 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Examination Framework: A Task-Agnostic Diagnostic for Information Fidelity in Text-to-Text Generation
Jan 27, 2026Traditional metrics like BLEU and BERTScore fail to capture semantic fidelity in generative text-to-text tasks. We adapt the Cross-Examination Framework (CEF) for a reference-free, multi-dimensional evaluation by treating the source and candidate as independent knowledge bases. CEF generates verifiable questions from each text and performs a cross-examination to derive three interpretable scores: Coverage, Conformity, and Consistency. Validated across translation, summarization and clinical note-generation, our framework identifies critical errors, such as content omissions and factual contradictions, missed by standard metrics. A key contribution is a systematic robustness analysis to select a stable judge model. Crucially, the strong correlation between our reference-free and with-reference modes validates CEF's reliability without gold references. Furthermore, human expert validation demonstrates that CEF mismatching questions align with meaning-altering semantic errors higher than with non-semantic errors, particularly excelling at identifying entity-based and relational distortions.
Efficient Parameter Adaptation for Multi-Modal Medical Image Segmentation and Prognosis
Apr 18, 2025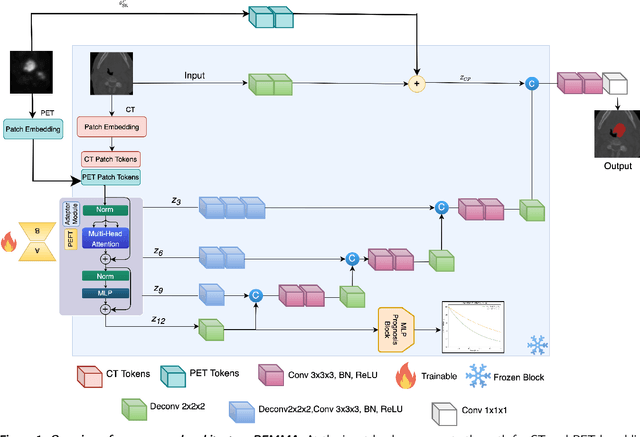
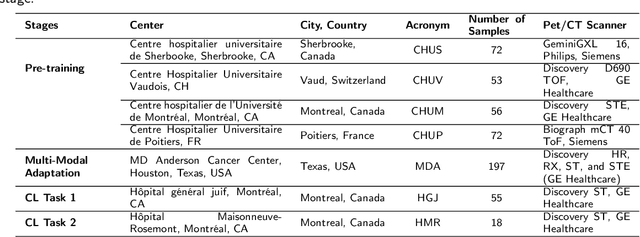
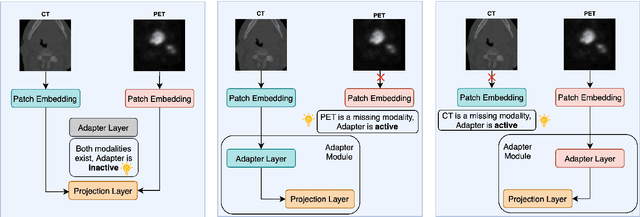
Cancer detection and prognosis relies heavily on medical imaging, particularly CT and PET scans. Deep Neural Networks (DNNs) have shown promise in tumor segmentation by fusing information from these modalities. However, a critical bottleneck exists: the dependency on CT-PET data concurrently for training and inference, posing a challenge due to the limited availability of PET scans. Hence, there is a clear need for a flexible and efficient framework that can be trained with the widely available CT scans and can be still adapted for PET scans when they become available. In this work, we propose a parameter-efficient multi-modal adaptation (PEMMA) framework for lightweight upgrading of a transformer-based segmentation model trained only on CT scans such that it can be efficiently adapted for use with PET scans when they become available. This framework is further extended to perform prognosis task maintaining the same efficient cross-modal fine-tuning approach. The proposed approach is tested with two well-known segementation backbones, namely UNETR and Swin UNETR. Our approach offers two main advantages. Firstly, we leverage the inherent modularity of the transformer architecture and perform low-rank adaptation (LoRA) as well as decomposed low-rank adaptation (DoRA) of the attention weights to achieve parameter-efficient adaptation. Secondly, by minimizing cross-modal entanglement, PEMMA allows updates using only one modality without causing catastrophic forgetting in the other. Our method achieves comparable performance to early fusion, but with only 8% of the trainable parameters, and demonstrates a significant +28% Dice score improvement on PET scans when trained with a single modality. Furthermore, in prognosis, our method improves the concordance index by +10% when adapting a CT-pretrained model to include PET scans, and by +23% when adapting for both PET and EHR data.
MEDIC: Towards a Comprehensive Framework for Evaluating LLMs in Clinical Applications
Sep 11, 2024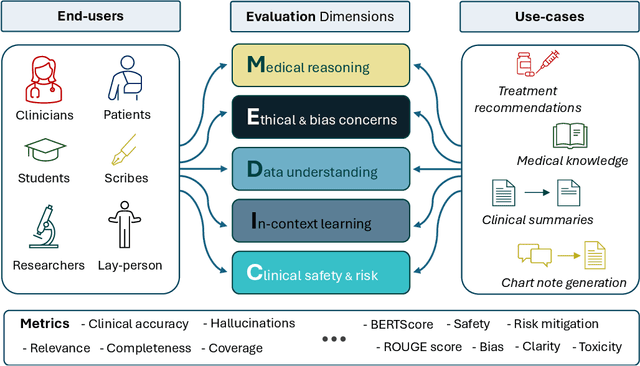
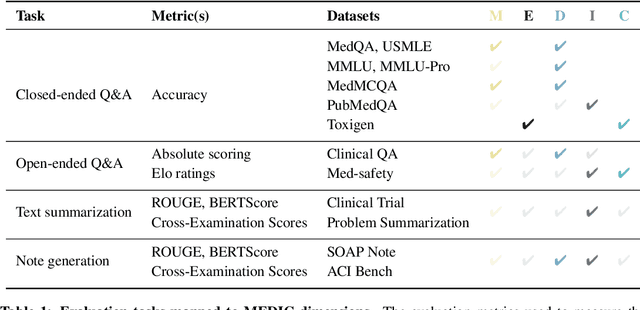
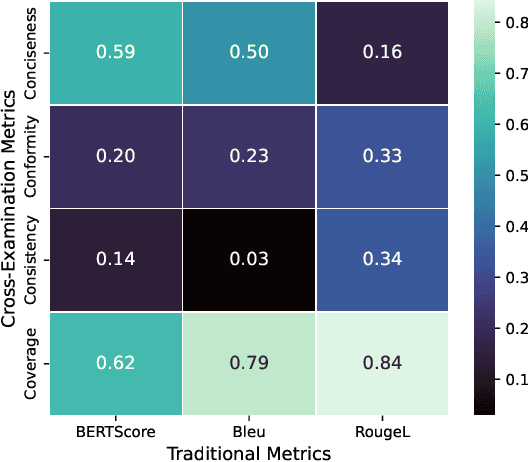
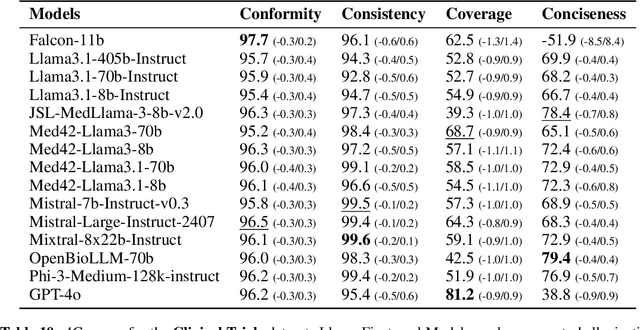
The rapid development of Large Language Models (LLMs) for healthcare applications has spurred calls for holistic evaluation beyond frequently-cited benchmarks like USMLE, to better reflect real-world performance. While real-world assessments are valuable indicators of utility, they often lag behind the pace of LLM evolution, likely rendering findings obsolete upon deployment. This temporal disconnect necessitates a comprehensive upfront evaluation that can guide model selection for specific clinical applications. We introduce MEDIC, a framework assessing LLMs across five critical dimensions of clinical competence: medical reasoning, ethics and bias, data and language understanding, in-context learning, and clinical safety. MEDIC features a novel cross-examination framework quantifying LLM performance across areas like coverage and hallucination detection, without requiring reference outputs. We apply MEDIC to evaluate LLMs on medical question-answering, safety, summarization, note generation, and other tasks. Our results show performance disparities across model sizes, baseline vs medically finetuned models, and have implications on model selection for applications requiring specific model strengths, such as low hallucination or lower cost of inference. MEDIC's multifaceted evaluation reveals these performance trade-offs, bridging the gap between theoretical capabilities and practical implementation in healthcare settings, ensuring that the most promising models are identified and adapted for diverse healthcare applications.
PEMMA: Parameter-Efficient Multi-Modal Adaptation for Medical Image Segmentation
Apr 21, 2024


Imaging modalities such as Computed Tomography (CT) and Positron Emission Tomography (PET) are key in cancer detection, inspiring Deep Neural Networks (DNN) models that merge these scans for tumor segmentation. When both CT and PET scans are available, it is common to combine them as two channels of the input to the segmentation model. However, this method requires both scan types during training and inference, posing a challenge due to the limited availability of PET scans, thereby sometimes limiting the process to CT scans only. Hence, there is a need to develop a flexible DNN architecture that can be trained/updated using only CT scans but can effectively utilize PET scans when they become available. In this work, we propose a parameter-efficient multi-modal adaptation (PEMMA) framework for lightweight upgrading of a transformer-based segmentation model trained only on CT scans to also incorporate PET scans. The benefits of the proposed approach are two-fold. Firstly, we leverage the inherent modularity of the transformer architecture and perform low-rank adaptation (LoRA) of the attention weights to achieve parameter-efficient adaptation. Secondly, since the PEMMA framework attempts to minimize cross modal entanglement, it is possible to subsequently update the combined model using only one modality, without causing catastrophic forgetting of the other modality. Our proposed method achieves comparable results with the performance of early fusion techniques with just 8% of the trainable parameters, especially with a remarkable +28% improvement on the average dice score on PET scans when trained on a single modality.
Multi-Attribute Vision Transformers are Efficient and Robust Learners
Feb 12, 2024



Since their inception, Vision Transformers (ViTs) have emerged as a compelling alternative to Convolutional Neural Networks (CNNs) across a wide spectrum of tasks. ViTs exhibit notable characteristics, including global attention, resilience against occlusions, and adaptability to distribution shifts. One underexplored aspect of ViTs is their potential for multi-attribute learning, referring to their ability to simultaneously grasp multiple attribute-related tasks. In this paper, we delve into the multi-attribute learning capability of ViTs, presenting a straightforward yet effective strategy for training various attributes through a single ViT network as distinct tasks. We assess the resilience of multi-attribute ViTs against adversarial attacks and compare their performance against ViTs designed for single attributes. Moreover, we further evaluate the robustness of multi-attribute ViTs against a recent transformer based attack called Patch-Fool. Our empirical findings on the CelebA dataset provide validation for our assertion.
UniLVSeg: Unified Left Ventricular Segmentation with Sparsely Annotated Echocardiogram Videos through Self-Supervised Temporal Masking and Weakly Supervised Training
Sep 30, 2023Echocardiography has become an indispensable clinical imaging modality for general heart health assessment. From calculating biomarkers such as ejection fraction to the probability of a patient's heart failure, accurate segmentation of the heart and its structures allows doctors to plan and execute treatments with greater precision and accuracy. However, achieving accurate and robust left ventricle segmentation is time-consuming and challenging due to different reasons. This work introduces a novel approach for consistent left ventricular (LV) segmentation from sparsely annotated echocardiogram videos. We achieve this through (1) self-supervised learning (SSL) using temporal masking followed by (2) weakly supervised training. We investigate two different segmentation approaches: 3D segmentation and a novel 2D superimage (SI). We demonstrate how our proposed method outperforms the state-of-the-art solutions by achieving a 93.32% (95%CI 93.21-93.43%) dice score on a large-scale dataset (EchoNet-Dynamic) while being more efficient. To show the effectiveness of our approach, we provide extensive ablation studies, including pre-training settings and various deep learning backbones. Additionally, we discuss how our proposed methodology achieves high data utility by incorporating unlabeled frames in the training process. To help support the AI in medicine community, the complete solution with the source code will be made publicly available upon acceptance.