 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
Mar 25, 2026Multimodal agentic pipelines are transforming human-computer interaction by enabling efficient and accessible automation of complex, real-world tasks. However, recent efforts have focused on short-horizon or general-purpose applications (e.g., mobile or desktop interfaces), leaving long-horizon automation for domain-specific systems, particularly in healthcare, largely unexplored. To address this, we introduce CareFlow, a high-quality human-annotated benchmark comprising complex, long-horizon software workflows across medical annotation tools, DICOM viewers, EHR systems, and laboratory information systems. On this benchmark, existing vision-language models (VLMs) perform poorly, struggling with long-horizon reasoning and multi-step interactions in medical contexts. To overcome this, we propose CarePilot, a multi-agent framework based on the actor-critic paradigm. The Actor integrates tool grounding with dual-memory mechanisms (long-term and short-term experience) to predict the next semantic action from the visual interface and system state. The Critic evaluates each action, updates memory based on observed effects, and either executes or provides corrective feedback to refine the workflow. Through iterative agentic simulation, the Actor learns to perform more robust and reasoning-aware predictions during inference. Our experiments show that CarePilot achieves state-of-the-art performance, outperforming strong closed-source and open-source multimodal baselines by approximately 15.26% and 3.38%, respectively, on our benchmark and out-of-distribution dataset.
MobileFetalCLIP: Selective Repulsive Knowledge Distillation for Mobile Fetal Ultrasound Analysis
Mar 05, 2026Fetal ultrasound AI could transform prenatal care in low-resource settings, yet current foundation models exceed 300M visual parameters, precluding deployment on point-of-care devices. Standard knowledge distillation fails under such extreme capacity gaps (~26x), as compact students waste capacity mimicking architectural artifacts of oversized teachers. We introduce Selective Repulsive Knowledge Distillation, which decomposes contrastive KD into diagonal and off-diagonal components: matched pair alignment is preserved while the off-diagonal weight decays into negative values, repelling the student from the teacher's inter-class confusions and forcing discovery of architecturally native features. Our 11.4M parameter student surpasses the 304M-parameter FetalCLIP teacher on zero-shot HC18 biometry validity (88.6% vs. 83.5%) and brain sub-plane F1 (0.784 vs. 0.702), while running at 1.6 ms on iPhone 16 Pro, enabling real-time assistive AI on handheld ultrasound devices. Our code, models, and app are publicly available at https://github.com/numanai/MobileFetalCLIP.
Beyond Benchmarks of IUGC: Rethinking Requirements of Deep Learning Methods for Intrapartum Ultrasound Biometry from Fetal Ultrasound Videos
Feb 13, 2026A substantial proportion (45\%) of maternal deaths, neonatal deaths, and stillbirths occur during the intrapartum phase, with a particularly high burden in low- and middle-income countries. Intrapartum biometry plays a critical role in monitoring labor progression; however, the routine use of ultrasound in resource-limited settings is hindered by a shortage of trained sonographers. To address this challenge, the Intrapartum Ultrasound Grand Challenge (IUGC), co-hosted with MICCAI 2024, was launched. The IUGC introduces a clinically oriented multi-task automatic measurement framework that integrates standard plane classification, fetal head-pubic symphysis segmentation, and biometry, enabling algorithms to exploit complementary task information for more accurate estimation. Furthermore, the challenge releases the largest multi-center intrapartum ultrasound video dataset to date, comprising 774 videos (68,106 frames) collected from three hospitals, providing a robust foundation for model training and evaluation. In this study, we present a comprehensive overview of the challenge design, review the submissions from eight participating teams, and analyze their methods from five perspectives: preprocessing, data augmentation, learning strategy, model architecture, and post-processing. In addition, we perform a systematic analysis of the benchmark results to identify key bottlenecks, explore potential solutions, and highlight open challenges for future research. Although encouraging performance has been achieved, our findings indicate that the field remains at an early stage, and further in-depth investigation is required before large-scale clinical deployment. All benchmark solutions and the complete dataset have been publicly released to facilitate reproducible research and promote continued advances in automatic intrapartum ultrasound biometry.
AnatomiX, an Anatomy-Aware Grounded Multimodal Large Language Model for Chest X-Ray Interpretation
Jan 06, 2026Multimodal medical large language models have shown impressive progress in chest X-ray interpretation but continue to face challenges in spatial reasoning and anatomical understanding. Although existing grounding techniques improve overall performance, they often fail to establish a true anatomical correspondence, resulting in incorrect anatomical understanding in the medical domain. To address this gap, we introduce AnatomiX, a multitask multimodal large language model explicitly designed for anatomically grounded chest X-ray interpretation. Inspired by the radiological workflow, AnatomiX adopts a two stage approach: first, it identifies anatomical structures and extracts their features, and then leverages a large language model to perform diverse downstream tasks such as phrase grounding, report generation, visual question answering, and image understanding. Extensive experiments across multiple benchmarks demonstrate that AnatomiX achieves superior anatomical reasoning and delivers over 25% improvement in performance on anatomy grounding, phrase grounding, grounded diagnosis and grounded captioning tasks compared to existing approaches. Code and pretrained model are available at https://github.com/aneesurhashmi/anatomix
FETAL-GAUGE: A Benchmark for Assessing Vision-Language Models in Fetal Ultrasound
Dec 25, 2025The growing demand for prenatal ultrasound imaging has intensified a global shortage of trained sonographers, creating barriers to essential fetal health monitoring. Deep learning has the potential to enhance sonographers' efficiency and support the training of new practitioners. Vision-Language Models (VLMs) are particularly promising for ultrasound interpretation, as they can jointly process images and text to perform multiple clinical tasks within a single framework. However, despite the expansion of VLMs, no standardized benchmark exists to evaluate their performance in fetal ultrasound imaging. This gap is primarily due to the modality's challenging nature, operator dependency, and the limited public availability of datasets. To address this gap, we present Fetal-Gauge, the first and largest visual question answering benchmark specifically designed to evaluate VLMs across various fetal ultrasound tasks. Our benchmark comprises over 42,000 images and 93,000 question-answer pairs, spanning anatomical plane identification, visual grounding of anatomical structures, fetal orientation assessment, clinical view conformity, and clinical diagnosis. We systematically evaluate several state-of-the-art VLMs, including general-purpose and medical-specific models, and reveal a substantial performance gap: the best-performing model achieves only 55\% accuracy, far below clinical requirements. Our analysis identifies critical limitations of current VLMs in fetal ultrasound interpretation, highlighting the urgent need for domain-adapted architectures and specialized training approaches. Fetal-Gauge establishes a rigorous foundation for advancing multimodal deep learning in prenatal care and provides a pathway toward addressing global healthcare accessibility challenges. Our benchmark will be publicly available once the paper gets accepted.
MAFM^3: Modular Adaptation of Foundation Models for Multi-Modal Medical AI
Nov 14, 2025Foundational models are trained on extensive datasets to capture the general trends of a domain. However, in medical imaging, the scarcity of data makes pre-training for every domain, modality, or task challenging. Instead of building separate models, we propose MAFM^3 (Modular Adaptation of Foundation Models for Multi-Modal Medical AI), a framework that enables a single foundation model to expand into diverse domains, tasks, and modalities through lightweight modular components. These components serve as specialized skill sets that allow the system to flexibly activate the appropriate capability at the inference time, depending on the input type or clinical objective. Unlike conventional adaptation methods that treat each new task or modality in isolation, MAFM^3 provides a unified and expandable framework for efficient multitask and multimodality adaptation. Empirically, we validate our approach by adapting a chest CT foundation model initially trained for classification into prognosis and segmentation modules. Our results show improved performance on both tasks. Furthermore, by incorporating PET scans, MAFM^3 achieved an improvement in the Dice score 5% compared to the respective baselines. These findings establish that foundation models, when equipped with modular components, are not inherently constrained to their initial training scope but can evolve into multitask, multimodality systems for medical imaging. The code implementation of this work can be found at https://github.com/Areeb2735/CTscan_prognosis_VLM
CardioBench: Do Echocardiography Foundation Models Generalize Beyond the Lab?
Oct 01, 2025Foundation models (FMs) are reshaping medical imaging, yet their application in echocardiography remains limited. While several echocardiography-specific FMs have recently been introduced, no standardized benchmark exists to evaluate them. Echocardiography poses unique challenges, including noisy acquisitions, high frame redundancy, and limited public datasets. Most existing solutions evaluate on private data, restricting comparability. To address this, we introduce CardioBench, a comprehensive benchmark for echocardiography FMs. CardioBench unifies eight publicly available datasets into a standardized suite spanning four regression and five classification tasks, covering functional, structural, diagnostic, and view recognition endpoints. We evaluate several leading FM, including cardiac-specific, biomedical, and general-purpose encoders, under consistent zero-shot, probing, and alignment protocols. Our results highlight complementary strengths across model families: temporal modeling is critical for functional regression, retrieval provides robustness under distribution shift, and domain-specific text encoders capture physiologically meaningful axes. General-purpose encoders transfer strongly and often close the gap with probing, but struggle with fine-grained distinctions like view classification and subtle pathology recognition. By releasing preprocessing, splits, and public evaluation pipelines, CardioBench establishes a reproducible reference point and offers actionable insights to guide the design of future echocardiography foundation models.
PCA-Guided Autoencoding for Structured Dimensionality Reduction in Active Infrared Thermography
Aug 11, 2025Active Infrared thermography (AIRT) is a widely adopted non-destructive testing (NDT) technique for detecting subsurface anomalies in industrial components. Due to the high dimensionality of AIRT data, current approaches employ non-linear autoencoders (AEs) for dimensionality reduction. However, the latent space learned by AIRT AEs lacks structure, limiting their effectiveness in downstream defect characterization tasks. To address this limitation, this paper proposes a principal component analysis guided (PCA-guided) autoencoding framework for structured dimensionality reduction to capture intricate, non-linear features in thermographic signals while enforcing a structured latent space. A novel loss function, PCA distillation loss, is introduced to guide AIRT AEs to align the latent representation with structured PCA components while capturing the intricate, non-linear patterns in thermographic signals. To evaluate the utility of the learned, structured latent space, we propose a neural network-based evaluation metric that assesses its suitability for defect characterization. Experimental results show that the proposed PCA-guided AE outperforms state-of-the-art dimensionality reduction methods on PVC, CFRP, and PLA samples in terms of contrast, signal-to-noise ratio (SNR), and neural network-based metrics.
Efficient Parameter Adaptation for Multi-Modal Medical Image Segmentation and Prognosis
Apr 18, 2025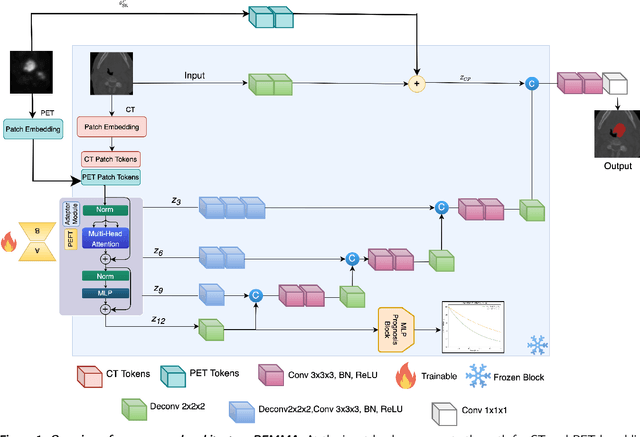
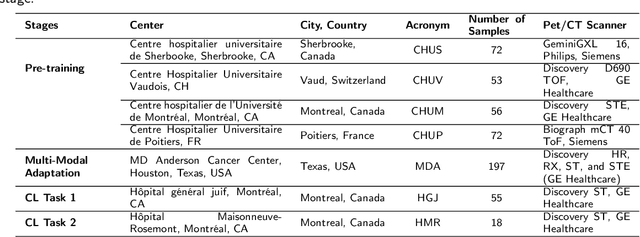
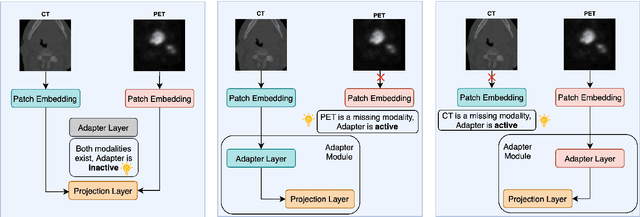
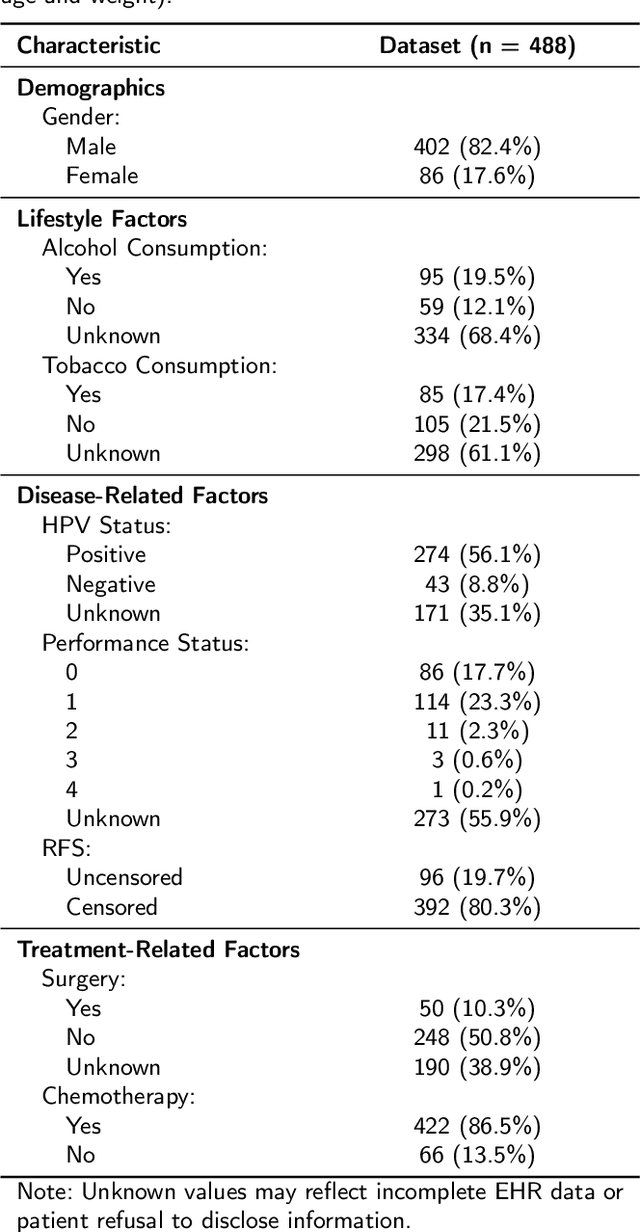
Cancer detection and prognosis relies heavily on medical imaging, particularly CT and PET scans. Deep Neural Networks (DNNs) have shown promise in tumor segmentation by fusing information from these modalities. However, a critical bottleneck exists: the dependency on CT-PET data concurrently for training and inference, posing a challenge due to the limited availability of PET scans. Hence, there is a clear need for a flexible and efficient framework that can be trained with the widely available CT scans and can be still adapted for PET scans when they become available. In this work, we propose a parameter-efficient multi-modal adaptation (PEMMA) framework for lightweight upgrading of a transformer-based segmentation model trained only on CT scans such that it can be efficiently adapted for use with PET scans when they become available. This framework is further extended to perform prognosis task maintaining the same efficient cross-modal fine-tuning approach. The proposed approach is tested with two well-known segementation backbones, namely UNETR and Swin UNETR. Our approach offers two main advantages. Firstly, we leverage the inherent modularity of the transformer architecture and perform low-rank adaptation (LoRA) as well as decomposed low-rank adaptation (DoRA) of the attention weights to achieve parameter-efficient adaptation. Secondly, by minimizing cross-modal entanglement, PEMMA allows updates using only one modality without causing catastrophic forgetting in the other. Our method achieves comparable performance to early fusion, but with only 8% of the trainable parameters, and demonstrates a significant +28% Dice score improvement on PET scans when trained with a single modality. Furthermore, in prognosis, our method improves the concordance index by +10% when adapting a CT-pretrained model to include PET scans, and by +23% when adapting for both PET and EHR data.
In-Model Merging for Enhancing the Robustness of Medical Imaging Classification Models
Feb 27, 2025



Model merging is an effective strategy to merge multiple models for enhancing model performances, and more efficient than ensemble learning as it will not introduce extra computation into inference. However, limited research explores if the merging process can occur within one model and enhance the model's robustness, which is particularly critical in the medical image domain. In the paper, we are the first to propose in-model merging (InMerge), a novel approach that enhances the model's robustness by selectively merging similar convolutional kernels in the deep layers of a single convolutional neural network (CNN) during the training process for classification. We also analytically reveal important characteristics that affect how in-model merging should be performed, serving as an insightful reference for the community. We demonstrate the feasibility and effectiveness of this technique for different CNN architectures on 4 prevalent datasets. The proposed InMerge-trained model surpasses the typically-trained model by a substantial margin. The code will be made public.