 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Efficacy of Federated Parameter-Efficient Fine-Tuning of Vision Transformers for Medical Image Classification
Jul 16, 2024



With the advent of large pre-trained transformer models, fine-tuning these models for various downstream tasks is a critical problem. Paucity of training data, the existence of data silos, and stringent privacy constraints exacerbate this fine-tuning problem in the medical imaging domain, creating a strong need for algorithms that enable collaborative fine-tuning of pre-trained models. Moreover, the large size of these models necessitates the use of parameter-efficient fine-tuning (PEFT) to reduce the communication burden in federated learning. In this work, we systematically investigate various federated PEFT strategies for adapting a Vision Transformer (ViT) model (pre-trained on a large natural image dataset) for medical image classification. Apart from evaluating known PEFT techniques, we introduce new federated variants of PEFT algorithms such as visual prompt tuning (VPT), low-rank decomposition of visual prompts, stochastic block attention fine-tuning, and hybrid PEFT methods like low-rank adaptation (LoRA)+VPT. Moreover, we perform a thorough empirical analysis to identify the optimal PEFT method for the federated setting and understand the impact of data distribution on federated PEFT, especially for out-of-domain (OOD) and non-IID data. The key insight of this study is that while most federated PEFT methods work well for in-domain transfer, there is a substantial accuracy vs. efficiency trade-off when dealing with OOD and non-IID scenarios, which is commonly the case in medical imaging. Specifically, every order of magnitude reduction in fine-tuned/exchanged parameters can lead to a 4% drop in accuracy. Thus, the initial model choice is crucial for federated PEFT. It is preferable to use medical foundation models learned from in-domain medical image data (if available) rather than general vision models.
FedSIS: Federated Split Learning with Intermediate Representation Sampling for Privacy-preserving Generalized Face Presentation Attack Detection
Aug 22, 2023



Lack of generalization to unseen domains/attacks is the Achilles heel of most face presentation attack detection (FacePAD) algorithms. Existing attempts to enhance the generalizability of FacePAD solutions assume that data from multiple source domains are available with a single entity to enable centralized training. In practice, data from different source domains may be collected by diverse entities, who are often unable to share their data due to legal and privacy constraints. While collaborative learning paradigms such as federated learning (FL) can overcome this problem, standard FL methods are ill-suited for domain generalization because they struggle to surmount the twin challenges of handling non-iid client data distributions during training and generalizing to unseen domains during inference. In this work, a novel framework called Federated Split learning with Intermediate representation Sampling (FedSIS) is introduced for privacy-preserving domain generalization. In FedSIS, a hybrid Vision Transformer (ViT) architecture is learned using a combination of FL and split learning to achieve robustness against statistical heterogeneity in the client data distributions without any sharing of raw data (thereby preserving privacy). To further improve generalization to unseen domains, a novel feature augmentation strategy called intermediate representation sampling is employed, and discriminative information from intermediate blocks of a ViT is distilled using a shared adapter network. The FedSIS approach has been evaluated on two well-known benchmarks for cross-domain FacePAD to demonstrate that it is possible to achieve state-of-the-art generalization performance without data sharing. Code: https://github.com/Naiftt/FedSIS
FeSViBS: Federated Split Learning of Vision Transformer with Block Sampling
Jun 26, 2023


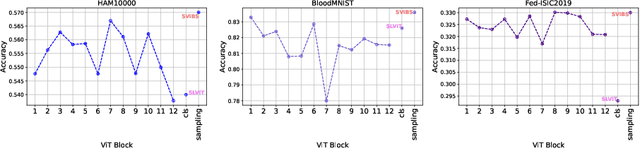
Data scarcity is a significant obstacle hindering the learning of powerful machine learning models in critical healthcare applications. Data-sharing mechanisms among multiple entities (e.g., hospitals) can accelerate model training and yield more accurate predictions. Recently, approaches such as Federated Learning (FL) and Split Learning (SL) have facilitated collaboration without the need to exchange private data. In this work, we propose a framework for medical imaging classification tasks called Federated Split learning of Vision transformer with Block Sampling (FeSViBS). The FeSViBS framework builds upon the existing federated split vision transformer and introduces a block sampling module, which leverages intermediate features extracted by the Vision Transformer (ViT) at the server. This is achieved by sampling features (patch tokens) from an intermediate transformer block and distilling their information content into a pseudo class token before passing them back to the client. These pseudo class tokens serve as an effective feature augmentation strategy and enhances the generalizability of the learned model. We demonstrate the utility of our proposed method compared to other SL and FL approaches on three publicly available medical imaging datasets: HAM1000, BloodMNIST, and Fed-ISIC2019, under both IID and non-IID settings. Code: https://github.com/faresmalik/FeSViBS
Self-Ensembling Vision Transformer (SEViT) for Robust Medical Image Classification
Aug 04, 2022



Vision Transformers (ViT) are competing to replace Convolutional Neural Networks (CNN) for various computer vision tasks in medical imaging such as classification and segmentation. While the vulnerability of CNNs to adversarial attacks is a well-known problem, recent works have shown that ViTs are also susceptible to such attacks and suffer significant performance degradation under attack. The vulnerability of ViTs to carefully engineered adversarial samples raises serious concerns about their safety in clinical settings. In this paper, we propose a novel self-ensembling method to enhance the robustness of ViT in the presence of adversarial attacks. The proposed Self-Ensembling Vision Transformer (SEViT) leverages the fact that feature representations learned by initial blocks of a ViT are relatively unaffected by adversarial perturbations. Learning multiple classifiers based on these intermediate feature representations and combining these predictions with that of the final ViT classifier can provide robustness against adversarial attacks. Measuring the consistency between the various predictions can also help detect adversarial samples. Experiments on two modalities (chest X-ray and fundoscopy) demonstrate the efficacy of SEViT architecture to defend against various adversarial attacks in the gray-box (attacker has full knowledge of the target model, but not the defense mechanism) setting. Code: https://github.com/faresmalik/SEViT