 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Words: Leveraging Explainability in Face Recognition through Interactive Natural Language Processing
Sep 24, 2024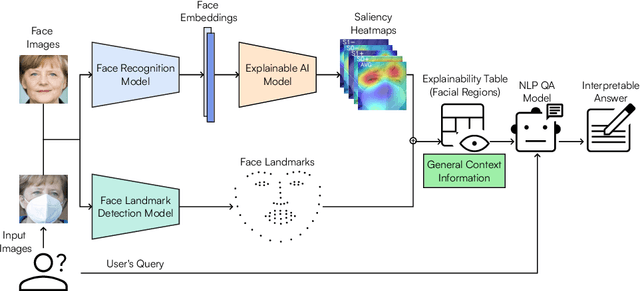
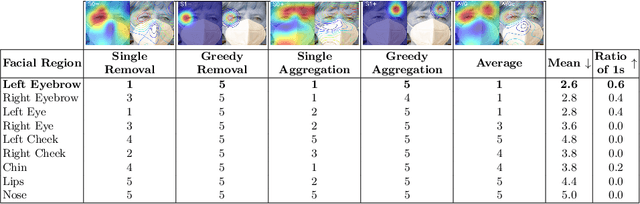
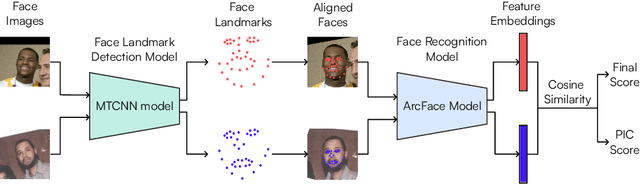

Face Recognition (FR) has advanced significantly with the development of deep learning, achieving high accuracy in several applications. However, the lack of interpretability of these systems raises concerns about their accountability, fairness, and reliability. In the present study, we propose an interactive framework to enhance the explainability of FR models by combining model-agnostic Explainable Artificial Intelligence (XAI) and Natural Language Processing (NLP) techniques. The proposed framework is able to accurately answer various questions of the user through an interactive chatbot. In particular, the explanations generated by our proposed method are in the form of natural language text and visual representations, which for example can describe how different facial regions contribute to the similarity measure between two faces. This is achieved through the automatic analysis of the output's saliency heatmaps of the face images and a BERT question-answering model, providing users with an interface that facilitates a comprehensive understanding of the FR decisions. The proposed approach is interactive, allowing the users to ask questions to get more precise information based on the user's background knowledge. More importantly, in contrast to previous studies, our solution does not decrease the face recognition performance. We demonstrate the effectiveness of the method through different experiments, highlighting its potential to make FR systems more interpretable and user-friendly, especially in sensitive applications where decision-making transparency is crucial.
Probing the Efficacy of Federated Parameter-Efficient Fine-Tuning of Vision Transformers for Medical Image Classification
Jul 16, 2024



With the advent of large pre-trained transformer models, fine-tuning these models for various downstream tasks is a critical problem. Paucity of training data, the existence of data silos, and stringent privacy constraints exacerbate this fine-tuning problem in the medical imaging domain, creating a strong need for algorithms that enable collaborative fine-tuning of pre-trained models. Moreover, the large size of these models necessitates the use of parameter-efficient fine-tuning (PEFT) to reduce the communication burden in federated learning. In this work, we systematically investigate various federated PEFT strategies for adapting a Vision Transformer (ViT) model (pre-trained on a large natural image dataset) for medical image classification. Apart from evaluating known PEFT techniques, we introduce new federated variants of PEFT algorithms such as visual prompt tuning (VPT), low-rank decomposition of visual prompts, stochastic block attention fine-tuning, and hybrid PEFT methods like low-rank adaptation (LoRA)+VPT. Moreover, we perform a thorough empirical analysis to identify the optimal PEFT method for the federated setting and understand the impact of data distribution on federated PEFT, especially for out-of-domain (OOD) and non-IID data. The key insight of this study is that while most federated PEFT methods work well for in-domain transfer, there is a substantial accuracy vs. efficiency trade-off when dealing with OOD and non-IID scenarios, which is commonly the case in medical imaging. Specifically, every order of magnitude reduction in fine-tuned/exchanged parameters can lead to a 4% drop in accuracy. Thus, the initial model choice is crucial for federated PEFT. It is preferable to use medical foundation models learned from in-domain medical image data (if available) rather than general vision models.
EVOKE: Emotion Enabled Virtual Avatar Mapping Using Optimized Knowledge Distillation
Jan 13, 2024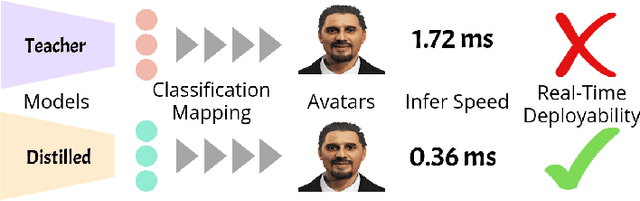
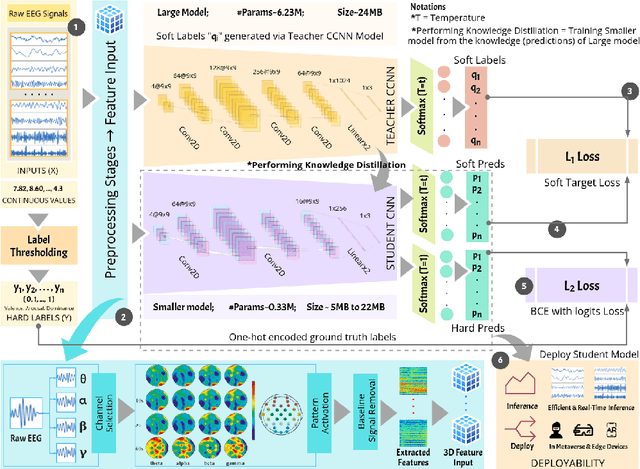
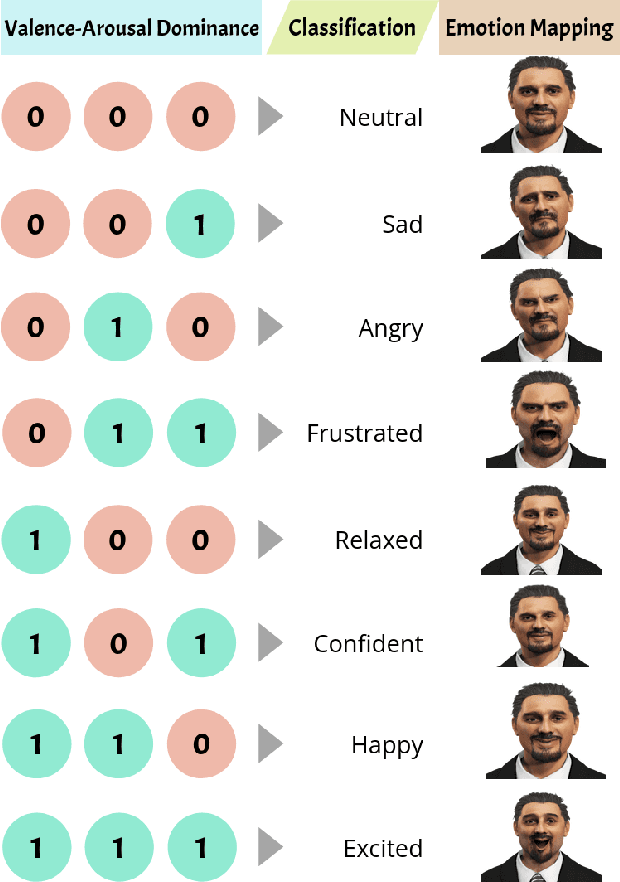
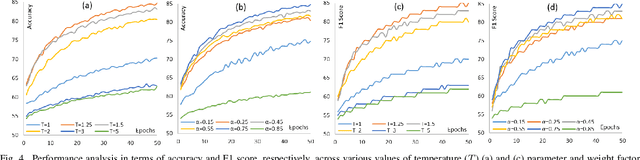
As virtual environments continue to advance, the demand for immersive and emotionally engaging experiences has grown. Addressing this demand, we introduce Emotion enabled Virtual avatar mapping using Optimized KnowledgE distillation (EVOKE), a lightweight emotion recognition framework designed for the seamless integration of emotion recognition into 3D avatars within virtual environments. Our approach leverages knowledge distillation involving multi-label classification on the publicly available DEAP dataset, which covers valence, arousal, and dominance as primary emotional classes. Remarkably, our distilled model, a CNN with only two convolutional layers and 18 times fewer parameters than the teacher model, achieves competitive results, boasting an accuracy of 87% while demanding far less computational resources. This equilibrium between performance and deployability positions our framework as an ideal choice for virtual environment systems. Furthermore, the multi-label classification outcomes are utilized to map emotions onto custom-designed 3D avatars.