 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models
Aug 29, 2024The rapid proliferation of large-scale text-to-image generation (T2IG) models has led to concerns about their potential misuse in generating harmful content. Though many methods have been proposed for erasing undesired concepts from T2IG models, they only provide a false sense of security, as recent works demonstrate that concept-erased models (CEMs) can be easily deceived to generate the erased concept through adversarial attacks. The problem of adversarially robust concept erasing without significant degradation to model utility (ability to generate benign concepts) remains an unresolved challenge, especially in the white-box setting where the adversary has access to the CEM. To address this gap, we propose an approach called STEREO that involves two distinct stages. The first stage searches thoroughly enough for strong and diverse adversarial prompts that can regenerate an erased concept from a CEM, by leveraging robust optimization principles from adversarial training. In the second robustly erase once stage, we introduce an anchor-concept-based compositional objective to robustly erase the target concept at one go, while attempting to minimize the degradation on model utility. By benchmarking the proposed STEREO approach against four state-of-the-art concept erasure methods under three adversarial attacks, we demonstrate its ability to achieve a better robustness vs. utility trade-off. Our code and models are available at https://github.com/koushiksrivats/robust-concept-erasing.
FLIP: Cross-domain Face Anti-spoofing with Language Guidance
Sep 28, 2023



Face anti-spoofing (FAS) or presentation attack detection is an essential component of face recognition systems deployed in security-critical applications. Existing FAS methods have poor generalizability to unseen spoof types, camera sensors, and environmental conditions. Recently, vision transformer (ViT) models have been shown to be effective for the FAS task due to their ability to capture long-range dependencies among image patches. However, adaptive modules or auxiliary loss functions are often required to adapt pre-trained ViT weights learned on large-scale datasets such as ImageNet. In this work, we first show that initializing ViTs with multimodal (e.g., CLIP) pre-trained weights improves generalizability for the FAS task, which is in line with the zero-shot transfer capabilities of vision-language pre-trained (VLP) models. We then propose a novel approach for robust cross-domain FAS by grounding visual representations with the help of natural language. Specifically, we show that aligning the image representation with an ensemble of class descriptions (based on natural language semantics) improves FAS generalizability in low-data regimes. Finally, we propose a multimodal contrastive learning strategy to boost feature generalization further and bridge the gap between source and target domains. Extensive experiments on three standard protocols demonstrate that our method significantly outperforms the state-of-the-art methods, achieving better zero-shot transfer performance than five-shot transfer of adaptive ViTs. Code: https://github.com/koushiksrivats/FLIP
FedSIS: Federated Split Learning with Intermediate Representation Sampling for Privacy-preserving Generalized Face Presentation Attack Detection
Aug 22, 2023



Lack of generalization to unseen domains/attacks is the Achilles heel of most face presentation attack detection (FacePAD) algorithms. Existing attempts to enhance the generalizability of FacePAD solutions assume that data from multiple source domains are available with a single entity to enable centralized training. In practice, data from different source domains may be collected by diverse entities, who are often unable to share their data due to legal and privacy constraints. While collaborative learning paradigms such as federated learning (FL) can overcome this problem, standard FL methods are ill-suited for domain generalization because they struggle to surmount the twin challenges of handling non-iid client data distributions during training and generalizing to unseen domains during inference. In this work, a novel framework called Federated Split learning with Intermediate representation Sampling (FedSIS) is introduced for privacy-preserving domain generalization. In FedSIS, a hybrid Vision Transformer (ViT) architecture is learned using a combination of FL and split learning to achieve robustness against statistical heterogeneity in the client data distributions without any sharing of raw data (thereby preserving privacy). To further improve generalization to unseen domains, a novel feature augmentation strategy called intermediate representation sampling is employed, and discriminative information from intermediate blocks of a ViT is distilled using a shared adapter network. The FedSIS approach has been evaluated on two well-known benchmarks for cross-domain FacePAD to demonstrate that it is possible to achieve state-of-the-art generalization performance without data sharing. Code: https://github.com/Naiftt/FedSIS
Evading Forensic Classifiers with Attribute-Conditioned Adversarial Faces
Jun 22, 2023The ability of generative models to produce highly realistic synthetic face images has raised security and ethical concerns. As a first line of defense against such fake faces, deep learning based forensic classifiers have been developed. While these forensic models can detect whether a face image is synthetic or real with high accuracy, they are also vulnerable to adversarial attacks. Although such attacks can be highly successful in evading detection by forensic classifiers, they introduce visible noise patterns that are detectable through careful human scrutiny. Additionally, these attacks assume access to the target model(s) which may not always be true. Attempts have been made to directly perturb the latent space of GANs to produce adversarial fake faces that can circumvent forensic classifiers. In this work, we go one step further and show that it is possible to successfully generate adversarial fake faces with a specified set of attributes (e.g., hair color, eye size, race, gender, etc.). To achieve this goal, we leverage the state-of-the-art generative model StyleGAN with disentangled representations, which enables a range of modifications without leaving the manifold of natural images. We propose a framework to search for adversarial latent codes within the feature space of StyleGAN, where the search can be guided either by a text prompt or a reference image. We also propose a meta-learning based optimization strategy to achieve transferable performance on unknown target models. Extensive experiments demonstrate that the proposed approach can produce semantically manipulated adversarial fake faces, which are true to the specified attribute set and can successfully fool forensic face classifiers, while remaining undetectable by humans. Code: https://github.com/koushiksrivats/face_attribute_attack.
DEXTER: An end-to-end system to extract table contents from electronic medical health documents
Jul 18, 2022

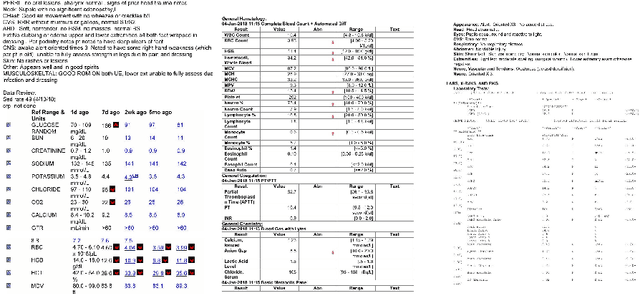

In this paper, we propose DEXTER, an end to end system to extract information from tables present in medical health documents, such as electronic health records (EHR) and explanation of benefits (EOB). DEXTER consists of four sub-system stages: i) table detection ii) table type classification iii) cell detection; and iv) cell content extraction. We propose a two-stage transfer learning-based approach using CDeC-Net architecture along with Non-Maximal suppression for table detection. We design a conventional computer vision-based approach for table type classification and cell detection using parameterized kernels based on image size for detecting rows and columns. Finally, we extract the text from the detected cells using pre-existing OCR engine Tessaract. To evaluate our system, we manually annotated a sample of the real-world medical dataset (referred to as Meddata) consisting of wide variations of documents (in terms of appearance) covering different table structures, such as bordered, partially bordered, borderless, or coloured tables. We experimentally show that DEXTER outperforms the commercially available Amazon Textract and Microsoft Azure Form Recognizer systems on the annotated real-world medical dataset