometrics to verify their identity when the avatar's visual appearance is a facsimile of its owner. To answer this question, we introduce a new dataset of realistic avatar videos created using a state-of-the-art one-shot avatar generation model, GAGAvatar, with genuine and impostor avatar videos. We also propose a lightweight, explainable spatio-temporal Graph Convolutional Network architecture with temporal attention pooling, that uses only facial landmarks to model dynamic facial gestures. Experimental results demonstrate that facial motion cues enable meaningful identity verification with AUC values approaching 80%. The proposed benchmark and biometric system are available for the research community in order to bring attention to the urgent need for more advanced behavioral biometric defenses in avatar-based communication systems.
Addressing Bias in LLMs: Strategies and Application to Fair AI-based Recruitment
Jun 13, 2025The use of language technologies in high-stake settings is increasing in recent years, mostly motivated by the success of Large Language Models (LLMs). However, despite the great performance of LLMs, they are are susceptible to ethical concerns, such as demographic biases, accountability, or privacy. This work seeks to analyze the capacity of Transformers-based systems to learn demographic biases present in the data, using a case study on AI-based automated recruitment. We propose a privacy-enhancing framework to reduce gender information from the learning pipeline as a way to mitigate biased behaviors in the final tools. Our experiments analyze the influence of data biases on systems built on two different LLMs, and how the proposed framework effectively prevents trained systems from reproducing the bias in the data.
Balancing Tails when Comparing Distributions: Comprehensive Equity Index (CEI) with Application to Bias Evaluation in Operational Face Biometrics
Jun 12, 2025Demographic bias in high-performance face recognition (FR) systems often eludes detection by existing metrics, especially with respect to subtle disparities in the tails of the score distribution. We introduce the Comprehensive Equity Index (CEI), a novel metric designed to address this limitation. CEI uniquely analyzes genuine and impostor score distributions separately, enabling a configurable focus on tail probabilities while also considering overall distribution shapes. Our extensive experiments (evaluating state-of-the-art FR systems, intentionally biased models, and diverse datasets) confirm CEI's superior ability to detect nuanced biases where previous methods fall short. Furthermore, we present CEI^A, an automated version of the metric that enhances objectivity and simplifies practical application. CEI provides a robust and sensitive tool for operational FR fairness assessment. The proposed methods have been developed particularly for bias evaluation in face biometrics but, in general, they are applicable for comparing statistical distributions in any problem where one is interested in analyzing the distribution tails.
Comparison of Visual Trackers for Biomechanical Analysis of Running
May 07, 2025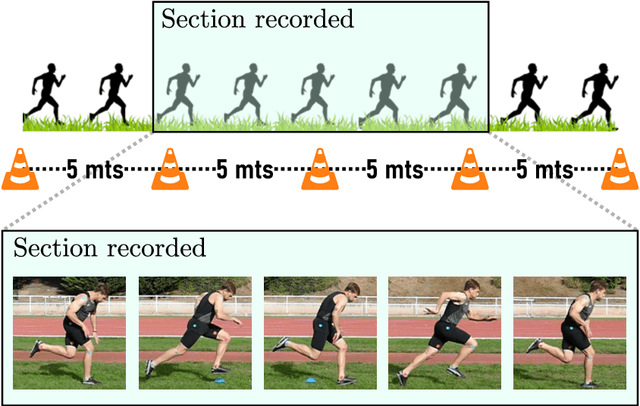
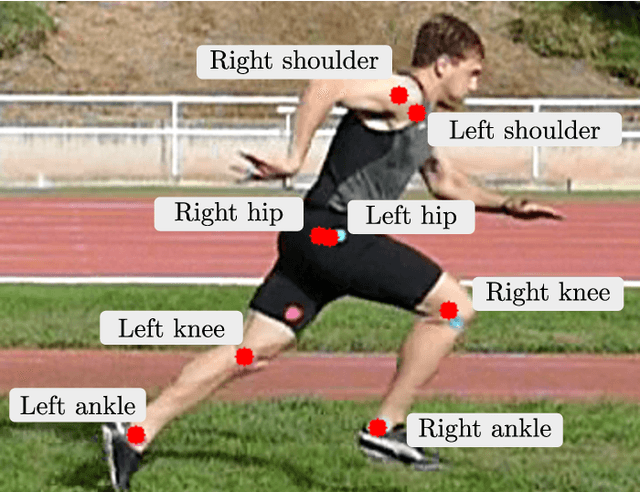

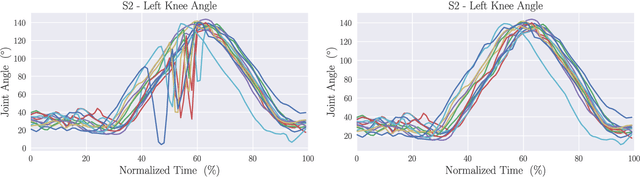
Human pose estimation has witnessed significant advancements in recent years, mainly due to the integration of deep learning models, the availability of a vast amount of data, and large computational resources. These developments have led to highly accurate body tracking systems, which have direct applications in sports analysis and performance evaluation. This work analyzes the performance of six trackers: two point trackers and four joint trackers for biomechanical analysis in sprints. The proposed framework compares the results obtained from these pose trackers with the manual annotations of biomechanical experts for more than 5870 frames. The experimental framework employs forty sprints from five professional runners, focusing on three key angles in sprint biomechanics: trunk inclination, hip flex extension, and knee flex extension. We propose a post-processing module for outlier detection and fusion prediction in the joint angles. The experimental results demonstrate that using joint-based models yields root mean squared errors ranging from 11.41{\deg} to 4.37{\deg}. When integrated with the post-processing modules, these errors can be reduced to 6.99{\deg} and 3.88{\deg}, respectively. The experimental findings suggest that human pose tracking approaches can be valuable resources for the biomechanical analysis of running. However, there is still room for improvement in applications where high accuracy is required.
Exploiting Multiple Representations: 3D Face Biometrics Fusion with Application to Surveillance
Apr 26, 2025



3D face reconstruction (3DFR) algorithms are based on specific assumptions tailored to the limits and characteristics of the different application scenarios. In this study, we investigate how multiple state-of-the-art 3DFR algorithms can be used to generate a better representation of subjects, with the final goal of improving the performance of face recognition systems in challenging uncontrolled scenarios. We also explore how different parametric and non-parametric score-level fusion methods can exploit the unique strengths of multiple 3DFR algorithms to enhance biometric recognition robustness. With this goal, we propose a comprehensive analysis of several face recognition systems across diverse conditions, such as varying distances and camera setups, intra-dataset and cross-dataset, to assess the robustness of the proposed ensemble method. The results demonstrate that the distinct information provided by different 3DFR algorithms can alleviate the problem of generalizing over multiple application scenarios. In addition, the present study highlights the potential of advanced fusion strategies to enhance the reliability of 3DFR-based face recognition systems, providing the research community with key insights to exploit them in real-world applications effectively. Although the experiments are carried out in a specific face verification setup, our proposed fusion-based 3DFR methods may be applied to other tasks around face biometrics that are not strictly related to identity recognition.
Exploring a Patch-Wise Approach for Privacy-Preserving Fake ID Detection
Apr 10, 2025In an increasingly digitalized world, verifying the authenticity of ID documents has become a critical challenge for real-life applications such as digital banking, crypto-exchanges, renting, etc. This study focuses on the topic of fake ID detection, covering several limitations in the field. In particular, no publicly available data from real ID documents exists, and most studies rely on proprietary in-house databases that are not available due to privacy reasons. In order to shed some light on this critical challenge that makes difficult to advance in the field, we explore a trade-off between privacy (i.e., amount of sensitive data available) and performance, proposing a novel patch-wise approach for privacy-preserving fake ID detection. Our proposed approach explores how privacy can be enhanced through: i) two levels of anonymization for an ID document (i.e., fully- and pseudo-anonymized), and ii) different patch size configurations, varying the amount of sensitive data visible in the patch image. Also, state-of-the-art methods such as Vision Transformers and Foundation Models are considered in the analysis. The experimental framework shows that, on an unseen database (DLC-2021), our proposal achieves 13.91% and 0% EERs at patch and ID document level, showing a good generalization to other databases. In addition to this exploration, another key contribution of our study is the release of the first publicly available database that contains 48,400 patches from both real and fake ID documents, along with the experimental framework and models, which will be available in our GitHub.
Are Vision-Language Models Ready for Dietary Assessment? Exploring the Next Frontier in AI-Powered Food Image Recognition
Apr 09, 2025Automatic dietary assessment based on food images remains a challenge, requiring precise food detection, segmentation, and classification. Vision-Language Models (VLMs) offer new possibilities by integrating visual and textual reasoning. In this study, we evaluate six state-of-the-art VLMs (ChatGPT, Gemini, Claude, Moondream, DeepSeek, and LLaVA), analyzing their capabilities in food recognition at different levels. For the experimental framework, we introduce the FoodNExTDB, a unique food image database that contains 9,263 expert-labeled images across 10 categories (e.g., "protein source"), 62 subcategories (e.g., "poultry"), and 9 cooking styles (e.g., "grilled"). In total, FoodNExTDB includes 50k nutritional labels generated by seven experts who manually annotated all images in the database. Also, we propose a novel evaluation metric, Expert-Weighted Recall (EWR), that accounts for the inter-annotator variability. Results show that closed-source models outperform open-source ones, achieving over 90% EWR in recognizing food products in images containing a single product. Despite their potential, current VLMs face challenges in fine-grained food recognition, particularly in distinguishing subtle differences in cooking styles and visually similar food items, which limits their reliability for automatic dietary assessment. The FoodNExTDB database is publicly available at https://github.com/AI4Food/FoodNExtDB.
MINT-Demo: Membership Inference Test Demonstrator
Mar 11, 2025



We present the Membership Inference Test Demonstrator, to emphasize the need for more transparent machine learning training processes. MINT is a technique for experimentally determining whether certain data has been used during the training of machine learning models. We conduct experiments with popular face recognition models and 5 public databases containing over 22M images. Promising results, up to 89% accuracy are achieved, suggesting that it is possible to recognize if an AI model has been trained with specific data. Finally, we present a MINT platform as demonstrator of this technology aimed to promote transparency in AI training.