 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
May 18, 2026Diffusion models have been widely studied for removing unsafe content learned during pre-training. Existing methods require expensive supervised data, either unsafe-text paired with safe-image groundtruth or negative/positive image pairs, making them impractical to scale. Furthermore, offline reinforcement learning and supervised fine-tuning approaches that generate synthetic data offline suffer from catastrophic forgetting, degrading generation quality. We propose a novel online reinforcement learning framework that addresses both data scarcity and model degradation through post-training with Group Relative Policy Optimization (GRPO) on both negative and positive text prompts. To eliminate the need for fine-tuning specialized safe/unsafe reward models, we introduce a \textit{steering reward mechanism} that exploits an inherent property of CLIP embeddings: steering text representations toward positive safety directions and away from negative ones in the embedding space. Our online-policy approach enables the model to learn from diverse prompts, including explicit unsafe content, without catastrophic forgetting. Extensive experiments demonstrate that our method reduces inappropriate content to 18.07\% (vs. 48.9\% for SD v1.4) and nudity detections to 15 (vs. 646 baseline) while improving compositional generation quality from 42.08\% to 47.83\% on GenEval. Remarkably, these safety gains generalize to out-of-domain unsafe prompts across seven harm categories, achieving state-of-the-art performance without supervised paired data or reward tuning. Github: https://github.com/MAXNORM8650/SafeDiffusion-R1.
Towards Calibrating Prompt Tuning of Vision-Language Models
Feb 22, 2026Prompt tuning of large-scale vision-language models such as CLIP enables efficient task adaptation without updating model weights. However, it often leads to poor confidence calibration and unreliable predictive uncertainty. We address this problem by proposing a calibration framework that enhances predictive reliability while preserving the geometry of the pretrained CLIP embedding space, which is required for robust generalization. Our approach extends the standard cross-entropy loss with two complementary regularizers: (1) a mean-variance margin penalty that stabilizes inter-class logit margins by maximizing their average while minimizing dispersion, mitigating underconfidence and overconfidence spikes; and (2) a text moment-matching loss that aligns the first and second moments of tuned text embeddings with their frozen CLIP counterparts, preserving semantic dispersion crucial for generalization. Through extensive experiments across 7 prompt-tuning methods and 11 diverse datasets, we demonstrate that our approach significantly reduces the Expected Calibration Error (ECE) compared to competitive calibration techniques on both base and novel classes
RAVEN: Erasing Invisible Watermarks via Novel View Synthesis
Jan 13, 2026Invisible watermarking has become a critical mechanism for authenticating AI-generated image content, with major platforms deploying watermarking schemes at scale. However, evaluating the vulnerability of these schemes against sophisticated removal attacks remains essential to assess their reliability and guide robust design. In this work, we expose a fundamental vulnerability in invisible watermarks by reformulating watermark removal as a view synthesis problem. Our key insight is that generating a perceptually consistent alternative view of the same semantic content, akin to re-observing a scene from a shifted perspective, naturally removes the embedded watermark while preserving visual fidelity. This reveals a critical gap: watermarks robust to pixel-space and frequency-domain attacks remain vulnerable to semantic-preserving viewpoint transformations. We introduce a zero-shot diffusion-based framework that applies controlled geometric transformations in latent space, augmented with view-guided correspondence attention to maintain structural consistency during reconstruction. Operating on frozen pre-trained models without detector access or watermark knowledge, our method achieves state-of-the-art watermark suppression across 15 watermarking methods--outperforming 14 baseline attacks while maintaining superior perceptual quality across multiple datasets.
Calibration-Aware Prompt Learning for Medical Vision-Language Models
Sep 18, 2025Medical Vision-Language Models (Med-VLMs) have demonstrated remarkable performance across diverse medical imaging tasks by leveraging large-scale image-text pretraining. However, their confidence calibration is largely unexplored, and so remains a significant challenge. As such, miscalibrated predictions can lead to overconfident errors, undermining clinical trust and decision-making reliability. To address this, we introduce CalibPrompt, the first framework to calibrate Med-VLMs during prompt tuning. CalibPrompt optimizes a small set of learnable prompts with carefully designed calibration objectives under scarce labeled data regime. First, we study a regularizer that attempts to align the smoothed accuracy with the predicted model confidences. Second, we introduce an angular separation loss to maximize textual feature proximity toward improving the reliability in confidence estimates of multimodal Med-VLMs. Extensive experiments on four publicly available Med-VLMs and five diverse medical imaging datasets reveal that CalibPrompt consistently improves calibration without drastically affecting clean accuracy. Our code is available at https://github.com/iabh1shekbasu/CalibPrompt.
First-Place Solution to NeurIPS 2024 Invisible Watermark Removal Challenge
Aug 28, 2025Content watermarking is an important tool for the authentication and copyright protection of digital media. However, it is unclear whether existing watermarks are robust against adversarial attacks. We present the winning solution to the NeurIPS 2024 Erasing the Invisible challenge, which stress-tests watermark robustness under varying degrees of adversary knowledge. The challenge consisted of two tracks: a black-box and beige-box track, depending on whether the adversary knows which watermarking method was used by the provider. For the beige-box track, we leverage an adaptive VAE-based evasion attack, with a test-time optimization and color-contrast restoration in CIELAB space to preserve the image's quality. For the black-box track, we first cluster images based on their artifacts in the spatial or frequency-domain. Then, we apply image-to-image diffusion models with controlled noise injection and semantic priors from ChatGPT-generated captions to each cluster with optimized parameter settings. Empirical evaluations demonstrate that our method successfully achieves near-perfect watermark removal (95.7%) with negligible impact on the residual image's quality. We hope that our attacks inspire the development of more robust image watermarking methods.
FaceAnonyMixer: Cancelable Faces via Identity Consistent Latent Space Mixing
Aug 07, 2025Advancements in face recognition (FR) technologies have amplified privacy concerns, necessitating methods that protect identity while maintaining recognition utility. Existing face anonymization methods typically focus on obscuring identity but fail to meet the requirements of biometric template protection, including revocability, unlinkability, and irreversibility. We propose FaceAnonyMixer, a cancelable face generation framework that leverages the latent space of a pre-trained generative model to synthesize privacy-preserving face images. The core idea of FaceAnonyMixer is to irreversibly mix the latent code of a real face image with a synthetic code derived from a revocable key. The mixed latent code is further refined through a carefully designed multi-objective loss to satisfy all cancelable biometric requirements. FaceAnonyMixer is capable of generating high-quality cancelable faces that can be directly matched using existing FR systems without requiring any modifications. Extensive experiments on benchmark datasets demonstrate that FaceAnonyMixer delivers superior recognition accuracy while providing significantly stronger privacy protection, achieving over an 11% gain on commercial API compared to recent cancelable biometric methods. Code is available at: https://github.com/talha-alam/faceanonymixer.
Robust-LLaVA: On the Effectiveness of Large-Scale Robust Image Encoders for Multi-modal Large Language Models
Feb 03, 2025



Multi-modal Large Language Models (MLLMs) excel in vision-language tasks but remain vulnerable to visual adversarial perturbations that can induce hallucinations, manipulate responses, or bypass safety mechanisms. Existing methods seek to mitigate these risks by applying constrained adversarial fine-tuning to CLIP vision encoders on ImageNet-scale data, ensuring their generalization ability is preserved. However, this limited adversarial training restricts robustness and broader generalization. In this work, we explore an alternative approach of leveraging existing vision classification models that have been adversarially pre-trained on large-scale data. Our analysis reveals two principal contributions: (1) the extensive scale and diversity of adversarial pre-training enables these models to demonstrate superior robustness against diverse adversarial threats, ranging from imperceptible perturbations to advanced jailbreaking attempts, without requiring additional adversarial training, and (2) end-to-end MLLM integration with these robust models facilitates enhanced adaptation of language components to robust visual features, outperforming existing plug-and-play methodologies on complex reasoning tasks. Through systematic evaluation across visual question-answering, image captioning, and jail-break attacks, we demonstrate that MLLMs trained with these robust models achieve superior adversarial robustness while maintaining favorable clean performance. Our framework achieves 2x and 1.5x average robustness gains in captioning and VQA tasks, respectively, and delivers over 10% improvement against jailbreak attacks. Code and pretrained models will be available at https://github.com/HashmatShadab/Robust-LLaVA.
PromptSmooth: Certifying Robustness of Medical Vision-Language Models via Prompt Learning
Aug 29, 2024
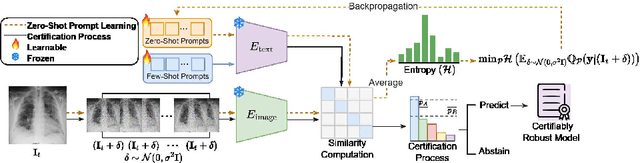
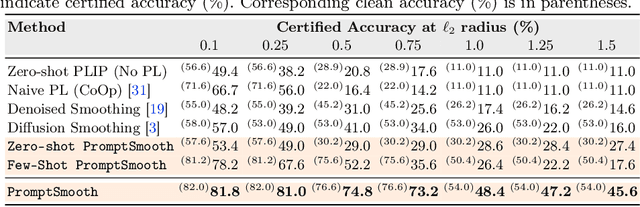
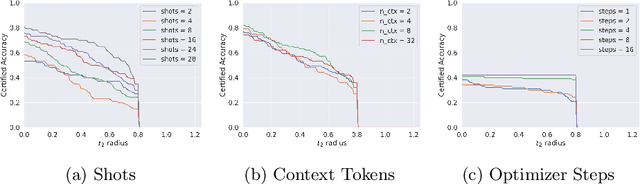
Medical vision-language models (Med-VLMs) trained on large datasets of medical image-text pairs and later fine-tuned for specific tasks have emerged as a mainstream paradigm in medical image analysis. However, recent studies have highlighted the susceptibility of these Med-VLMs to adversarial attacks, raising concerns about their safety and robustness. Randomized smoothing is a well-known technique for turning any classifier into a model that is certifiably robust to adversarial perturbations. However, this approach requires retraining the Med-VLM-based classifier so that it classifies well under Gaussian noise, which is often infeasible in practice. In this paper, we propose a novel framework called PromptSmooth to achieve efficient certified robustness of Med-VLMs by leveraging the concept of prompt learning. Given any pre-trained Med-VLM, PromptSmooth adapts it to handle Gaussian noise by learning textual prompts in a zero-shot or few-shot manner, achieving a delicate balance between accuracy and robustness, while minimizing the computational overhead. Moreover, PromptSmooth requires only a single model to handle multiple noise levels, which substantially reduces the computational cost compared to traditional methods that rely on training a separate model for each noise level. Comprehensive experiments based on three Med-VLMs and across six downstream datasets of various imaging modalities demonstrate the efficacy of PromptSmooth. Our code and models are available at https://github.com/nhussein/promptsmooth.
STEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models
Aug 29, 2024The rapid proliferation of large-scale text-to-image generation (T2IG) models has led to concerns about their potential misuse in generating harmful content. Though many methods have been proposed for erasing undesired concepts from T2IG models, they only provide a false sense of security, as recent works demonstrate that concept-erased models (CEMs) can be easily deceived to generate the erased concept through adversarial attacks. The problem of adversarially robust concept erasing without significant degradation to model utility (ability to generate benign concepts) remains an unresolved challenge, especially in the white-box setting where the adversary has access to the CEM. To address this gap, we propose an approach called STEREO that involves two distinct stages. The first stage searches thoroughly enough for strong and diverse adversarial prompts that can regenerate an erased concept from a CEM, by leveraging robust optimization principles from adversarial training. In the second robustly erase once stage, we introduce an anchor-concept-based compositional objective to robustly erase the target concept at one go, while attempting to minimize the degradation on model utility. By benchmarking the proposed STEREO approach against four state-of-the-art concept erasure methods under three adversarial attacks, we demonstrate its ability to achieve a better robustness vs. utility trade-off. Our code and models are available at https://github.com/koushiksrivats/robust-concept-erasing.
Makeup-Guided Facial Privacy Protection via Untrained Neural Network Priors
Aug 20, 2024

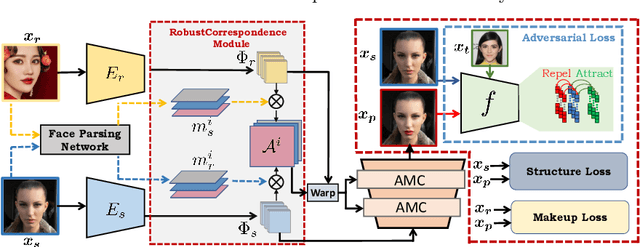
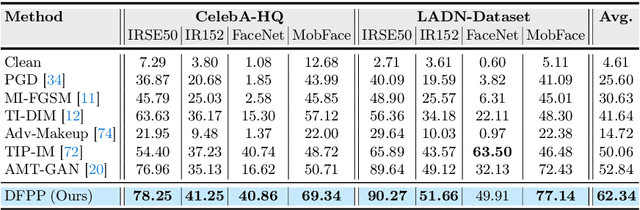
Deep learning-based face recognition (FR) systems pose significant privacy risks by tracking users without their consent. While adversarial attacks can protect privacy, they often produce visible artifacts compromising user experience. To mitigate this issue, recent facial privacy protection approaches advocate embedding adversarial noise into the natural looking makeup styles. However, these methods require training on large-scale makeup datasets that are not always readily available. In addition, these approaches also suffer from dataset bias. For instance, training on makeup data that predominantly contains female faces could compromise protection efficacy for male faces. To handle these issues, we propose a test-time optimization approach that solely optimizes an untrained neural network to transfer makeup style from a reference to a source image in an adversarial manner. We introduce two key modules: a correspondence module that aligns regions between reference and source images in latent space, and a decoder with conditional makeup layers. The untrained decoder, optimized via carefully designed structural and makeup consistency losses, generates a protected image that resembles the source but incorporates adversarial makeup to deceive FR models. As our approach does not rely on training with makeup face datasets, it avoids potential male/female dataset biases while providing effective protection. We further extend the proposed approach to videos by leveraging on temporal correlations. Experiments on benchmark datasets demonstrate superior performance in face verification and identification tasks and effectiveness against commercial FR systems. Our code and models will be available at https://github.com/fahadshamshad/deep-facial-privacy-prior