 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP meets DINO for Tuning Zero-Shot Classifier using Unlabeled Image Collections
Nov 28, 2024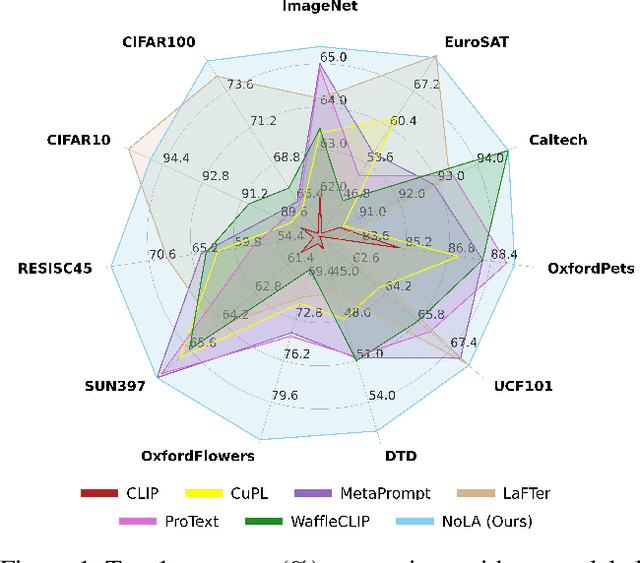
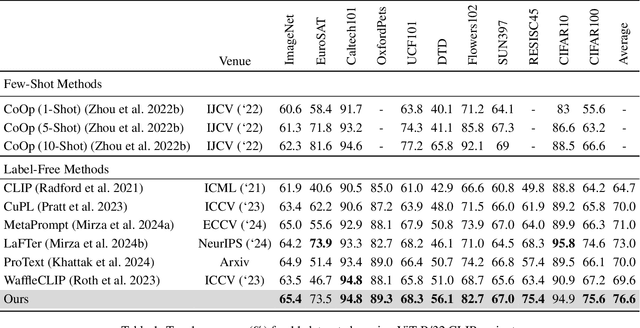
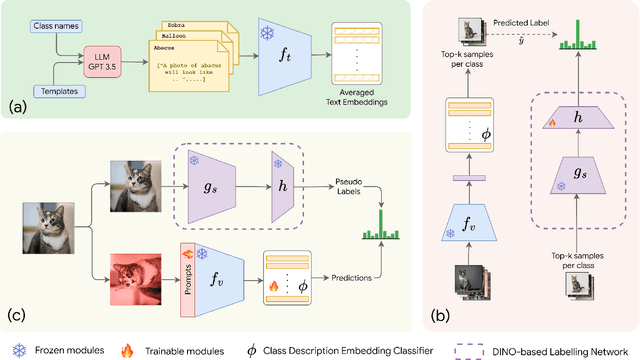
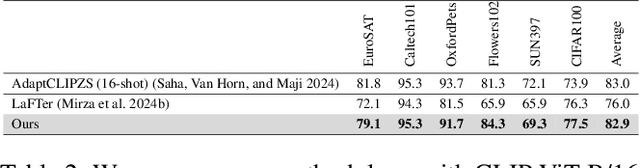
In the era of foundation models, CLIP has emerged as a powerful tool for aligning text and visual modalities into a common embedding space. However, the alignment objective used to train CLIP often results in subpar visual features for fine-grained tasks. In contrast, SSL-pretrained models like DINO excel at extracting rich visual features due to their specialized training paradigm. Yet, these SSL models require an additional supervised linear probing step, which relies on fully labeled data which is often expensive and difficult to obtain at scale. In this paper, we propose a label-free prompt-tuning method that leverages the rich visual features of self-supervised learning models (DINO) and the broad textual knowledge of large language models (LLMs) to largely enhance CLIP-based image classification performance using unlabeled images. Our approach unfolds in three key steps: (1) We generate robust textual feature embeddings that more accurately represent object classes by leveraging class-specific descriptions from LLMs, enabling more effective zero-shot classification compared to CLIP's default name-specific prompts. (2) These textual embeddings are then used to produce pseudo-labels to train an alignment module that integrates the complementary strengths of LLM description-based textual embeddings and DINO's visual features. (3) Finally, we prompt-tune CLIP's vision encoder through DINO-assisted supervision using the trained alignment module. This three-step process allows us to harness the best of visual and textual foundation models, resulting in a powerful and efficient approach that surpasses state-of-the-art label-free classification methods. Notably, our framework, NoLA (No Labels Attached), achieves an average absolute gain of 3.6% over the state-of-the-art LaFter across 11 diverse image classification datasets.
How Good is my Video LMM? Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 08, 2024



Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical surgery, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, especially open-source ones, struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.
Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 06, 2024Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical imaging, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, {especially open-source ones,} struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.
Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization
Nov 02, 2023



The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains -- distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top- 1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves consistently across all datasets compared to the existing state-of-the-art. Our source code and models are available at https://jameelhassan.github.io/promptalign.
Drawing Attention to Detail: Pose Alignment through Self-Attention for Fine-Grained Object Classification
Feb 09, 2023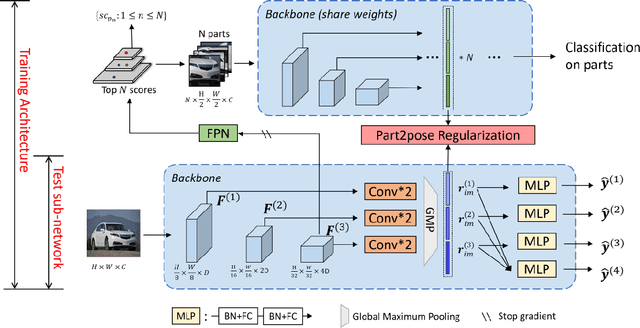


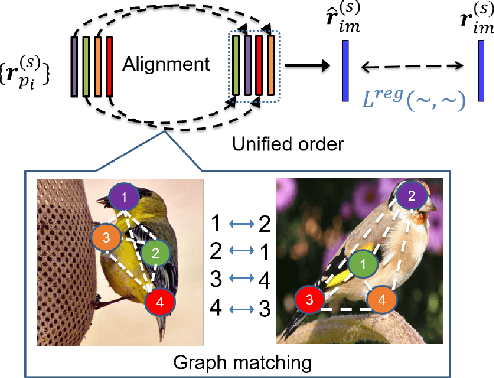
Intra-class variations in the open world lead to various challenges in classification tasks. To overcome these challenges, fine-grained classification was introduced, and many approaches were proposed. Some rely on locating and using distinguishable local parts within images to achieve invariance to viewpoint changes, intra-class differences, and local part deformations. Our approach, which is inspired by P2P-Net, offers an end-to-end trainable attention-based parts alignment module, where we replace the graph-matching component used in it with a self-attention mechanism. The attention module is able to learn the optimal arrangement of parts while attending to each other, before contributing to the global loss.
Holistic Interpretation of Public Scenes Using Computer Vision and Temporal Graphs to Identify Social Distancing Violations
Dec 13, 2021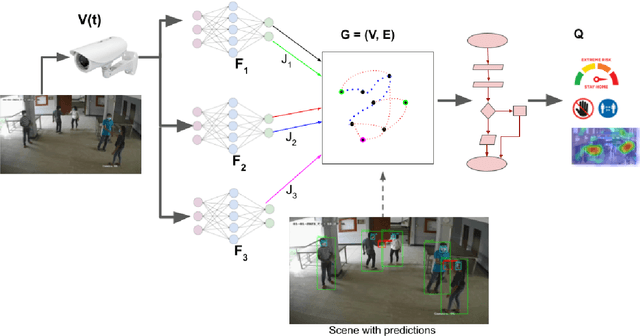

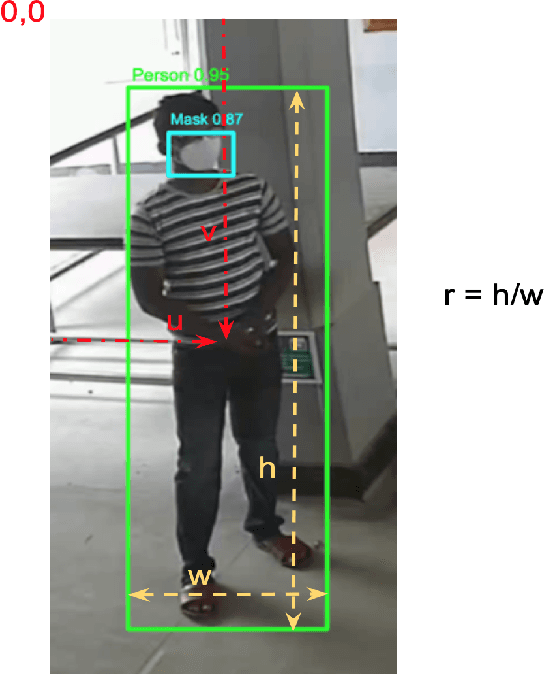

The COVID-19 pandemic has caused an unprecedented global public health crisis. Given its inherent nature, social distancing measures are proposed as the primary strategies to curb the spread of this pandemic. Therefore, identifying situations where these protocols are violated, has implications for curtailing the spread of the disease and promoting a sustainable lifestyle. This paper proposes a novel computer vision-based system to analyze CCTV footage to provide a threat level assessment of COVID-19 spread. The system strives to holistically capture and interpret the information content of CCTV footage spanning multiple frames to recognize instances of various violations of social distancing protocols, across time and space, as well as identification of group behaviors. This functionality is achieved primarily by utilizing a temporal graph-based structure to represent the information of the CCTV footage and a strategy to holistically interpret the graph and quantify the threat level of the given scene. The individual components are tested and validated on a range of scenarios and the complete system is tested against human expert opinion. The results reflect the dependence of the threat level on people, their physical proximity, interactions, protective clothing, and group dynamics. The system performance has an accuracy of 76%, thus enabling a deployable threat monitoring system in cities, to permit normalcy and sustainability in the society.
A generalized forecasting solution to enable future insights of COVID-19 at sub-national level resolutions
Aug 21, 2021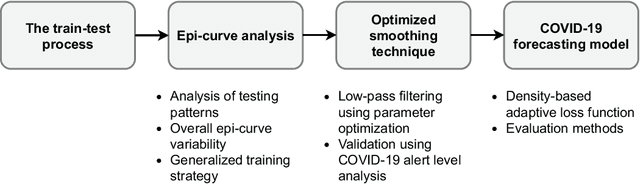
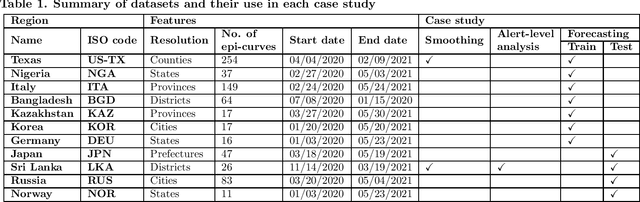
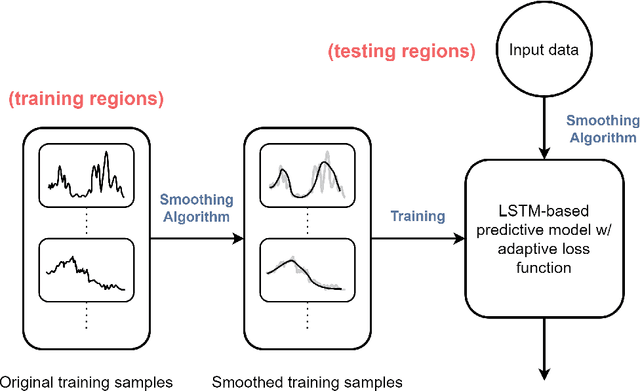
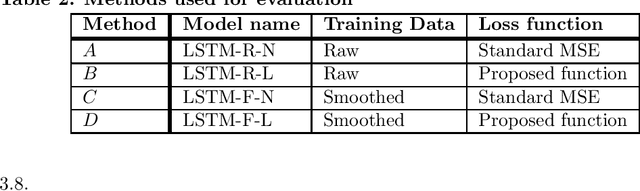
COVID-19 continues to cause a significant impact on public health. To minimize this impact, policy makers undertake containment measures that however, when carried out disproportionately to the actual threat, as a result if errorneous threat assessment, cause undesirable long-term socio-economic complications. In addition, macro-level or national level decision making fails to consider the localized sensitivities in small regions. Hence, the need arises for region-wise threat assessments that provide insights on the behaviour of COVID-19 through time, enabled through accurate forecasts. In this study, a forecasting solution is proposed, to predict daily new cases of COVID-19 in regions small enough where containment measures could be locally implemented, by targeting three main shortcomings that exist in literature; the unreliability of existing data caused by inconsistent testing patterns in smaller regions, weak deploy-ability of forecasting models towards predicting cases in previously unseen regions, and model training biases caused by the imbalanced nature of data in COVID-19 epi-curves. Hence, the contributions of this study are three-fold; an optimized smoothing technique to smoothen less deterministic epi-curves based on epidemiological dynamics of that region, a Long-Short-Term-Memory (LSTM) based forecasting model trained using data from select regions to create a representative and diverse training set that maximizes deploy-ability in regions with lack of historical data, and an adaptive loss function whilst training to mitigate the data imbalances seen in epi-curves. The proposed smoothing technique, the generalized training strategy and the adaptive loss function largely increased the overall accuracy of the forecast, which enables efficient containment measures at a more localized micro-level.