 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Visual Realism Enough? Evaluating Gait Biometric Fidelity in Generative AI Human Animation
Dec 22, 2025

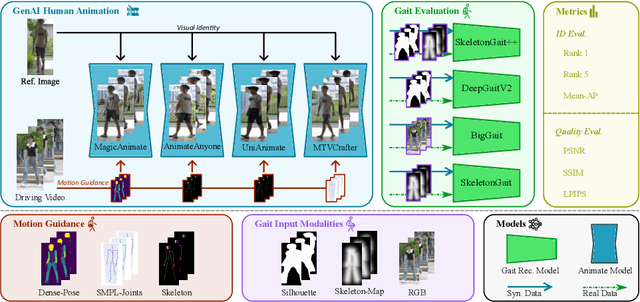
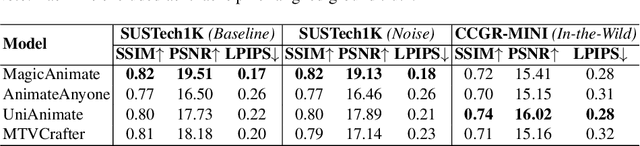
Generative AI (GenAI) models have revolutionized animation, enabling the synthesis of humans and motion patterns with remarkable visual fidelity. However, generating truly realistic human animation remains a formidable challenge, where even minor inconsistencies can make a subject appear unnatural. This limitation is particularly critical when AI-generated videos are evaluated for behavioral biometrics, where subtle motion cues that define identity are easily lost or distorted. The present study investigates whether state-of-the-art GenAI human animation models can preserve the subtle spatio-temporal details needed for person identification through gait biometrics. Specifically, we evaluate four different GenAI models across two primary evaluation tasks to assess their ability to i) restore gait patterns from reference videos under varying conditions of complexity, and ii) transfer these gait patterns to different visual identities. Our results show that while visual quality is mostly high, biometric fidelity remains low in tasks focusing on identification, suggesting that current GenAI models struggle to disentangle identity from motion. Furthermore, through an identity transfer task, we expose a fundamental flaw in appearance-based gait recognition: when texture is disentangled from motion, identification collapses, proving current GenAI models rely on visual attributes rather than temporal dynamics.
KVC-onGoing: Keystroke Verification Challenge
Dec 29, 2024



This article presents the Keystroke Verification Challenge - onGoing (KVC-onGoing), on which researchers can easily benchmark their systems in a common platform using large-scale public databases, the Aalto University Keystroke databases, and a standard experimental protocol. The keystroke data consist of tweet-long sequences of variable transcript text from over 185,000 subjects, acquired through desktop and mobile keyboards simulating real-life conditions. The results on the evaluation set of KVC-onGoing have proved the high discriminative power of keystroke dynamics, reaching values as low as 3.33% of Equal Error Rate (EER) and 11.96% of False Non-Match Rate (FNMR) @1% False Match Rate (FMR) in the desktop scenario, and 3.61% of EER and 17.44% of FNMR @1% at FMR in the mobile scenario, significantly improving previous state-of-the-art results. Concerning demographic fairness, the analyzed scores reflect the subjects' age and gender to various extents, not negligible in a few cases. The framework runs on CodaLab.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
From Pixels to Words: Leveraging Explainability in Face Recognition through Interactive Natural Language Processing
Sep 24, 2024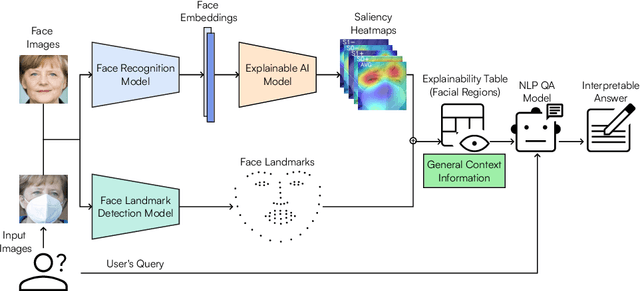
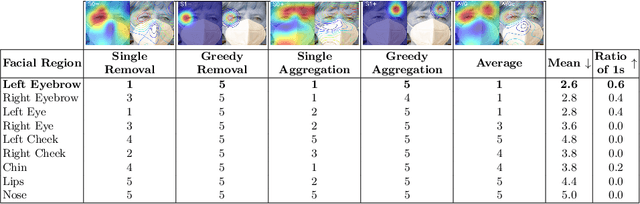
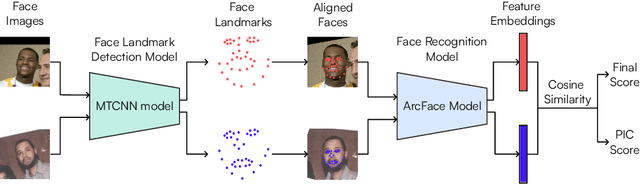

Face Recognition (FR) has advanced significantly with the development of deep learning, achieving high accuracy in several applications. However, the lack of interpretability of these systems raises concerns about their accountability, fairness, and reliability. In the present study, we propose an interactive framework to enhance the explainability of FR models by combining model-agnostic Explainable Artificial Intelligence (XAI) and Natural Language Processing (NLP) techniques. The proposed framework is able to accurately answer various questions of the user through an interactive chatbot. In particular, the explanations generated by our proposed method are in the form of natural language text and visual representations, which for example can describe how different facial regions contribute to the similarity measure between two faces. This is achieved through the automatic analysis of the output's saliency heatmaps of the face images and a BERT question-answering model, providing users with an interface that facilitates a comprehensive understanding of the FR decisions. The proposed approach is interactive, allowing the users to ask questions to get more precise information based on the user's background knowledge. More importantly, in contrast to previous studies, our solution does not decrease the face recognition performance. We demonstrate the effectiveness of the method through different experiments, highlighting its potential to make FR systems more interpretable and user-friendly, especially in sensitive applications where decision-making transparency is crucial.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
IEEE BigData 2023 Keystroke Verification Challenge (KVC)
Jan 29, 2024This paper describes the results of the IEEE BigData 2023 Keystroke Verification Challenge (KVC), that considers the biometric verification performance of Keystroke Dynamics (KD), captured as tweet-long sequences of variable transcript text from over 185,000 subjects. The data are obtained from two of the largest public databases of KD up to date, the Aalto Desktop and Mobile Keystroke Databases, guaranteeing a minimum amount of data per subject, age and gender annotations, absence of corrupted data, and avoiding excessively unbalanced subject distributions with respect to the considered demographic attributes. Several neural architectures were proposed by the participants, leading to global Equal Error Rates (EERs) as low as 3.33% and 3.61% achieved by the best team respectively in the desktop and mobile scenario, outperforming the current state of the art biometric verification performance for KD. Hosted on CodaLab, the KVC will be made ongoing to represent a useful tool for the research community to compare different approaches under the same experimental conditions and to deepen the knowledge of the field.
How Good is ChatGPT at Face Biometrics? A First Look into Recognition, Soft Biometrics, and Explainability
Jan 24, 2024Large Language Models (LLMs) such as GPT developed by OpenAI, have already shown astonishing results, introducing quick changes in our society. This has been intensified by the release of ChatGPT which allows anyone to interact in a simple conversational way with LLMs, without any experience in the field needed. As a result, ChatGPT has been rapidly applied to many different tasks such as code- and song-writer, education, virtual assistants, etc., showing impressive results for tasks for which it was not trained (zero-shot learning). The present study aims to explore the ability of ChatGPT, based on the recent GPT-4 multimodal LLM, for the task of face biometrics. In particular, we analyze the ability of ChatGPT to perform tasks such as face verification, soft-biometrics estimation, and explainability of the results. ChatGPT could be very valuable to further increase the explainability and transparency of the automatic decisions in human scenarios. Experiments are carried out in order to evaluate the performance and robustness of ChatGPT, using popular public benchmarks and comparing the results with state-of-the-art methods in the field. The results achieved in this study show the potential of LLMs such as ChatGPT for face biometrics, especially to enhance explainability. For reproducibility reasons, we release all the code in GitHub.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.