 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst-Place Solution to NeurIPS 2024 Invisible Watermark Removal Challenge
Aug 28, 2025Content watermarking is an important tool for the authentication and copyright protection of digital media. However, it is unclear whether existing watermarks are robust against adversarial attacks. We present the winning solution to the NeurIPS 2024 Erasing the Invisible challenge, which stress-tests watermark robustness under varying degrees of adversary knowledge. The challenge consisted of two tracks: a black-box and beige-box track, depending on whether the adversary knows which watermarking method was used by the provider. For the beige-box track, we leverage an adaptive VAE-based evasion attack, with a test-time optimization and color-contrast restoration in CIELAB space to preserve the image's quality. For the black-box track, we first cluster images based on their artifacts in the spatial or frequency-domain. Then, we apply image-to-image diffusion models with controlled noise injection and semantic priors from ChatGPT-generated captions to each cluster with optimized parameter settings. Empirical evaluations demonstrate that our method successfully achieves near-perfect watermark removal (95.7%) with negligible impact on the residual image's quality. We hope that our attacks inspire the development of more robust image watermarking methods.
Mitigating Watermark Stealing Attacks in Generative Models via Multi-Key Watermarking
Jul 10, 2025Watermarking offers a promising solution for GenAI providers to establish the provenance of their generated content. A watermark is a hidden signal embedded in the generated content, whose presence can later be verified using a secret watermarking key. A threat to GenAI providers are \emph{watermark stealing} attacks, where users forge a watermark into content that was \emph{not} generated by the provider's models without access to the secret key, e.g., to falsely accuse the provider. Stealing attacks collect \emph{harmless} watermarked samples from the provider's model and aim to maximize the expected success rate of generating \emph{harmful} watermarked samples. Our work focuses on mitigating stealing attacks while treating the underlying watermark as a black-box. Our contributions are: (i) Proposing a multi-key extension to mitigate stealing attacks that can be applied post-hoc to any watermarking method across any modality. (ii) We provide theoretical guarantees and demonstrate empirically that our method makes forging substantially less effective across multiple datasets, and (iii) we formally define the threat of watermark forging as the task of generating harmful, watermarked content and model this threat via security games.
PromptSmooth: Certifying Robustness of Medical Vision-Language Models via Prompt Learning
Aug 29, 2024
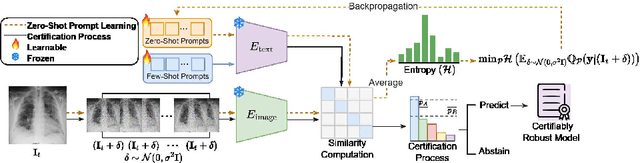
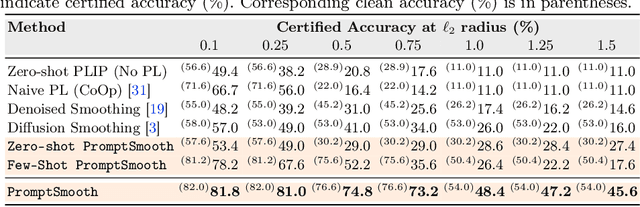
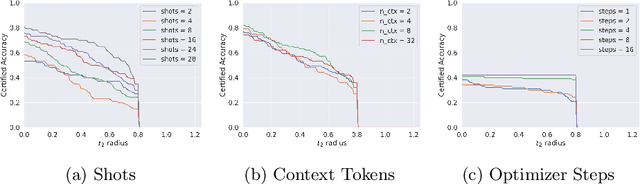
Medical vision-language models (Med-VLMs) trained on large datasets of medical image-text pairs and later fine-tuned for specific tasks have emerged as a mainstream paradigm in medical image analysis. However, recent studies have highlighted the susceptibility of these Med-VLMs to adversarial attacks, raising concerns about their safety and robustness. Randomized smoothing is a well-known technique for turning any classifier into a model that is certifiably robust to adversarial perturbations. However, this approach requires retraining the Med-VLM-based classifier so that it classifies well under Gaussian noise, which is often infeasible in practice. In this paper, we propose a novel framework called PromptSmooth to achieve efficient certified robustness of Med-VLMs by leveraging the concept of prompt learning. Given any pre-trained Med-VLM, PromptSmooth adapts it to handle Gaussian noise by learning textual prompts in a zero-shot or few-shot manner, achieving a delicate balance between accuracy and robustness, while minimizing the computational overhead. Moreover, PromptSmooth requires only a single model to handle multiple noise levels, which substantially reduces the computational cost compared to traditional methods that rely on training a separate model for each noise level. Comprehensive experiments based on three Med-VLMs and across six downstream datasets of various imaging modalities demonstrate the efficacy of PromptSmooth. Our code and models are available at https://github.com/nhussein/promptsmooth.
Multi-Attribute Vision Transformers are Efficient and Robust Learners
Feb 12, 2024



Since their inception, Vision Transformers (ViTs) have emerged as a compelling alternative to Convolutional Neural Networks (CNNs) across a wide spectrum of tasks. ViTs exhibit notable characteristics, including global attention, resilience against occlusions, and adaptability to distribution shifts. One underexplored aspect of ViTs is their potential for multi-attribute learning, referring to their ability to simultaneously grasp multiple attribute-related tasks. In this paper, we delve into the multi-attribute learning capability of ViTs, presenting a straightforward yet effective strategy for training various attributes through a single ViT network as distinct tasks. We assess the resilience of multi-attribute ViTs against adversarial attacks and compare their performance against ViTs designed for single attributes. Moreover, we further evaluate the robustness of multi-attribute ViTs against a recent transformer based attack called Patch-Fool. Our empirical findings on the CelebA dataset provide validation for our assertion.
Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization
Nov 02, 2023



The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains -- distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top- 1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves consistently across all datasets compared to the existing state-of-the-art. Our source code and models are available at https://jameelhassan.github.io/promptalign.