 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond False Stability: High-Noise Drift Gating for Test-Time Adversarial Defenses in Vision-Language Models
Jun 04, 2026Vision-language models (VLMs) such as CLIP show strong zero-shot generalization but remain highly vulnerable to adversarial attacks. Adversarial training improves robustness but is computationally expensive, motivating test-time defenses. Recent approaches exploit how CLIP's visual representations respond to stochastic perturbations: aggregating predictions across noisy views, constructing Gaussian noise-averaged anchors and interpolating features toward them, or applying counter-perturbations. These strategies improve robustness but often degrade clean accuracy, yielding an unfavorable clean-robust trade-off. We revisit stochastic test-time defenses and identify an underexplored noise-regime transition in CLIP's representation space. Prior work explored perturbations mainly in the weak-noise regime, where adversarial examples can appear unusually stable (false stability). Our analysis shows this reverses as perturbation strength grows: beyond the weak-noise regime, adversarial representations become markedly more unstable than clean ones, giving a clearer separation signal. The transition is consistent across uniform and Gaussian noise, photometric and geometric transforms, datasets, and diverse attacks. It largely disappears in adversarially trained models, suggesting it is tied to the fragile local-basin geometry of adversarial representations in non-robust CLIP. We propose a training-free, plug-in drift-gated mechanism that uses high-noise feature drift as a lightweight gating signal to trigger existing test-time defenses only when adversarial-like instability is detected. Across 13 datasets it consistently improves the clean-robust trade-off. On eight fine-grained datasets, mean clean+adversarial accuracy rises from 65.7% to 71.4% for counterattack defenses and 68.4% to 73.2% for noise-anchoring; on ImageNet and four shifted variants, from 56.1% to 66.2% and 62.1% to 67.6%.
Exploring Adversarial Robustness and Safety Alignment in Multilingual Multi-Modal Large Language Models
Jun 02, 2026Multimodal Large Language Models integrate visual perception into language reasoning, introducing a continuous attack surface susceptible to adversarial attacks. Prior work on MLLM robustness has focused largely on English-centric tasks, leaving multilingual behaviour unexplored. We address this gap through a systematic study of adversarial robustness and multimodal safety across 12 diverse languages, evaluating open-source MLLMs that acquire multilingual capability through instruction tuning. Gradient-based attacks reveal a transferable multilingual vulnerability: adversarial images optimized in one language continue to induce failure in others, demonstrating strong cross-lingual transferability. Multilingual safety further varies with how effectively a model retrieves or interprets harmful instructions. When harmful intent is issued through text, languages with stronger linguistic grounding more often elicit misuse-enabling responses, while weaker languages produce fewer unsafe outputs. When embedded in the image as typographic content, English scripts are reliably recognised and followed, whereas non-English scripts are rarely parsed by the vision encoder. Lower-resource languages may therefore appear safer, but this is an artefact of comprehension and visual-grounding failures rather than genuine alignment, a phenomenon we term safety-by-failure. In contrast, MLLMs that build multilingual capability throughout their training stages rather than only at instruction tuning, such as Qwen3-VL, exhibit genuine cross-lingual safety, maintaining active refusal across languages rather than masking comprehension failure. Shallow multilingual adaptation, such as fine-tuning on translated instruction data, may produce surface-level understanding that creates illusory safety in low-resource languages; deeper integration across training stages leads to genuine multilingual safety alignment.
Investigating Adversarial Robustness of Multi-modal Large Language Models
Jun 02, 2026Multi-modal Large Language Models (MLLMs) achieve strong performance on vision-language tasks, but incorporating visual inputs through a vision encoder (e.g., CLIP) substantially expands the attack surface, making these models vulnerable to visual adversarial perturbations. Prior defenses typically preserve compatibility with pretrained MLLMs by enforcing strict alignment to CLIP's original embedding space during adversarial fine-tuning; while practical, this constraint fundamentally limits achievable robustness. We present a systematic investigation of adversarial robustness in MLLMs. We first introduce a diagnostic CLIP-alignment protocol that predicts, prior to full MLLM training, which robust vision encoders will transfer effectively to the multimodal setting, revealing that large-scale multimodal adversarial pretraining, rather than unimodal scale alone, is the critical factor for strong robustness transfer. Integrating such encoders into MLLMs via end-to-end multimodal training yields average gains of 28 CIDEr points on captioning and 11.7% VQA accuracy under strong adversarial attacks compared to constrained plug-and-play baselines. We further show that adversarial training applied directly to a standard non-robust MLLM degrades both clean and adversarial performance, establishing robust visual representations as a strict prerequisite, while end-to-end adversarial training from a robust backbone delivers additional gains of 1.9 CIDEr points and 4.3% VQA accuracy. Beyond training-time defenses, lightweight test-time visual stochastic transformations serve as an effective black-box defense for non-robust MLLMs, elevating adversarial performance from near-zero to levels comparable with robust models. Finally, we show that our robust models substantially reduce toxic generation under white-box visual jailbreak attacks. Code and pretrained weights will be released publicly.
Hierarchical Self-Supervised Adversarial Training for Robust Vision Models in Histopathology
Mar 13, 2025
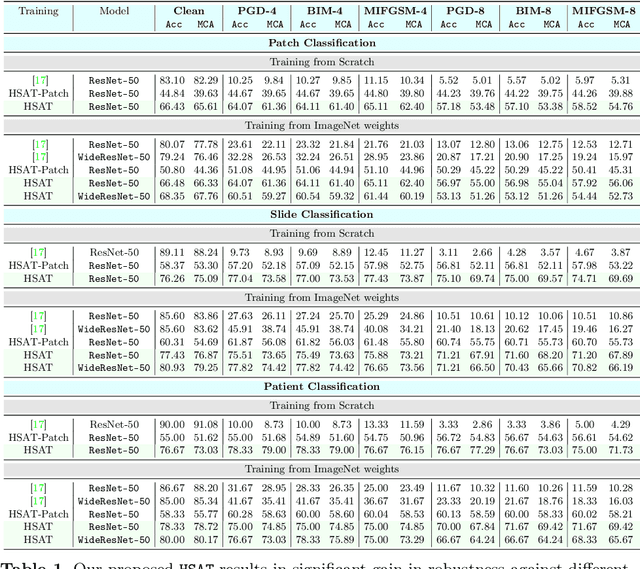


Adversarial attacks pose significant challenges for vision models in critical fields like healthcare, where reliability is essential. Although adversarial training has been well studied in natural images, its application to biomedical and microscopy data remains limited. Existing self-supervised adversarial training methods overlook the hierarchical structure of histopathology images, where patient-slide-patch relationships provide valuable discriminative signals. To address this, we propose Hierarchical Self-Supervised Adversarial Training (HSAT), which exploits these properties to craft adversarial examples using multi-level contrastive learning and integrate it into adversarial training for enhanced robustness. We evaluate HSAT on multiclass histopathology dataset OpenSRH and the results show that HSAT outperforms existing methods from both biomedical and natural image domains. HSAT enhances robustness, achieving an average gain of 54.31% in the white-box setting and reducing performance drops to 3-4% in the black-box setting, compared to 25-30% for the baseline. These results set a new benchmark for adversarial training in this domain, paving the way for more robust models. Our Code for training and evaluation is available at https://github.com/HashmatShadab/HSAT.
Robust-LLaVA: On the Effectiveness of Large-Scale Robust Image Encoders for Multi-modal Large Language Models
Feb 03, 2025



Multi-modal Large Language Models (MLLMs) excel in vision-language tasks but remain vulnerable to visual adversarial perturbations that can induce hallucinations, manipulate responses, or bypass safety mechanisms. Existing methods seek to mitigate these risks by applying constrained adversarial fine-tuning to CLIP vision encoders on ImageNet-scale data, ensuring their generalization ability is preserved. However, this limited adversarial training restricts robustness and broader generalization. In this work, we explore an alternative approach of leveraging existing vision classification models that have been adversarially pre-trained on large-scale data. Our analysis reveals two principal contributions: (1) the extensive scale and diversity of adversarial pre-training enables these models to demonstrate superior robustness against diverse adversarial threats, ranging from imperceptible perturbations to advanced jailbreaking attempts, without requiring additional adversarial training, and (2) end-to-end MLLM integration with these robust models facilitates enhanced adaptation of language components to robust visual features, outperforming existing plug-and-play methodologies on complex reasoning tasks. Through systematic evaluation across visual question-answering, image captioning, and jail-break attacks, we demonstrate that MLLMs trained with these robust models achieve superior adversarial robustness while maintaining favorable clean performance. Our framework achieves 2x and 1.5x average robustness gains in captioning and VQA tasks, respectively, and delivers over 10% improvement against jailbreak attacks. Code and pretrained models will be available at https://github.com/HashmatShadab/Robust-LLaVA.
Towards Evaluating the Robustness of Visual State Space Models
Jun 13, 2024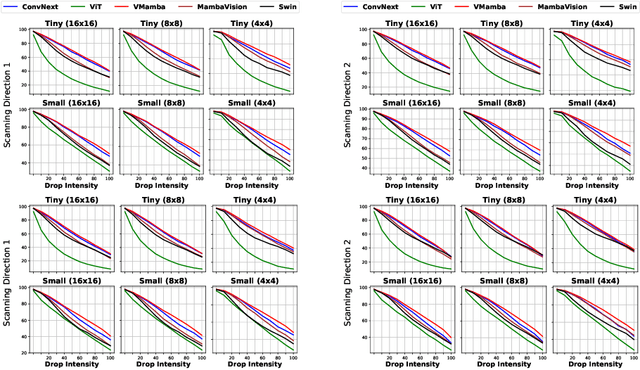
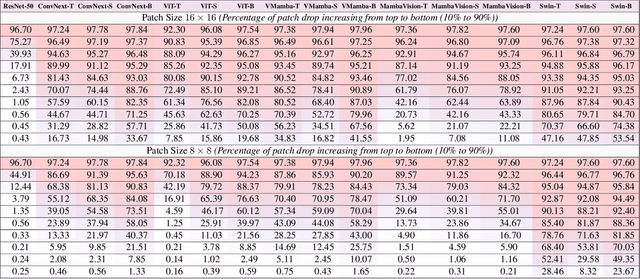
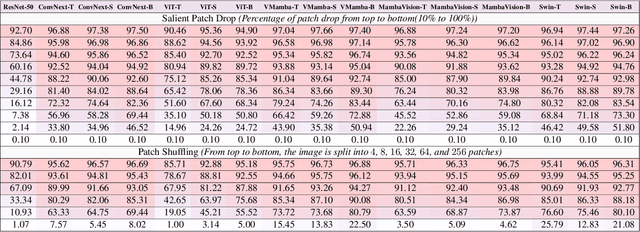
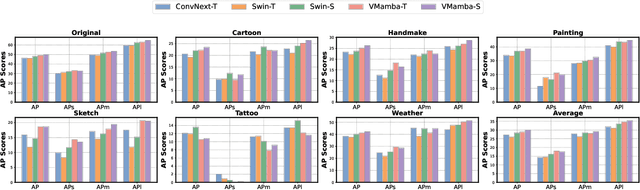
Vision State Space Models (VSSMs), a novel architecture that combines the strengths of recurrent neural networks and latent variable models, have demonstrated remarkable performance in visual perception tasks by efficiently capturing long-range dependencies and modeling complex visual dynamics. However, their robustness under natural and adversarial perturbations remains a critical concern. In this work, we present a comprehensive evaluation of VSSMs' robustness under various perturbation scenarios, including occlusions, image structure, common corruptions, and adversarial attacks, and compare their performance to well-established architectures such as transformers and Convolutional Neural Networks. Furthermore, we investigate the resilience of VSSMs to object-background compositional changes on sophisticated benchmarks designed to test model performance in complex visual scenes. We also assess their robustness on object detection and segmentation tasks using corrupted datasets that mimic real-world scenarios. To gain a deeper understanding of VSSMs' adversarial robustness, we conduct a frequency analysis of adversarial attacks, evaluating their performance against low-frequency and high-frequency perturbations. Our findings highlight the strengths and limitations of VSSMs in handling complex visual corruptions, offering valuable insights for future research and improvements in this promising field. Our code and models will be available at https://github.com/HashmatShadab/MambaRobustness.
On Evaluating Adversarial Robustness of Volumetric Medical Segmentation Models
Jun 12, 2024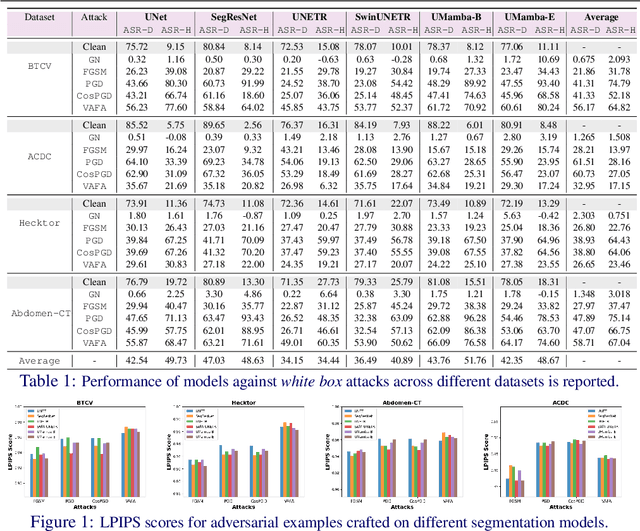
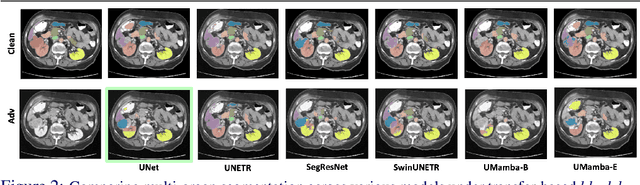
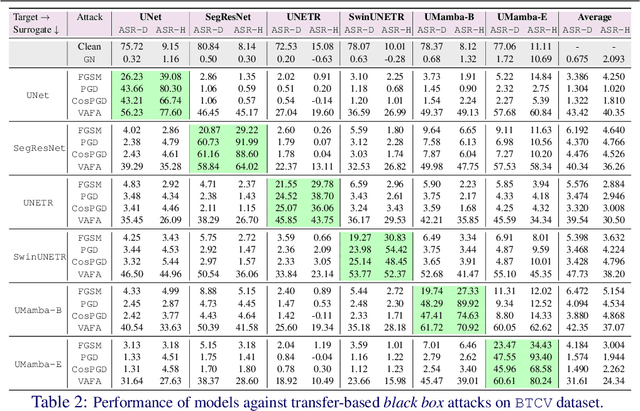
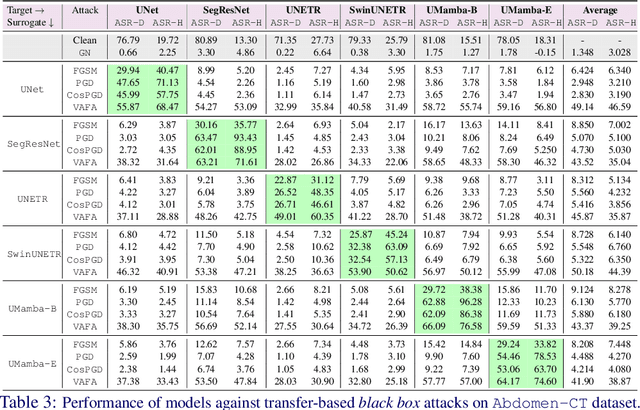
Volumetric medical segmentation models have achieved significant success on organ and tumor-based segmentation tasks in recent years. However, their vulnerability to adversarial attacks remains largely unexplored, raising serious concerns regarding the real-world deployment of tools employing such models in the healthcare sector. This underscores the importance of investigating the robustness of existing models. In this context, our work aims to empirically examine the adversarial robustness across current volumetric segmentation architectures, encompassing Convolutional, Transformer, and Mamba-based models. We extend this investigation across four volumetric segmentation datasets, evaluating robustness under both white box and black box adversarial attacks. Overall, we observe that while both pixel and frequency-based attacks perform reasonably well under white box setting, the latter performs significantly better under transfer-based black box attacks. Across our experiments, we observe transformer-based models show higher robustness than convolution-based models with Mamba-based models being the most vulnerable. Additionally, we show that large-scale training of volumetric segmentation models improves the model's robustness against adversarial attacks. The code and pretrained models will be made available at https://github.com/HashmatShadab/Robustness-of-Volumetric-Medical-Segmentation-Models.
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
Mar 15, 2024Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. This allows us to quantify the role of background context in understanding the robustness and generalization of deep neural networks. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.
Adversarial Pixel Restoration as a Pretext Task for Transferable Perturbations
Jul 18, 2022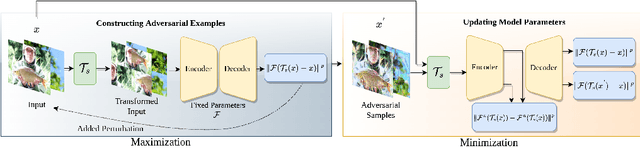
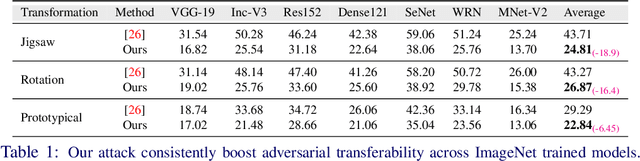
Transferable adversarial attacks optimize adversaries from a pretrained surrogate model and known label space to fool the unknown black-box models. Therefore, these attacks are restricted by the availability of an effective surrogate model. In this work, we relax this assumption and propose Adversarial Pixel Restoration as a self-supervised alternative to train an effective surrogate model from scratch under the condition of no labels and few data samples. Our training approach is based on a min-max objective which reduces overfitting via an adversarial objective and thus optimizes for a more generalizable surrogate model. Our proposed attack is complimentary to our adversarial pixel restoration and is independent of any task specific objective as it can be launched in a self-supervised manner. We successfully demonstrate the adversarial transferability of our approach to Vision Transformers as well as Convolutional Neural Networks for the tasks of classification, object detection, and video segmentation. Our codes & pre-trained surrogate models are available at: https://github.com/HashmatShadab/APR
Object Detection in Aerial Images: What Improves the Accuracy?
Jan 21, 2022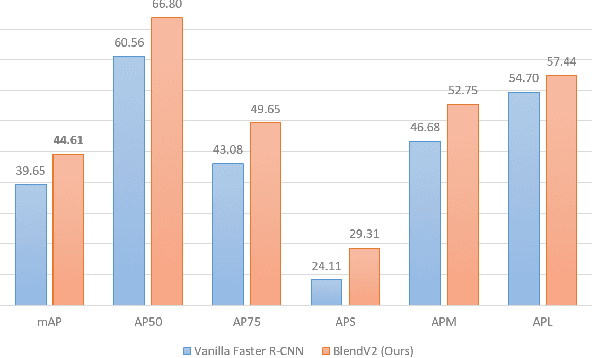
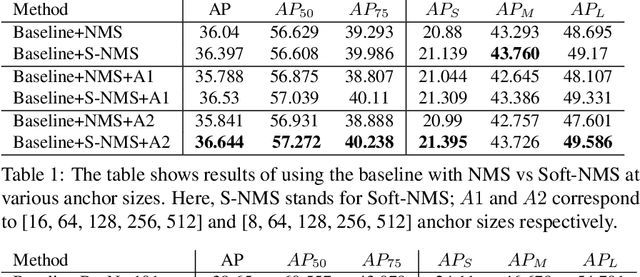
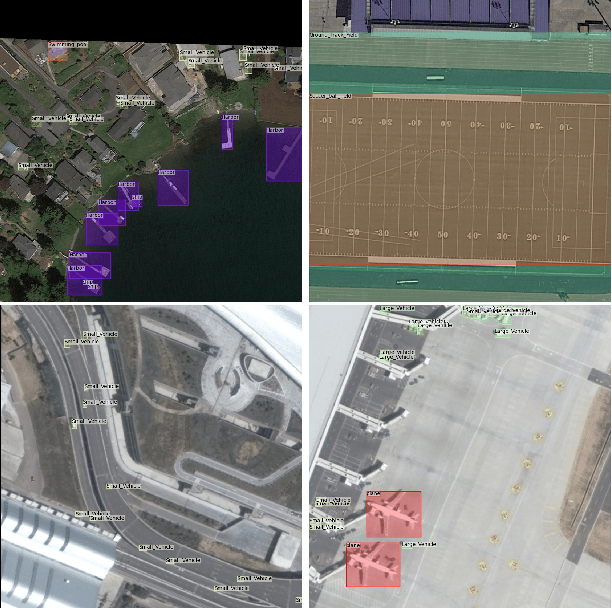
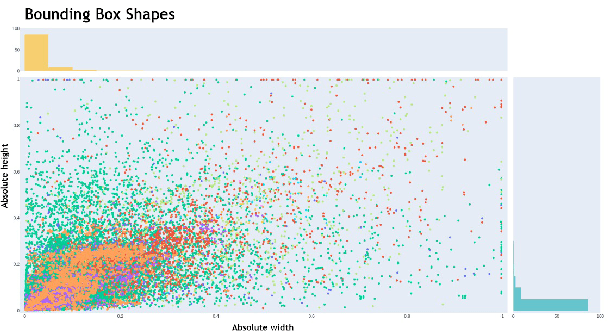
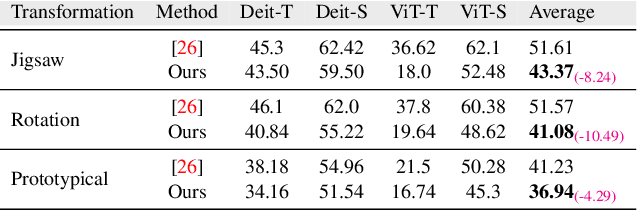
Object detection is a challenging and popular computer vision problem. The problem is even more challenging in aerial images due to significant variation in scale and viewpoint in a diverse set of object categories. Recently, deep learning-based object detection approaches have been actively explored for the problem of object detection in aerial images. In this work, we investigate the impact of Faster R-CNN for aerial object detection and explore numerous strategies to improve its performance for aerial images. We conduct extensive experiments on the challenging iSAID dataset. The resulting adapted Faster R-CNN obtains a significant mAP gain of 4.96% over its vanilla baseline counterpart on the iSAID validation set, demonstrating the impact of different strategies investigated in this work.